Java String相关问题
Java String 相关问题
String 是 Java 中的基本数据类型吗?是可变的吗?是线程安全的吗?
- String 不是基本数据类型,Java 中的基本数据类型是:byte, short, int, long, char, float, double, boolean
- String 是不可变的。
- String 是不可变类,⼀旦创建了 String 对象,我们就⽆法改变它的值,因此,它是线程安全的,可以安全地⽤于多线程环境中。
为什么要设计成不可变的呢?如果 String 是不可变的,那我们平时赋值是改的什么呢?
- 安全
由于 String 广泛用于 Java 类中的参数,安全是非常重要的,如网络 URL,数据库 URL、打开文件等。
如果 String 是可变的,将导致严重的安全威胁,有人可以访问他有权授权的任何文件,然后可以故意更改文件名来获得该文件的访问权限。
- 效率
String 会缓存其哈希码 (就是 hash 字段),由于 String 的不可变性,不会在每次调用 String 的 hashcode 方法时重新计算,这使得它在 Java 中的 HashMap 中使用的 HashMap 键非常快。
- 空间
不同的字符串变量可以引用字符串池中相同的字符串,可以节省大量的 Java 堆空间;如果字符串可变的话,任何一个变量值的改变都会让反馈到其他变量,字符串池就没有任何意义了
平时使⽤双引号⽅式赋值的时候其实是返回的字符串引⽤,并不是改变了这个字符串对象,
1
2
String a = "aaa";
a = "axx"; // 只是将a的引用更改了,引用到了"axx"字符串对象;"aaa"和"axx"都是字符串池中的对象
String、StringBuilder 和 StringBuffer 及原理?
区别
- String 是不可变类,每当我们对 String 进⾏操作的时候,总是会创建新的字符串。操作 String 很耗资源,所以 Java 提供了两个⼯具类来操作 String:StringBuffer 和 StringBuilder。
- StringBuffer 和 StringBuilder 是可变类, 字符串缓冲区,可以提高字符串的效率,StringBuffer 是线程安全的,StringBuilder 则不是线程安全的。所以在多线程对同⼀个字符串操作的时候,我们应该选择⽤ StringBuffer。由于不需要处理多线程的情况,StringBuilder 的效率⽐ StringBuffer ⾼。
原理
- String 的底层是一个 fianl char 数组,不可变;JDK 9 之后改成 byte 数组了,节省内存?
- StringBuilder 底层也是一个 char 数组,可变,默认容量 16,会自动扩容,线程不安全
- StringBuffer 底层同 StringBuilder,在操作字符串的方式上加了同步锁 synchronized,如 append

使用总结
- 如果要操作少量的数据用 String
- 单线程操作字符串缓冲区下操作⼤量数据⽤ StringBuilder
- 多线程操作字符串缓冲区下操作⼤量数据⽤ StringBuffer
1 个字符的 String.length () 是多少?一定是为 1 吗?
1 个字符的 length () 不一定都为 1。
String.length () 代表的意思?
返回字符串的长度,这一长度等于字符串中的 Unicode 代码单元的数目
统计字符串有几个字符怎么统计?
用 String.codePointCount (int beginIndex, int endIndex)
1
2
3
4
5
6
7
public static void main(String[] args) {
String B = "𝄞"; // 这个就是那个音符字符,只不过由于当前的网页没支持这种编码,所以没显示。
String C = "\uD834\uDD1E"; // 这个就是音符字符的UTF-16编码
System.out.println(C);
System.out.println(B.length()); // 2
System.out.println(B.codePointCount(0, B.length())); // 1
}
字符串常量池中存放的是对象?还是对象的引用?
JDK 版本不同,字符串常量池的位置不一样,里面存放的内容也不同。JDK 1.6 及之前的版本,常量池是在 Perm 区的,则字符串字面量的对象是直接存放在常量池中的;而 JDK 1.7 及之后的版本,常量池中存放的是对象的引用(避免对象多次创建)。
深入解析String#intern
Java String 可以有多长?
Java String 字⾯量形式
- 字节码中CONSTANT_Utf 8_info的限制,最多 65535 个字节
- Javac 源码逻辑的限制 <=65535
- ⽅法区⼤⼩的限制(如果运⾏时⽅法区设置较⼩,也会受到⽅法区⼤⼩的限制 )
Java String 运⾏时创建在堆上的形式
- Java 虚拟机指令 newarray 的限制
- Java 虚拟机堆内存⼤⼩的限制
字符串对象创建相关题
String 两种创建方式
字面量形式
当一个.java 文件被编译成.class 文件时,和所有其他常量一样,每个字符串字面量都通过一种特殊的方式被记录下来。当一个.class 文件被加载时,JVM 在. class 文件中寻找字符串字面量。当找到一个时,JVM 会检查是否有相等的字符串在常量池中存放了堆中引用。如果找不到,就会在堆中创建一个对象,然后将它的引用存放在常量池中的一个常量表中。一旦一个字符串对象的引用在常量池中被创建,这个字符串在程序中的所有字面量引用都会被常量池中已经存在的那个引用代替。
1
2
3
String s = "zzc";
String s2 = "zzc";
System.out.println(s == s2); // true
- JVM 检测这个字面量 “zzc”,这里我们认为没有内容为 “zzc” 的对象存在。JVM 通过字符串常量池查找不到内容为 “zzc” 的字符串对象,那么就会在堆中创建这个字符串对象,然后将刚创建的对象的引用放入到字符串常量池中, 并且将引用返回给变量 s。
- 同样 JVM 还是要检测这个字面量,JVM 通过查找字符串常量池,发现内容为 “zzc” 字符串对象存在,于是将已经存在的字符串对象的引用返回给变量 s2。注意,这里并不会重新创建新的字符串对象。
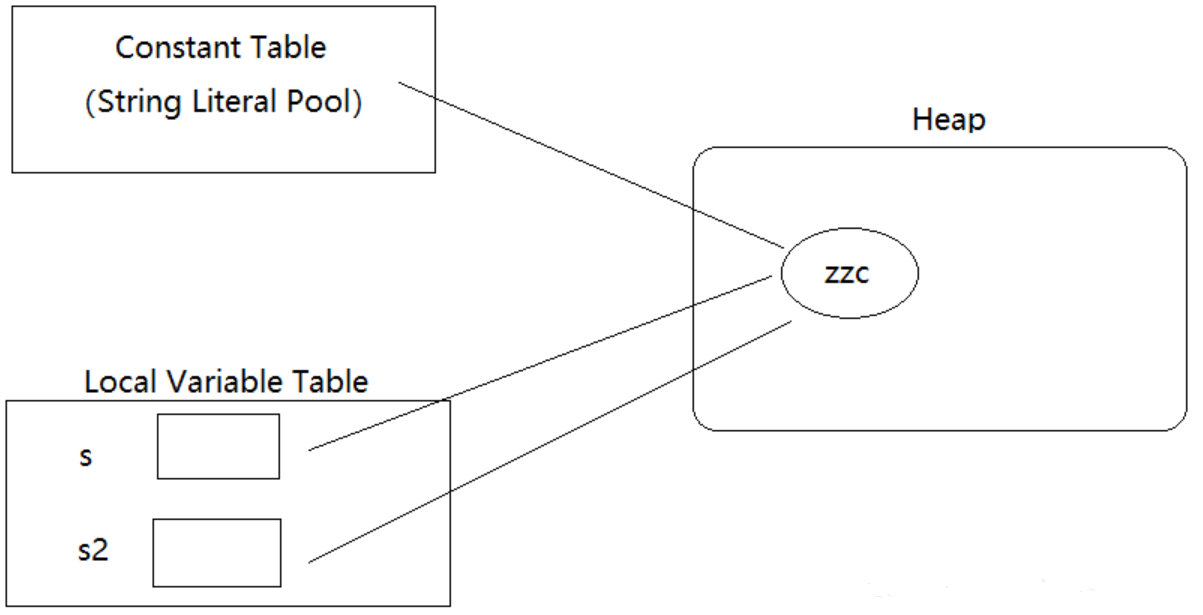
new 形式
new 关键字创建时,前面的操作和字面量创建一样,只不过最后在运行时会创建一个新对象,变量所引用的都是这个新对象的地址。
1
2
3
String s = "zzc";
String s2 = new String("zzc");
System.out.println(s == s2); // false
两个字符串字面量仍然被放进了常量池的常量表中,但是当使用 “new” 时,JVM 就会在运行时创建一个新对象,而不是使用常量表中的引用
要记住引用到常量池的字符串对象是在类加载的时候创建的,而另一个对象是在运行时,当 “new String” 语句被执行时。
intern ()
调用 intern() 后,首先检查字符串常量池中是否有该对象的引用,如果存在,则将这个引用返回给变量,否则将引用加入字符串池并返回给变量。
String s 1 = new String (“hello”); 这句话创建了几个字符串对象?
1 个或 2 个
情况 1:hello 字符串未存在于字符串常量池中
1
2
3
4
5
6
7
8
9
10
11
12
13
String s1 = new String("hello");// 堆内存的地址值
String s2 = "hello";
System.out.println(s1 == s2);// 输出false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
System.out.println(s1.equals(s2));// 输出true
System.out.printf("s1: %d | %d\n", identityHashCode(s1), identityHashCode(s1.intern()));
System.out.printf("s2: %d | %d\n", identityHashCode(s2), identityHashCode(s2.intern()));
// 输出
// false
// true
// s1: 2018699554 | 1311053135
// s2: 1311053135 | 1311053135
这种情况总共创建 2 个字符串对象:
- 常量池 “hello” 对象 1311053135
- new String 对象 2018699554
情况 2:hello 字符串已经存在于字符串常量池中
1
2
3
4
5
6
7
8
9
10
11
12
String s2 = "hello";
String s1 = new String("hello");// 堆内存的地址值
System.out.println(s1 == s2);// 输出false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
System.out.println(s1.equals(s2));// 输出true
System.out.printf("s1: %d | %d\n", identityHashCode(s1), identityHashCode(s1.intern()));
System.out.printf("s2: %d | %d\n", identityHashCode(s2), identityHashCode(s2.intern()));
// 输出
// false
// true
// s1: 2133927002 | 1311053135
// s2: 1311053135 | 1311053135
这种情况就只创建一个对象 new String,因为 s 2 指向的 hello 字符串已经在常量池了
String str =”abc”+”def”; 创建几个对象?假设字符串常量池中都不存在对应的字符串 abc 和 def
1 个。
在编译时已经被合并成 “abcdef” 字符串,因此,只会创建 1 个对象。并没有创建临时字符串对象 abc 和 def,这样减轻了垃圾收集器的压力。
字符串常量重载 “+” 的问题,当一个字符串由多个字符串常量拼接成一个字符串时,它自己也肯定是字符串常量。字符串常量的 “+” 号连接 Java 虚拟机会在程序编译期将其优化为连接后的值。
String str =”abc”+newString (“def”); 创建几个对象?
4+1 = 5 个对象
- 4 个对象:常量池中分别有 “abc” 和 “def”,堆中对象 new String (“def”) 和 “abcdef”
- 1 个 StringBuilder 对象
上述的代码 Java 虚拟机在编译的时候同样会优化,会创建一个 StringBuilder 来进行字符串的拼接,实际效果类似:
1
2
String s = new String("def");
new StringBuilder().append("abc").append(s).toString();
final 对 String 的影响
1
2
3
4
5
6
7
8
9
10
11
String str1 = "hello";
String str2 = "world";
//常量池中的对象
String str3 = "hello" + "world";
//在堆上创建的新的对象
String str4 = str1 + str2;
//常量池中的对象
String str5 = "helloworld";
System.out.println(str3 == str4); // false
System.out.println(str3 == str5); // true
System.out.println(str4 == str5); // false
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 常量池中的对象
final String str1 = "hello";
final String str2 = "world";
String str3 = "hello" + "world";
// 在堆上创建的新的对象
final String str4 = str1 + str2;
// 常量池中的对象
String str5 = "helloworld";
System.out.println(str3 == str4); // true
System.out.println(str3 == str5); // true
System.out.println(str4 == str5); // true
未加 final 前,str 4 计算 str 1 和 str 2 时,会在堆上生成新的对象;加了 final 后,就知道都是常量了,引用的就是常量池的了
String 测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
// String ==和equals测试
String str1 = "hacket";
String str2 = new String("hacket");
System.out.println(str1 == str2); // false
System.out.println(str1.equals(str2)); // true
// String intern测试
String str2 = new String("hacket");
String str3 = str2.intern();
System.out.println(str1 == str3); // true
String s1 = new String("a") + new String("bc");
s1.intern();
String s2 = "abc";
System.out.println(s1 == s2); // true
// final对String的影响
private static void test1() {
// 常量池中的对象
final String str1 = "hello";
final String str2 = "world";
String str3 = "hello" + "world";
// 在堆上创建的新的对象
String str4 = str1 + str2;
// 常量池中的对象
String str5 = "helloworld";
System.out.println(str3 == str4); // true
System.out.println(str3 == str5); // true
System.out.println(str4 == str5); // true
}
private static void test1() {
// 常量池中的对象
String str1 = "hello";
String str2 = "world";
String str3 = "hello" + "world";
// 在堆上创建的新的对象
String str4 = str1 + str2;
// 常量池中的对象
String str5 = "helloworld";
System.out.println(str3 == str4); // false
System.out.println(str3 == str5); // true
System.out.println(str4 == str5); // false
}
private static void test3() {
// str1指的是字符串常量池中的 java6
String str1 = "java6";
// str2是 final 修饰的,编译时候就已经确定了它的确定值,编译期常量
final String str2 = "java";
// str3是指向常量池中 java
String str3 = "java";
// str2编译的时候已经知道是常量,"6"也是常量,所以计算str4的时候,直接相当于使用 str2 的原始值(java)来进行计算.
// 则str4 生成的也是一个常量,。str1和str4都对应 常量池中只生成唯一的一个 java6 字符串。
String str4 = str2 + "6";
// 计算 str5 的时候,str3不是final修饰,不会提前知道 str3的值是什么,只有在运行通过链接来访问,这种计算会在堆上生成 java6
String str5 = str3 + "6";
System.out.println((str1 == str4)); // true
System.out.println((str1 == str5)); // false
}
// intern测试
private static void test2() {
// 同时生成堆中的对象以及常量池中hello的对象,此时str1是指向堆中的对象的
String str1 = new String("hello");
// 常量池中的已经存在hello
str1.intern();
// 常量池中的对象,此时str2是指向常量池中的对象的
String str2 = "hello";
System.out.println(str1 == str2); // false,str1.intern之前已经存在字符串池,返回的是之前new的引用
// 此时生成了四个对象 常量池中的"world" + 2个堆中的"world" +s3指向的堆中的对象(注此时常量池不会生成"worldworld")
String str3 = new String("world") + new String("world");
// 常量池没有“worldworld”,会直接将str3的地址存储在常量池内
str3.intern();
// 创建str4的时候,发现字符串常量池已经存在一个指向堆中该字面量的引用,则返回这个引用,而这个引用就是str3
String str4 = "worldworld";
System.out.println(str3 == str4); // true
}
String 的 hashCode() 为什么乘以 31?
为什么乘以 31?
- 是为了更好的分散哈希码,减少冲突
为什么 31 能减少冲突?
- 因为 31 是素数,计算出来的 hash 值,冲突少
Android 中 String 的 hashCode()
- Android String 的 hashCode() 和 Java 中的 hashCode() 有点差异 Android在早期的版本中,Android 曾经使用与 JDK 类似的算法,但后来为了性能优化,改为直接使用
StringUTF16.hashCode()或StringLatin1.hashCode(),根据字符串的编码方式选择不同的哈希算法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// String.java
// Android API34
/** Cache the hash code for the string */
private int hash; // Default to 0 // 声明一个私有整型变量 `hash`,用于缓存字符串的哈希码。默认值为 0。
public int hashCode() { // 方法的声明,返回一个整型值,表示字符串的哈希码。
int h = hash; // 将缓存的哈希码赋值给局部变量 h,提高效率。
// BEGIN Android-changed: Implement in terms of charAt().
/*
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
*/
final int len = length(); // 获取字符串的长度,并存储在常量 `len` 中。
if (h == 0 && len > 0) { // 判断缓存的哈希码是否为 0 且字符串长度大于 0。如果满足条件,则说明需要计算哈希码。
for (int i = 0; i < len; i++) { // 循环遍历字符串中的每个字符,根据以下公式计算哈希码:
h = 31 * h + charAt(i);
}
hash = h; // 将计算得到的哈希码存储到 `hash` 变量中,以便下次直接使用。
// END Android-changed: Implement in terms of charAt().
}
return h; // 返回计算得到的哈希码。
}
计算 hash 的核心逻辑
1
h = 31 * h + charAt(i);
h 是当前的哈希值,charAt(i) 是字符串中第 i 个字符的 ASCII 值。乘以 31 是为了更好地分散哈希码,减少冲突。
这段代码实际上是用来计算字符串哈希值的经典算法,它背后的公式就是你提到的:
s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
h = 31 * h + charAt(i); 这行代码是核心,它实现了公式的递推计算:
- 第一次循环:
h = 31 * 0 + s[0] = s[0] - 第二次循环:
h = 31 * s[0] + s[1] - 第三次循环:
h = 31 * (31 * s[0] + s[1]) + s[2] = s[0]*31^2 + s[1]*31^1 + s[2] - …
- 第 n 次循环:
h = s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
JDK 中 String 的 hashCode()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
// JDK 17
/** Cache the hash code for the string */
private int hash; // Default to 0
/**
* Cache if the hash has been calculated as actually being zero, enabling * us to avoid recalculating this. */
private boolean hashIsZero; // Default to false;
public int hashCode() {
// The hash or hashIsZero fields are subject to a benign data race,
// making it crucial to ensure that any observable result of the
// calculation in this method stays correct under any possible read of
// these fields. Necessary restrictions to allow this to be correct
// without explicit memory fences or similar concurrency primitives is
// that we can ever only write to one of these two fields for a given
// String instance, and that the computation is idempotent and derived
// from immutable state
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}
boolean isLatin1() {
return COMPACT_STRINGS && coder == LATIN1;
}
// StringLatin1.java
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
// StringUTF16.java
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}
hashCode() 方法设计
- 缓存: String 类使用缓存来避免每次都重新计算哈希码。
hash字段存储已计算的哈希码。hashIsZero用于区分计算出的哈希值为 0 和尚未计算哈希码的情况。 - 延迟初始化: 哈希码只在第一次需要时才计算。这是一种性能优化策略。
- Latin1 vs. UTF16:
isLatin1()方法检查字符串是否可以使用 Latin1 字符编码表示。如果可以,则使用StringLatin1.hashCode()进行计算,以提高效率。否则,使用StringUTF16.hashCode()。这是根据字符串内容进行内部优化。 hash和hashIsZero上的数据竞争: 代码明确指出在hash和hashIsZero字段上存在 “ 良性 “ 数据竞争。这意味着多个线程可能同时尝试读取和/或写入这些字段。- 为什么是 “ 良性 “ 的? 注释解释了原因。数据竞争被认为是安全的,因为:
- 单次写入: 对于每个 String 实例,
hash(或hashIsZero)字段只能被写入一次。计算出哈希码后,它对于该 String 实例就是不可变的。 - 幂等计算: 哈希码的计算是幂等的。这意味着如果多次执行计算,结果将始终相同(假设字符串本身没有改变)。这是因为计算基于字符串的不可变
value。 - 不可变状态: 字符串的字符数据(
value)本身是不可变的。这一点至关重要。
- 单次写入: 对于每个 String 实例,
线程安全的关键设计
- 幂等性 (Idempotent)
- 无论多少次计算,结果始终相同。
- 即使多个线程同时触发计算,最终得到的
h是相同的。
- 单次写入: 对于每个 String 实例,
hash(或hashIsZero)字段只能被写入一次。计算出哈希码后,由于缓存,下次或者另外一个线程直接使用 - 不可变性是关键: 最重要的因素是 String 对象的底层字符数据的不可变性。如果字符串的内容可以更改,那么
hash上的数据竞争将是一个严重的问题。但由于字符串是不可变的,因此哈希码计算保证始终产生相同的结果。
局部变量保证线程安全
看 String 这个类的 hashcode 方法,如下:
1
2
3
4
5
6
7
8
9
10
11
public int hashCode() {
int h = hash; /* 代码① */
if ( h == 0 && value.length > 0 ) {
char val[] = value;
for ( int i = 0; i < value.length; i++ ) {
h = 31 * h + val[i];
}
hash = h; /* 代码② */
}
return(h); /* 代码③ */
}
hash 是 String 类的一个属性,可以看到这边首先是代码①读取了本地属性的值,并且赋值给局部变量 h。并且使用 h 进行了业务逻辑的判断。如果 h 没有值的话,就进行 Hash 值的生成,并且赋值到 h 上,并且在代码②处赋值给了属性 hash。最终返回的也是局部变量 h 的值。
代码能否修改为下面的模式?
1
2
3
4
5
6
7
8
9
10
11
12
public int hashCode() {
// 修改的代码没有局部变量,直接使用属性本身来操作。
if ( hash == 0 && value.length > 0 ) { /* 代码① */
char val[] = value;
int h = 0;
for ( int i = 0; i < value.length; i++ ) {
h = 31 * h + val[i];
}
hash = h;
}
return(hash); /* 代码② */
}
不行。
存在的问题:
- 可见性问题:在多线程环境中,一个线程对共享变量
hash的更新,可能无法立即被其他线程看到,因为缺乏适当的同步机制或volatile关键字。 - 竞态条件:多个线程可能同时发现
hash == 0,然后各自计算哈希值并更新hash。这会导致hash被重复计算和更新,增加了不必要的开销。 - 返回值不一致:由于直接返回共享变量
hash,存在在计算和返回之间hash被其他线程修改的可能性,导致返回的哈希值与当前线程的计算结果不一致。
结论
- 原始代码是线程安全的,因为每个线程都使用自己的本地变量
h进行计算,并返回与其计算一致的哈希值。 - 修改后的代码存在线程安全问题,由于直接依赖共享变量
hash,在没有适当同步的情况下,可能导致返回的哈希值与预期不符。
《Effective Java》上的回答
之所以选择 31,是因为它是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与 2 相乘等价于移位运算。使用素数的好处并不很明显,但是习惯上都使用素数来计算散列结果。
31 有个很好的特性,即用移位和减法来代替乘法,可以得到更好的性能:31 * i ==(i << 5)- i。现代的 VM 可以自动完成这种优化。
https://stackoverflow.com/questions/299304/why-does-javas-hashcode-in-string-use-31-as-a-multiplier
这是个比较有争议的答案,分为三部分来讨论:
为什么要选择奇数
如果用 2 作乘数,则所有的数会落在 0 和 1 两个位置(余 0 或余 1)。
2 不能作为乘数,则剩下的素数肯定是奇数。问题就转换为为什么要选择素数。
为什么要选择素数
为什么要选择 31
先看 JDK 开发者之一兼《Effective Java》作者 joshua.bloch 在 https://bugs.java.com/bugdatabase/view_bug.do?bug_id=4045622 的回复(JDK1.1.1 使用 37 处理短字符串,使用 39 处理长字符串):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public int hashCode() {
int h = 0;
int off = offset;
char val[] = value;
int len = count;
if (len < 16) {
for (int i = len ; i > 0; i--) {
h = (h * 37) + val[off++];
}
} else {
// only sample some characters
int skip = len / 8;
for (int i = len ; i > 0; i -= skip, off += skip) {
h = (h * 39) + val[off];
}
}
return h;
}
存在的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
It turns out that there's another, unrelated bug in the spec: there is an error in the formulae for calculating the increment (k) and maximum value (m)
that are used in the sigma expression for the "sampled hash" that is used
if n > 15. As a result, the specified expression references charcters
that lie out of bounds, and would cause runtime exceptions if correctly
implemented.
joshua.bloch@Eng 1997-04-24
The Problem: The currently specified String hash function does not match
the currently implemented function. The specified function
is not implementable. (It addresses characters outside of
the input string.) The implemented function performs very
poorly on certain classes of strings, including URLs. (The
poor performance is due to the "sampling" nature of the
function for strings over 15 characters.) I view the
specification problem as the perfect opportunity to replace
the unfortunate implementation.
Requesters: The problems with the implementation have been mentioned
on comp.sys.java.lang.programmer, though the extent of the
problem may not be known outside of JavaSoft. The problems
with the spec were discovered by Peter Kessler and myself.
大意是原来的 Java 语言规范 JLS 使用乘数 39 处理超过 15 个字符的字符串时会抛出异常,从而影响性能。

处理小字符串为什么用 37 已不可考。
解决方案
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Proposed API change: No API would change, per se. The function computed
by String.hashCode() would change to:
s[0] * 31^(n-1) + s[1] * 31^(n-2) + … + s[n-1]
where s[i] is the ith character of string s.
The Java Language Specification (which specifies the
value to be returned by String.hashCode()) would be
modified to reflect this.
The new hash function was selected after a fair amount
of study, as described in Exhibit A. In the unlikely
event that you want even more detail, see me.
将乘数修正为 31,是他经过大量研究的结果。而且对大字符串进行散列将更有效。
为什么候选乘数有 31 也不可考(即使是 Kernighan 和 Ritchie 也不记得它是从哪里来的)。
1
2
3
4
5
6
7
8
9
10
11
So why do I think we should use this function? Simply put, it's the
best general purpose string hash function that I was able to find, and
it's cheap to calculate. By 'general purpose', I mean that it's not
optimized for any specific type of strings (e.g., compiler symbols), but
seems to resist collisions across every collection of strings that I was
able to throw at it. This is critical given that we have no idea what
sort of strings people will store in Java hash tables. Also, the
performance of this class of hash functions seems largely unaffected by
whether the size of the hash table is prime or not. This is important
because Java's auto-growing hash table is typically does not contain a
prime number of buckets.
通过以上分析,我们知道了 31 是开发者权衡了 计算成本、兼容性(Java 是个跨平台语言,考虑兼容小系统)、规范复杂性 的综合选择,同时它又恰好是个素数(如序列{11,44,77}取 31 作为乘数比 33 更好)
那么用 31 作为乘数的哈希函数是好的吗?什么才是理想的哈希函数?它们有多大差距呢?
String.hashCode() 的目的

String.hashCode() is not even a little unique : r/programming
哈希表/散列表一般有两种用途:加密 or 索引,这里将 hashCode 用作索引方便查找,没有必要花费额外的性能成本(比如调用安全散列函数)。
小结
- Java 是一门跨平台的语言,
31能提高小系统的运算效率(乘法转换为:移位 + 加法) - 与合数相比,选择素数普适性更好
31不一定是最好的,但至少不差(与理想乘数相比)- Java 中 String 类型的对象大部分是常量,它的 hashCode()只用作索引,没有必要花费更多计算成本提高安全性或保证无冲突,它是速度、碰撞次数、平台兼容性等多方面综合考虑的结果。