Node.js基础
Node.js 基础
Node.js 介绍
什么是 Node.js?
简单的说 Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个事件驱动 I/O 服务端 JavaScript 环境,是一个基于 Chrome V8 引擎的 JavaScript 运行环境。,V8 引擎执行 Javascript 的速度非常快,性能非常好。
Node.js 和浏览器对比
- 浏览器是 JS 的运行时环境,替换了 DOM API
- Node.js 是 JS 的运行时环境,脱离了浏览器,没有 DOM API

为什么要学习使用 Node.js?
- 你要用前端框架 CLI 进行开发,需要通过 Node.js 运行
- 你要为业务代码进行单元测试,需要通过 Node.js 运行
- 搭个服务器,搞搞 Serverless
- 写一些 JS 代码来自动化一些日常琐事(比如文件批量重命名)
Node.js 的版本
Node.js 的偶数版本作为 LTS(long-term support,长期维护支持),有 30 个月的生命周期。生产环境应该使用 Active LTS 或 Maintenance LTS 版本。
Node.js 安装
- 下载对应你系统的 Node.js 版本
https://nodejs.org/en/download/。>
- 选安装目录进行安装
- 完成以后,在控制台输入:
node -v
事件驱动 & 非阻塞 I/O
Node 最核心的两个特性:事件驱动、非阻塞 I/O 。
I/O 是一个相对耗时较长的工作,I/O 任务主要由 CPU 分发给 DMA 执行,等待数据库查询结果的时候进程在做什么?大部分时候就是单纯在等着而已
使用了多线程,如果进程不等待 I/O 结果,直接处理后续任务就是非阻塞 I/O,这样可以不用浪费 CPU 。
进程如何获知异步 I/O 调用完成,触发回调函数呢?这就要靠 Event Loop 实现,也就是上面提到的事件驱动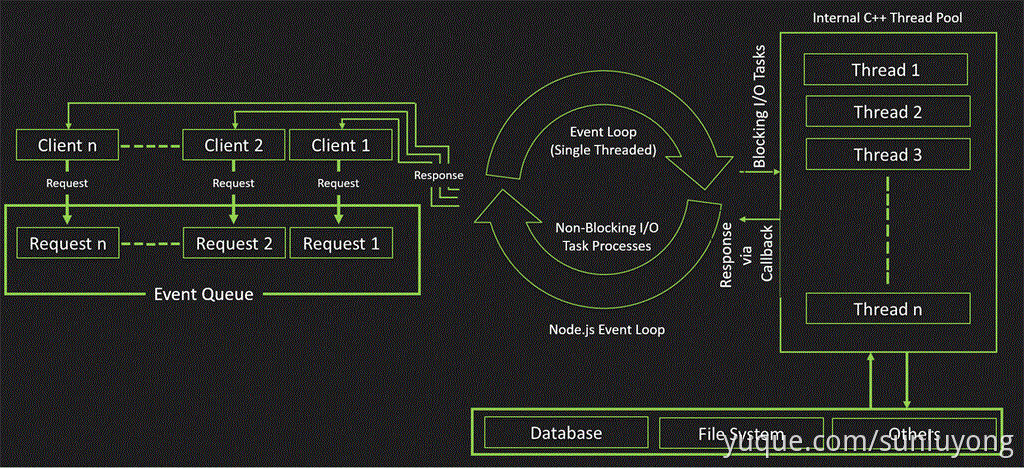
- 在 Node.js 中所有操作称之为事件,客户端的请求也是事件,所有事件维护在图中最左侧的事件队列中
- Node.js 主线程也就是图中间的循环就是 Event Loop,主要作用是轮训事件队列中是否存在事件
- 有非阻塞事件,按照先进先出原则依次调用处理
- 有阻塞事件,交给图中最右侧的 C++ 线程池处理,线程池处理完成后把结果通过 Event Loop 返回给事件队列
- 进行下一次循环
- 一个请求所有事件都被处理,把响应结果发给客户端,完成一次请求
Node.js 全局对象
JavaScript 中有一个特殊的对象,称为全局对象(Global Object),它及其所有属性都可以在程序的任何地方访问,即全局变量。
在浏览器 JavaScript 中,通常 window 是全局对象, 而 Node.js 中的全局对象是 global,所有全局变量(除了 global 本身以外)都是 global 对象的属性。
在 Node.js 我们可以直接访问到 global 的属性,而不需要在应用中包含它。
__filename
__filename 表示当前正在执行的脚本的文件名。它将输出文件所在位置的绝对路径,且和命令行参数所指定的文件名不一定相同。 如果在模块中,返回的值是模块文件的路径
__dirname
__dirname 表示当前执行脚本所在的目录。
setTimeout(cb, ms)
setTimeout(cb, ms) 全局函数在指定的毫秒 (ms) 数后执行指定函数 (cb)。:setTimeout() 只执行一次指定函数。
返回一个代表定时器的句柄值。
clearTimeout(t)
clearTimeout( t ) 全局函数用于停止一个之前通过 setTimeout() 创建的定时器。 参数 t 是通过 setTimeout() 函数创建的定时器。
1
2
3
4
5
6
7
8
function printHello(){
console.log( "Hello, World!");
}
// 两秒后执行以上函数
var t = setTimeout(printHello, 2000);
// 清除定时器
clearTimeout(t);
setInterval(cb, ms)
etInterval(cb, ms) 全局函数在指定的毫秒 (ms) 数后执行指定函数 (cb)。
返回一个代表定时器的句柄值。可以使用 clearInterval(t) 函数来清除定时器。
setInterval() 方法会不停地调用函数,直到 clearInterval() 被调用或窗口被关闭。
1
2
3
4
5
function printHello(){
console.log( "Hello, World!");
}
// 两秒后执行以上函数
setInterval(printHello, 2000);
console(xxx)
console 用于提供控制台标准输出,它是由 Internet Explorer 的 JScript 引擎提供的调试工具,后来逐渐成为浏览器的实施标准。
Node.js 沿用了这个标准,提供与习惯行为一致的 console 对象,用于向标准输出流(stdout)或标准错误流(stderr)输出字符。
process 全局变量
process 是一个全局变量,即 global 对象的属性。
它用于描述当前 Node.js 进程状态的对象,提供了一个与操作系统的简单接口。
| 序号 | 事件 & 描述 |
|---|---|
| 1 | exit 当进程准备退出时触发。 |
| 2 | beforeExit 当 node 清空事件循环,并且没有其他安排时触发这个事件。通常来说,当没有进程安排时 node 退出,但是 ‘beforeExit’ 的监听器可以异步调用,这样 node 就会继续执行。 |
| 3 | uncaughtException 当一个异常冒泡回到事件循环,触发这个事件。如果给异常添加了监视器,默认的操作(打印堆栈跟踪信息并退出)就不会发生。 |
| 4 | Signal 事件 当进程接收到信号时就触发。信号列表详见标准的 POSIX 信号名,如 SIGINT、SIGUSR1 等。 |
Process 属性
Process 提供了很多有用的属性,便于我们更好的控制系统的交互:
| 序号. | 属性 & 描述 |
|---|---|
| 1 | stdout 标准输出流。 |
| 2 | stderr 标准错误流。 |
| 3 | stdin 标准输入流。 |
| 4 | argv argv 属性返回一个数组,由命令行执行脚本时的各个参数组成。它的第一个成员总是 node,第二个成员是脚本文件名,其余成员是脚本文件的参数。 |
| 5 | execPath 返回执行当前脚本的 Node 二进制文件的绝对路径。 |
| 6 | execArgv 返回一个数组,成员是命令行下执行脚本时,在 Node 可执行文件与脚本文件之间的命令行参数。 |
| 7 | env 返回一个对象,成员为当前 shell 的环境变量 |
| 8 | exitCode 进程退出时的代码,如果进程优通过 process.exit() 退出,不需要指定退出码。 |
| 9 | version Node 的版本,比如 v0.10.18。 |
| 10 | versions 一个属性,包含了 node 的版本和依赖. |
| 11 | config 一个包含用来编译当前 node 执行文件的 javascript 配置选项的对象。它与运行 ./configure 脚本生成的 “config.gypi” 文件相同。 |
| 12 | pid 当前进程的进程号。 |
| 13 | title 进程名,默认值为 “node”,可以自定义该值。 |
| 14 | arch 当前 CPU 的架构:’arm’、’ia32’ 或者 ‘x64’。 |
| 15 | platform 运行程序所在的平台系统 ‘darwin’, ‘freebsd’, ‘linux’, ‘sunos’ 或 ‘win32’ |
| 16 | mainModule require.main 的备选方法。不同点,如果主模块在运行时改变,require.main 可能会继续返回老的模块。可以认为,这两者引用了同一个模块。 |
Process 方法
| 序号 | 方法 & 描述 |
|---|---|
| 1 | abort() 这将导致 node 触发 abort 事件。会让 node 退出并生成一个核心文件。 |
| 2 | chdir(directory) 改变当前工作进程的目录,如果操作失败抛出异常。 |
| 3 | cwd() 返回当前进程的工作目录 |
| 4 | exit([code]) 使用指定的 code 结束进程。如果忽略,将会使用 code 0。 |
| 5 | getgid() 获取进程的群组标识(参见 getgid(2))。获取到的是群组的数字 id,而不是名字。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 6 | setgid(id) 设置进程的群组标识(参见 setgid(2))。可以接收数字 ID 或者群组名。如果指定了群组名,会阻塞等待解析为数字 ID 。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 7 | getuid() 获取进程的用户标识 (参见 getuid(2))。这是数字的用户 id,不是用户名。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 8 | setuid(id) 设置进程的用户标识(参见 setuid(2))。接收数字 ID 或字符串名字。如果指定了群组名,会阻塞等待解析为数字 ID 。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 9 | getgroups() 返回进程的群组 ID 数组。POSIX 系统没有保证一定有,但是 node.js 保证有。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 10 | setgroups(groups) 设置进程的群组 ID。这是授权操作,所以你需要有 root 权限,或者有 CAP_SETGID 能力。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 11 | initgroups(user, extra_group) 读取 /etc/group ,并初始化群组访问列表,使用成员所在的所有群组。这是授权操作,所以你需要有 root 权限,或者有 CAP_SETGID 能力。 注意:这个函数仅在 POSIX 平台上可用 (例如,非 Windows 和 Android)。 |
| 12 | kill(pid[, signal]) 发送信号给进程. pid 是进程 id,并且 signal 是发送的信号的字符串描述。信号名是字符串,比如 ‘SIGINT’ 或 ‘SIGHUP’。如果忽略,信号会是 ‘SIGTERM’。 |
| 13 | memoryUsage() 返回一个对象,描述了 Node 进程所用的内存状况,单位为字节。 |
| 14 | nextTick(callback) 一旦当前事件循环结束,调用回调函数。 |
| 15 | umask([mask]) 设置或读取进程文件的掩码。子进程从父进程继承掩码。如果 mask 参数有效,返回旧的掩码。否则,返回当前掩码。 |
| 16 | uptime() 返回 Node 已经运行的秒数。 |
| 17 | hrtime() 返回当前进程的高分辨时间,形式为 [seconds, nanoseconds] 数组。它是相对于过去的任意事件。该值与日期无关,因此不受时钟漂移的影响。主要用途是可以通过精确的时间间隔,来衡量程序的性能。 你可以将之前的结果传递给当前的 process.hrtime() ,会返回两者间的时间差,用来基准和测量时间间隔。 |
module 模块
Node.js 用的是 CommonJs,浏览器用的 EsModule
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在 Node 环境中,一个 .js 文件就称之为一个模块(module)
一个模块想要对外暴露变量(函数也是变量),可以用 module.exports = variable;,一个模块要引用其他模块暴露的变量,用 var ref = require('module_name'); 就拿到了引用模块的变量。输出的变量可以是任意对象、函数、数组等等
- hello.js
1
2
3
4
5
6
7
8
9
'use strict';
var s = 'Hello';
function greet(name) {
console.log(s + ', ' + name + '!');
}
module.exports = greet;
- main.js
1
2
3
4
5
6
'use strict';
var greet = require("./hello");
var name = 'Michael';
greet(name); // Hello, Michael!
在使用 require() 引入模块的时候,请注意模块的相对路径。因为 main.js 和 hello.js 位于同一个目录,所以我们用了当前目录.:
1
var greet = require('./hello'); // 不要忘了写相对目录!
如果只写模块名:
1
var greet = require('hello');
则 Node 会依次在 内置模块、全局模块 和 当前模块 下查找 hello.js。
这种模块加载机制被称为 CommonJS 规范。在这个规范下,每个 .js 文件都是一个模块,它们内部各自使用的变量名和函数名都互不冲突
模块的分类
Node.js 中根据模块来源的不同,将模块分为了 3 大类,分别是:
- 内置模块(内置模块是由 Node.js 官方提供的,例如 fs、path、http 等)
- 自定义模块(用户创建的每个.js 文件,都是自定义模块)
- 第三方模块(由第三方开发出来的模块,并非官方提供的内置模块,也不是用户创建的自定义模块,使用前需要先下载
不同模块使用相同变量名原理
JavaScript 语言本身并没有一种模块机制来保证不同模块可以使用相同的变量名,不同文件的相同变量赋值会互相影响。
Node.js 也并不会增加任何 JavaScript 语法。实现 “ 模块 “ 功能的奥妙就在于 JavaScript 是一种函数式编程语言,它支持闭包。如果我们把一段 JavaScript 代码用一个函数包装起来,这段代码的所有 “ 全局 “ 变量就变成了函数内部的局部变量。
我们编写的 hello.js 代码是这样的:
1
2
3
4
var s = 'Hello';
var name = 'world';
console.log(s + ' ' + name + '!');
Node.js 加载了 hello.js 后,它可以把代码包装一下,变成这样执行:
1
2
3
4
5
6
7
8
(function () {
// 读取的hello.js代码:
var s = 'Hello';
var name = 'world';
console.log(s + ' ' + name + '!');
// hello.js代码结束
})();
这样一来,原来的全局变量 s 现在变成了匿名函数内部的局部变量。如果 Node.js 继续加载其他模块,这些模块中定义的 “ 全局 “ 变量 s 也互不干扰。
所以,Node 利用 JavaScript 的函数式编程的特性,轻而易举地实现了模块的隔离。
模块的输出 module.exports 实现原理
https://juejin.cn/post/7175820285176709175#heading-14
module 对象
在每个 .js 自定义模块中都有一个 module 对象,它里面存储了和当前模块有关的信息
module.exports 对象
在自定义模块中, 可以使用 module.exports 对象将模块的成员共享出去,供其他模块使用;其他模块用 require() 方法导入自定义模块时,得到的就是 module.exports 所指向的对象。
Node 可以先准备一个对象 module:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 准备module对象:
var module = {
id: 'hello',
exports: {}
};
var load = function (module) {
// 读取的hello.js代码:
function greet(name) {
console.log('Hello, ' + name + '!');
}
module.exports = greet;
// hello.js代码结束
return module.exports;
};
var exported = load(module);
// 保存module:
save(module, exported);
变量 module 是 Node 在加载 js 文件前准备的一个变量,并将其传入加载函数,我们在 hello.js 中可以直接使用变量 module 原因就在于它实际上是函数的一个参数:
1
module.exports = greet;
通过把参数 module 传递给 load() 函数,hello.js 就顺利地把一个变量传递给了 Node 执行环境,Node 会把 module 变量保存到某个地方。
由于 Node 保存了所有导入的 module,当我们用 require() 获取 module 时,Node 找到对应的 module,把这个 module 的 exports 变量返回,这样,另一个模块就顺利拿到了模块的输出:
1
var greet = require('./hello');
module 的加载机制
优先从模块中的缓冲
模块在第一次加载后会被缓存,多次调用 require() 不会导致模块代码被执行多次。
不论是内置模块、用户自定义模块、还是第三方模块,它们都会优先从缓存中加载,从而提高模块的加载效率
内置模块的加载机制
内置模块由 Node.js 官方提供的模块,内置模块的加载优先级最高
require(‘fs’),即使在
node_modules目录下有名字相同的包叫 fs,也是返回的内置的 fs 模块
自定义模块的加载机制
使用 require 加载自定义模块时,必须指定以 ./ 或 ../ 开头的路径标识符,在加载自定义模块时,如果没有指定 ./ 或 ../ 这样的路径标识符,Node 会把它当做内置模块或第三方模块进行加载
同时,使用 require 导入自定义模块时,如果省略了文件的扩展名,则 Node.js 会按顺序分别尝试加载以下的文件:
- 按照确切的文件名进行加载
- 补全
.js扩展名进行加载 - 补全
.json扩展名进行加载 - 补全
.node扩展名进行加载 - 加载失败,终端报错
第三方模块的加载机制
如果传递给 require 的模块标识符不是一个内置模块,也没有以 ./ 或 ../ 开头,则 Node.js 会从当前模块的父目录开始,尝试从 /node_modules 文件夹中加载第三方模块;如果没有找到对应的第三方模块,则移动到再上一层父目录中进行加载,直到文件系统的根目录。
示例
加载一个 ws 模块
ws.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
const ws = require("nodejs-websocket");
const os = require("os");
const PORT = 8080;
const getLocalIP = () => {
const interfaces = os.networkInterfaces();
const addresses = [];
for (let k in interfaces) {
for (let k2 in interfaces[k]) {
const address = interfaces[k][k2];
if (address.family === "IPv4" && !address.internal) {
addresses.push(address.address);
}
}
}
return addresses;
};
function init() {
const server = ws.createServer((connect) => {
connect.on("text", (data) => {
console.log("received: " + data);
connect.sendText(data);
});
connect.on("close", (code, reason) => {
console.log("connection closed!");
});
connect.on("error", () => {
console.log("connection error!$port ");
});
});
server.listen(PORT, () => {
getLocalIP().forEach((ip) => {
console.log(`http://${ip}:${PORT}`);
});
console.log(`WebSocket server listening on ws://${getLocalIP()[0]}:${PORT}`);
// 这里输出您监听的WebSocket地址
});
}
module.exports = {
init,
};
ws.js 用的 CommonJs 暴露出了一个 init 方法
server.js引入
1
2
3
// WebSocket
const ws = require("./ws/ws.js")
ws.init();