dex文件结构
dex 文件结构
什么是 dex 文件?
能够被 dvm 识别,加载并执行的文件格式
如何生成一个 dex 文件
- IDE 自动生成
- 手动通过
dx命令生成
- 手写调用
javac生成 class 文件
1
javac -target 1.8 -source 1.8 Temp.java
- 调用
dx.bat生成 dex 文件
1
dx --dex --output Temp.dex Temp.class
- 手动运行 dex 文件到手机
- 首先
push要执行的 dex 文件到手机 sdcard
1
adb push Temp.dex /sdcard
- 调用
dalvikvm命令执行
1
2
adb shell
dalvikvm -cp /sdcard/Temp.dex Temp
dalvikvm 命令:dalvikvm -cp <dex文件路径> <执行的类>
dex 文件的作用
记录整个工程中所有类文件的信息
dex 文件格式详解
- 一种 8 位字节的二进制流文件
- 各个数据按顺序紧密的排列,无间隙
- 整个应用中所有 Java 源文件都放在一个 dex 文件中,注意 multidex
dex 文件可以分为 3 个模块,头文件 (header)、索引区 (xxxx_ids)、数据区 (data)。
一、文件头
dex 文件里的 header。除了描述整个.dex 文件的文件分布信息外,包括每一个索引区的大小跟偏移。
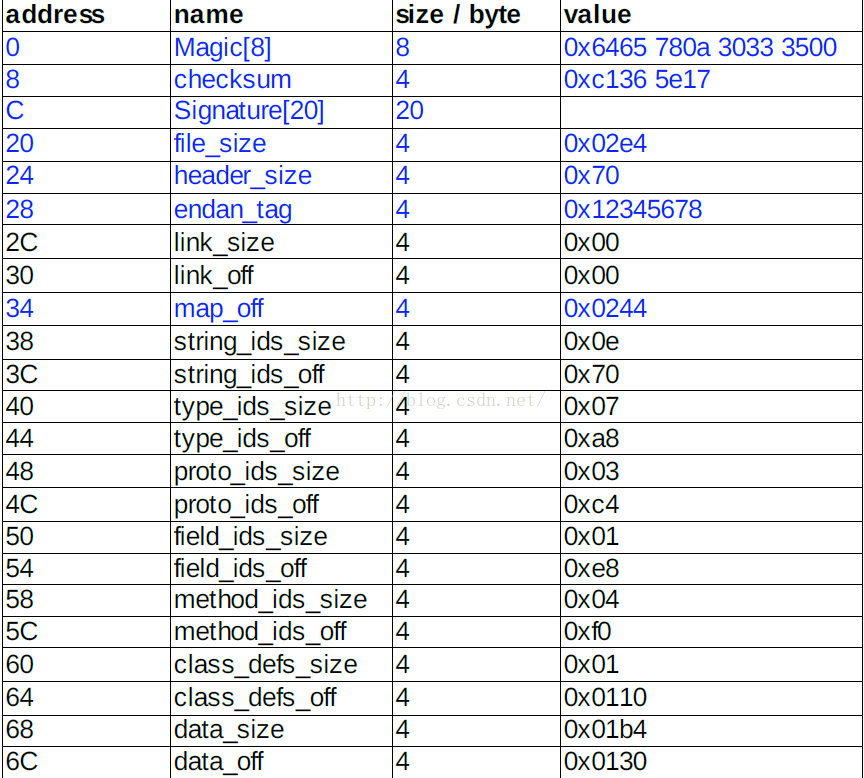
除了 magic、checksum、signature、file_size、endian_tag、map_off 其他元素都是成对出现的。以 _size 和 _off 为后缀的描述:size 都是描述该区里元素的个数;off 描述相对与文件起始位置的偏移量。(data_size 是以 Byte 为单位描述 data 区的大小)。各项说明如下:
- 1、magic
这 8 个字节一般是常量,为了使.dex 文件能够被识别出来,它必须出现在.dex 文件的最开头的位置。转化为字符串为:
1
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex\n035\0"
中间是一个换行,后面 035 是版本号。
- 2、checksum 和 signature
checksum: 文件校验码,使用 alder32 算法校验文件除去 maigc、checksum 外余下的所有文件区域,用于检查文件错误。。
signature: 使用 SHA-1 算法 hash 除去 magic、checksum 和 signature 外余下的所有文件区域, 用于唯一识别本文件 。 - 3、file_size
dex 文件的大小 - 4、header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量。 - 5、endian_tag
大小端标签,标准.dex 文件格式为小端 ,此项一般固定为 0x12345678 常量 。 - 6、link_size 和 link_off
这个两个字段是表示链接数据的大小和偏移值。 - 7、map_off
map item 的偏移地址,该 item 属于 data 区里的内容,值要大于等于 data_off 的大小。 - 8、string_ids_size 和 string_ids_off
这两个字段表示 dex 中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。 - 9、type_ids_size 和 type_ids_off
这两个字段表示 dex 中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息。 - 10、proto_ids_size 和 type_ids_off
这两个字段表示 dex 中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息。 - 11、 field_ids_size 和 field_ids_off
这两个字段表示 dex 中的字段信息数据结构的大小和偏移值。 - 12、method_ids_size 和 method_ids_off
这两个字段表示 dex 中的方法信息数据结构的大小和偏移值 - 13、class_defs_size 和 class_defs_off
这两个字段表示 dex 中的类信息数据结构的大小和偏移值,这个数据结构是整个 dex 中最复杂的数据结构,他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦。 - 14、data_size 和 data_off
这两个字段表示 dex 中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
完整的 header: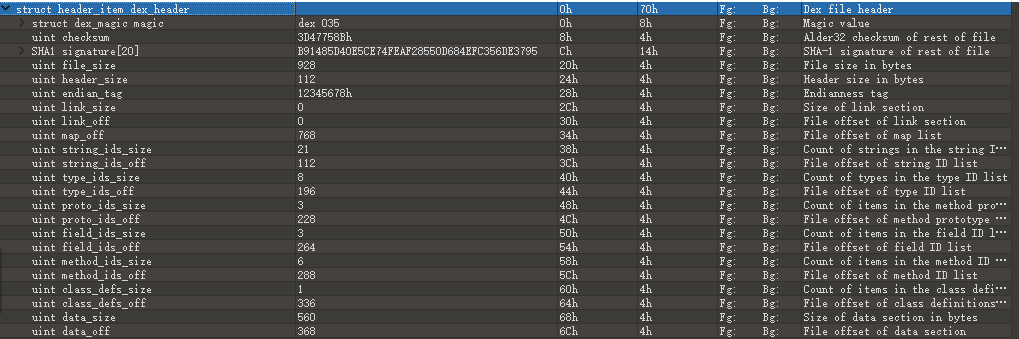
二、索引区
- 1、string_ids
string_ids 区段描述了 dex 文件中所有的字符串。
LEB128 ( little endian base 128 )
基于 1 个 Byte 的一种不定长度的编码方式;若第一个 Byte 的最高位为 1,则表示还需要下一个 Byte 来描述,直至最后一个 Byte 的最高位为 0;每个 Byte 的其余 bit 用来表示数据,如下表所示。实际中 LEB128 最大只能达到 32-bit,可以阅读 dalvik 中的 Leb128.h 源码看出来。
数据结构为:
1
2
3
4
5
6
7
8
9
10
11
12
ubyte 8-bit unsinged int
uint 32-bit unsigned int, little-endian
uleb128 unsigned LEB128, valriable length
struct string_ids_item
{
uint string_data_off;
}
struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}
其中 data 保存的就是字符串的值。string_ids 是比较关键的,后续的区段很多都是直接指向 string_ids 的 index。
- 2、type_ids
type_ids 区索引了 dex 文件里的所有数据类型,包括 class 类型,数组类型 (array types) 和基本类型
(primitive types)。区段里的元素格式为 type_ids_item,结构描述如下 :
1
2
3
4
5
6
uint 32-bit unsigned int, little-endian
struct type_ids_item
{
uint descriptor_idx; //-->string_ids
}
type_ids_item 里面 descriptor_idx 的值的意思,是 string_ids 里的 index 序号,是用来描述此 type 的字符串。
- 3、proto_ids
proto 的意思是 method prototype 代表 java 语言里的一个 method 的原型 。proto_ids 里的元素为 proto_id_item,结构如下:
1
2
3
4
5
6
7
8
uint 32-bit unsigned int, little-endian
struct proto_id_item
{
uint shorty_idx; //-->string_ids
uint return_type_idx; //-->type_ids
uint parameters_off;
}
- shorty_idx: 跟 type_ids 一样,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述,用来说明该 method 原型。
- return_type_idx: 它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型。
- parameters_off: 指向 method 原型的参数列表 type_list,若 method 没有参数,值为 0。参数列表的格式是 type_list,下面会有描述。
- 4、field_ids
filed_ids 区里面有 dex 文件引用的所有的 field。区段的元素格式是 field_id_item,结构如下:
1
2
3
4
5
6
7
8
9
ushort 16-bit unsigned int, little-endian
uint 32-bit unsigned int, little-endian
struct filed_id_item
{
ushort class_idx; //-->type_ids
ushort type_idx; //-->type_ids
uint name_idx; //-->string_ids
}
- class_idx: 表示 field 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。
- type_idx: 表示本 field 的类型,它的值也是 type_ids 的一个 index 。
- name_idx: 表示本 field 的名称,它的值是 string_ids 的一个 index 。
- 5、method_ids
method_ids 是索引区的最后一个条目,描述了 dex 文件里的所有的 method。method_ids 的元素格式是 method_id_item,结构跟 fields_ids 很相似:
1
2
3
4
5
6
7
8
9
ushort 16-bit unsigned int, little-endian
uint 32-bit unsigned int, little-endian
struct filed_id_item
{
ushort class_idx; //-->type_ids
ushort proto_idx; //-->proto_ids
uint name_idx; //-->string_ids
}
- class_idx: 表示 method 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。ushort 类型也是为什么我们说一个 dex 只能有 65535 个方法的原因,多了必须分包。
- proto_idx: 表示 method 的类型,它的值也是 type_ids 的一个 index。
- name_idx: 表示 method 的名称,它的值是 string_ids 的一个 index。
索引区:
三、数据区
1、class_defs
class_defs 区段主要是对 class 的定义,它的结构很复杂,一层套一层。
- 1、class_def_item
class_defs 区域里存放着 class definitions , class 的定义 。它的结构较 dex 区都要复杂些 ,因为有些数据都直接指向了 data 区里面。数据结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
uint 32-bit unsigned int, little-endian
struct class_def_item
{
uint class_idx; //-->type_ids
uint access_flags;
uint superclass_idx; //-->type_ids
uint interface_off; //-->type_list
uint source_file_idx; //-->string_ids
uint annotations_off; //-->annotation_directory_item
uint class_data_off; //-->class_data_item
uint static_value_off; //-->encoded_array_item
}
- class_idx: 描述具体的 class 类型,值是 type_ids 的一个 index 。值必须是一个 class 类型,不能是数组类型或者基本类型。
- access_flags: 描述 class 的访问类型,诸如 public , final , static 等。在 dex-format.html 里 “access_flags Definitions” 有具体的描述 。
- superclass_idx: 描述 supperclass 的类型,值的形式跟 class_idx 一样 。
- interfaces_off: 值为偏移地址,指向 class 的 interfaces,被指向的数据结构为
type_list。class 若没有 interfaces 值为 0。 - source_file_idx: 表示源代码文件的信息,值是 string_ids 的一个 index。若此项信息缺失,此项值赋值为 NO_INDEX=0xffff ffff。
- annotions_off: 值是一个偏移地址,指向的内容是该 class 的注释,位置在 data 区,格式为
annotations_direcotry_item。若没有此项内容,值为 0 。 - class_data_off: 值是一个偏移地址,指向的内容是该 class 的使用到的数据,位置在 data 区,格式为
class_data_item。若没有此项内容值为 0。该结构里有很多内容,详细描述该 class 的 field、method, method 里的执行代码等信息,后面会介绍class_data_item。 - static_value_off: 值是一个偏移地址 ,指向 data 区里的一个列表 (list),格式为
encoded_array_item。若没有此项内容值为 0。 - 1.1 type_list
type_list 在 data 区段,class_def_item->interface_off 就是指的这里的数据。数据结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
uint 32-bit unsigned int, little-endian
struct type_list
{
uint size;
type_item list [size]
}
struct type_item
{
ushort type_idx //-->type_ids
}
- size: 表示类型个数
- type_idx: 对应一个 type_ids 的 index
- 1.2 annotations_directory_item
class_def_item->annotations_off 指向的数据区段,定义了 annotation 相关的数据描述。 - 1.3 class_data_item
class_data_off 指向 data 区里的 class_data_item 结构,class_data_item 里存放着本 class 使用到的各种数据,下面是 class_data_item 的结构 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
uleb128 unsigned little-endian base 128
struct class_data_item
{
uleb128 static_fields_size;
uleb128 instance_fields_size;
uleb128 direct_methods_size;
uleb128 virtual_methods_size;
encoded_field static_fields[static_fields_size];
encoded_field instance_fields[instance_fields_size];
encoded_method direct_methods[direct_methods_size];
encoded_method virtual_methods[virtual_methods_size];
}
struct encoded_field
{
uleb128 filed_idx_diff;
uleb128 access_flags;
}
struct encoded_method
{
uleb128 method_idx_diff;
uleb128 access_flags;
uleb128 code_off;
}
2、map_list
map_list 中大部分 item 跟 header 中的相应描述相同,都是介绍了各个区的偏移和大小,但是 map_list 中描述的更加全面,包括了 HEADER_ITEM 、TYPE_LIST、STRING_DATA_ITEM、DEBUG_INFO_ITEM 等信息。
数据结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ushort 16-bit unsigned int, little-endian
uint 32-bit unsigned int, little-endian
struct map_list
{
uint size;
map_item list [size];
}
struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
}
map_list 里先用一个 uint 描述后面有 size 个 map_item,后续就是对应的 size 个 map_item 描述。
map_item 结构有 4 个元素: type 表示该 map_item 的类型,Dalvik Executable Format 里 Type Code 的定义; size 表示再细分此 item,该类型的个数;offset 是第一个元素的针对文件初始位置的偏移量; unuse 是用对齐字节的,无实际用处。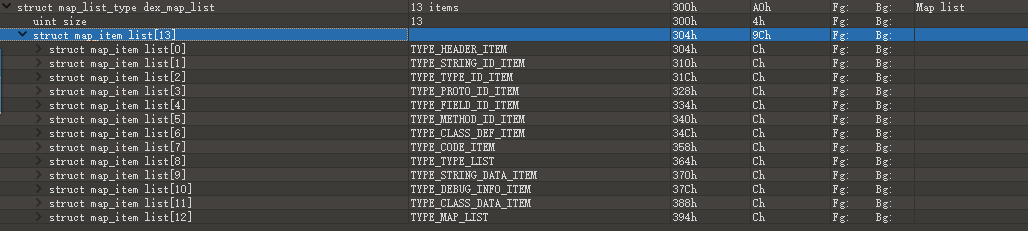
class 和 dex 区别
- class 是 jvm 要执行的文件;dex 是 dvm 要执行的文件;class 可以通过 dex 工具处理成 dex 文件
- class 文件存在很多的冗余信息,dex 工具会去除冗余信息,把所有的 class 文件整合到 dex 文件,减少了 I/O 操作,提高了类的查找速度
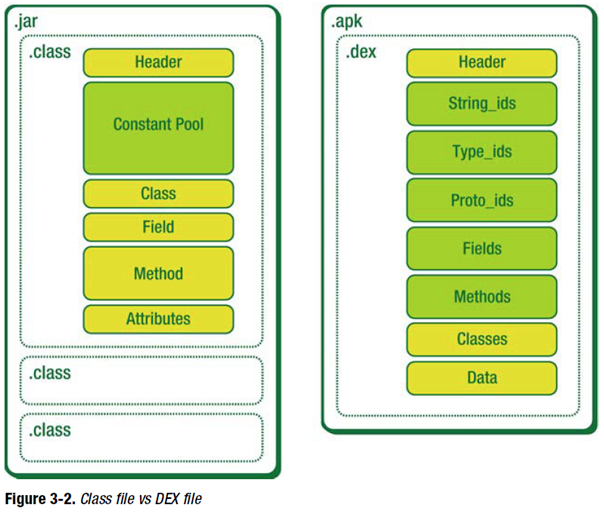
JVM 的数据格式规范和 Class 文件
参考:http://www.importnew.com/16388.html
《Java 虚拟机规范》阅读(三):Class 文件格式
http://www.cnblogs.com/zhuYears/archive/2012/02/07/2340347.html