Java HashMap
HashMap 原理
HashMap 特点
- 可以保存 null 键和 null 值,只能一个 null 键,多个 null 键覆盖;可以有多个 null 值;null 键存放在第一个位置
- 无法保证顺序,也不保证顺序不随时间变化
- 和 HashTable 类似,除了不同步的和允许 null 键和 null 值
- 底层是数组加链表结合的哈希表方式实现
- HashMap 中解决 hash 冲突采用的是链接地址法
- Fail-Fast 机制
HashMap 默认初始容量为 16,负载因子为 0.75
HashMap 内部数组大小为 2 的幂值
HashMap 原理
一些变量和常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient int size;
int threshold;
final float loadFactor;
// JDK7.0,大小必须为2的幂,默认是个空的数组,Entry实现了Map.Entry
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// JDK8.0,大小必须为2的幂,首次使用时初始化,Node实现了Map.Entry
transient Node<K,V>[] table;
- size 桶当前装了多少数据
记录了 Map 中 KV 对的个数 - capacity 桶能装数据的最大容量
bucket 容量,即 HashMap 的容量大小。默认 16 - loadFactor
装载因子,loadFactor 的默认值为 0.75f。负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。默认的的负载因子 0.75 是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize 后的 HashMap 容量是容量的两倍。 - threshold
临界值,当实际 KV 个数超过 threshold 时 (size>=capacity),HashMap 会将容量扩容,threshold=capacity*loadFactor - Map.Entry 包含要存储的 key,value,hash 和链表下一个节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// JDK7.0
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; // key
V value; // value
Entry<K,V> next; // 下一个元素
int hash; // hash值
}
// JDK8.0
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
构造器
JDK7.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
this.loadFactor = loadFactor; // 初始化装载因子
threshold = initialCapacity; // threshold为初始化容量
init(); // 空实现,留给子类实现的,比如LinkedHashMap
}
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR); // 取默认值和m容量的最大值作为新的容量
inflateTable(threshold);
putAllForCreate(m); // 将m添加进去
}
看看 inflateTable 做了什么?
1
2
3
4
5
6
7
8
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); // 得到小于等于参数的最大2的幂,如7→4,15→8,16→16,17→16
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // 扩容阈值
table = new Entry[capacity]; // 初始化table数组
initHashSeedAsNeeded(capacity);
}
inflateTable 又调用了 roundUpToPowerOf2():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// HashMap JDK7.0
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY // 不超过最大容器
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; // 小于等于1都为1;其他情况找最近的不超过这个数的2次幂
}
// Integer.java
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
概念:如果一个数是 2 的幂次方数,那么这个数表示成 10 进制的时候,一定只有一个 1 而其他位上都是 0,如:4:0100,8:1000,16:10000
具体的运算过程见:详解Integer.highestOneBit()
- JDK7.0 构造器小结:
- initialCapacity 传递多少就是多少,只要不超过 2^30;
- loadFactor 传递多少就是多少
- threshold 为 initialCapacity;HashMap(Map) 构造器 threshold=capacity*loadFactor(其中 capacity 为传递的不大于 initialCapacity 的 2 次幂)
JDK8.0+/JDK11.0+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static final int MAXIMUM_CAPACITY = 1 << 30; // 2^30
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
// ...
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY; // 初始化容量最大为2^30次
// ...
this.loadFactor = loadFactor; // 装载因子,默认0.75
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
- HashMap 最大容量 2^30;默认初始化容量 16;默认装载因子 0.75f
- threshold 默认为大于 initialCapacity 的二次幂,如 3→4,7→8,15→16,16→16,17→32
看看 tableSizeFor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// JDK8.0+
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// JDK11.0+
static final int tableSizeFor(int cap) {
int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1); // 给定一个int类型数据,返回这个数据的二进制串中从最左边算起连续的“0”的总数量。因为int类型的数据长度为32所以高位不足的地方会以“0”填充。
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap 的容量计算,JDK11 的计算比 JDK8.0 计算快一倍
HashMap在JDK8和JDK11的容量计算算法tableSizeFor分析
put 存放元素
将 key 和 value 存放到 map 中去,并返回该 key 原先的 value;返回 null 如果原先没有该 key,或者原先该 key 的位置存储的是 null 值。
put JDK7.0
大致的思路为:
- 如果 table 为空,初始化 table 和 threshold(
capacity * loadFactor) - 如果 key 为 null,插入到 table 索引为 0 的位置
- 如果 key 不为 null
- 对 key 的 hashCode() 做 hash,然后再计算 index
- 如果节点已经存在就替换 old value(保证 key 的唯一性:key 的 hash 一致且 key 为同一对象或 key 的 equals 相等)
- 如果没碰撞直接放到 bucket 里
- 如果碰撞了,以链表的形式存在 buckets 后(头插法)
- 如果 bucket 满了 (>=threshold),就要扩容 resize,扩容原有 table 大小的两倍(先扩容再插入元素)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// HashMap 7.0
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
public V put(K key, V value) {
if (table == EMPTY_TABLE) { // table为空,初始化threshold和table数组
inflateTable(threshold);
}
// 1、特殊key值处理,key为null,调用putForNullKey
if (key == null)
return putForNullKey(value); // 存放key=null,多次put会覆盖上一次的value
// key不为null
int hash = hash(key); // 2、计算hash,减少碰撞机会
int i = indexFor(hash, table.length); // 计算table中目标bucket的下标
// 3、指定目标bucket,遍历Entry结点链表,若找到key相同的Entry结点,替换,并返回旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 相同的前提,hash一样,key是同一个对象或者key的equals相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; // 旧值
e.value = value; // 用新值覆盖旧值
e.recordAccess(this);
return oldValue; // 返回旧值
}
}
modCount++;
// 4、若未找到目标Entry结点,则新增一个Entry结点
addEntry(hash, key, value, i);
return null;
}
1. 特殊 key 值处理,key 为 null putForNullKey
特殊 key 值,指的就是 key 为 null。 先说结论:
- HashMap 中,是允许 key、value 都为 null 的,且 key 为 null 只存一份,多次存储会将旧 value 值覆盖;value 可以多个为 null;
- key 为 null 的存储位置,都统一放在下标为 0 的 bucket,即:
table[0]位置的链表; - 如果是第一次对 key=null 做 put 操作,将会在
table[0]的位置新增一个 Entry 结点,使用头插法做链表插入。
先来看 putForNullKey:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private V putForNullKey(V value) {
// 如果存在table数组第0个不为null,进入循环
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) { // table[0]的key为null
V oldValue = e.value; // 原有位置的老值
e.value = value; // table[0]覆盖成新的值
e.recordAccess(this);
return oldValue; // 返回旧的值
}
}
modCount++;
// table[0]不存在,直接添加Entry
addEntry(0, null, value, 0);
return null;
}
putForNullKey() 方法中的代码较为简单:首先选择
table[0]位置的链表,然后对链表做遍历操作,如果有结点的 key 为 null,则将新 value 值替换掉旧 value 值,返回旧 value 值,如果未找到,则新增一个 key 为 null 的 Entry 结点。
第二个方法 addEntry()。 这是一个通用方法:
1
2
3
4
5
6
7
8
9
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) { // 如果table的size大于等于阈值threshold了,需要扩容
resize(2 * table.length); // 扩容为2倍length
hash = (null != key) ? hash(key) : 0; // 扩容后,重新计算hash
bucketIndex = indexFor(hash, table.length); // 扩容后,重新计算索引
}
// 创建新的Entry
createEntry(hash, key, value, bucketIndex);
}
给定 hash、key、value、bucket 下标,新增一个 Entry 结点,另外还担负了扩容职责。如果哈希表中存放的 k-v 对数量超过了当前阈值 (
threshold = table.length * loadFactor),且当前的 bucket 下标有链表存在,那么就做扩容处理(resize)。扩容后,重新计算 hash,最终得到新的 bucket 下标,然后使用头插法新增结点。
2. 扩容 resize
- 扩容后大小是扩容前的 2 倍,
resize(2 * table.length) - 数据搬迁,从旧 table 迁到扩容后的新 table。为避免碰撞过多,先决策是否需要对每个 Entry 链表结点重新 hash,然后根据 hash 值计算得到 bucket 下标,然后使用头插法做结点迁移。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { // 旧的容量已经达到了2^30次
threshold = Integer.MAX_VALUE; // 阈值直接等于int最大值
return;
}
Entry[] newTable = new Entry[newCapacity]; // 创建一个新的Entry数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable; // 新的数组赋值给table
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); // 阈值重新用新的容量*负载因子计算
}
void transfer(Entry[] newTable, boolean rehash) { // 将旧的元素转移到新的数组去
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) { // 有元素,遍历链表,将旧的元素重新计算hash值,索引,存到新的数组中去
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
3. 如何计算 bucket 下标?
- hash 值的计算
hash 值的计算,首先得有 key 的 hash 值,就是一个整数,int 类型,其计算方式使用了一种可尽量减少碰撞的算式(高位运算);使用 key 的 hashCode 作为算式的输入,得到了 hash 值。
对于两个对象,若其 hashCode 相同,那么两个对象的 hash 值就一定相同;但两个对象 hash 值相同,对象不一定相同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// HashMap JDK7.0
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
- 接着看 indexFor(),计算索引,就是对 length 取余:
1
2
3
4
5
// HashMap JDK7.0
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
将 table 的容量与 hash 值做 “ 与 “ 运算,得到哈希 table 的 bucket 下标
table 的容量 length 都是 2 的幂次方,所以这个等式 h & (length-1) 也等价于 h % length,h 对 length 取模,只是位运算性能高点
哈希 table 的初始大小默认设置为 16,为 2 的次幂数。后面在扩容时,都是以 2 的倍数来扩容。为什么非要将哈希 table 的大小控制为 2 的次幂数?
- 降低发生碰撞的概率,使散列更均匀。根据 key 的 hash 值计算 bucket 的下标位置时,使用 “ 与 “ 运算公式:
h & (length-1),当哈希表长度为 2 的次幂时,等同于使用表长度对 hash 值取模(不信大家可以自己演算一下),散列更均匀; - 表的长度为 2 的次幂,那么 (length-1) 的二进制最后一位一定是 1,在对 hash 值做 “ 与 “ 运算时,最后一位就可能为 1,也可能为 0,换句话说,取模的结果既有偶数,又有奇数。设想若 (length-1) 为偶数,那么 “ 与 “ 运算后的值只能是 0,奇数下标的 bucket 就永远散列不到,会浪费一半的空间。
4. 在目标 bucket 中遍历 Entry 结点
1
2
3
4
5
6
7
8
9
10
11
12
int i = indexFor(hash, table.length); // 计算table中目标bucket的下标
// 3、指定目标bucket,遍历Entry结点链表,若找到key相同的Entry结点,替换,并返回旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 相同的前提,hash一样,key是同一个对象或者key的equals相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; // 旧值
e.value = value; // 用新值覆盖旧值
e.recordAccess(this);
return oldValue; // 返回旧值
}
}
通过 hash 值计算出下标,找到对应的目标 bucket,然后对链表做遍历操作,逐个比较,如下:
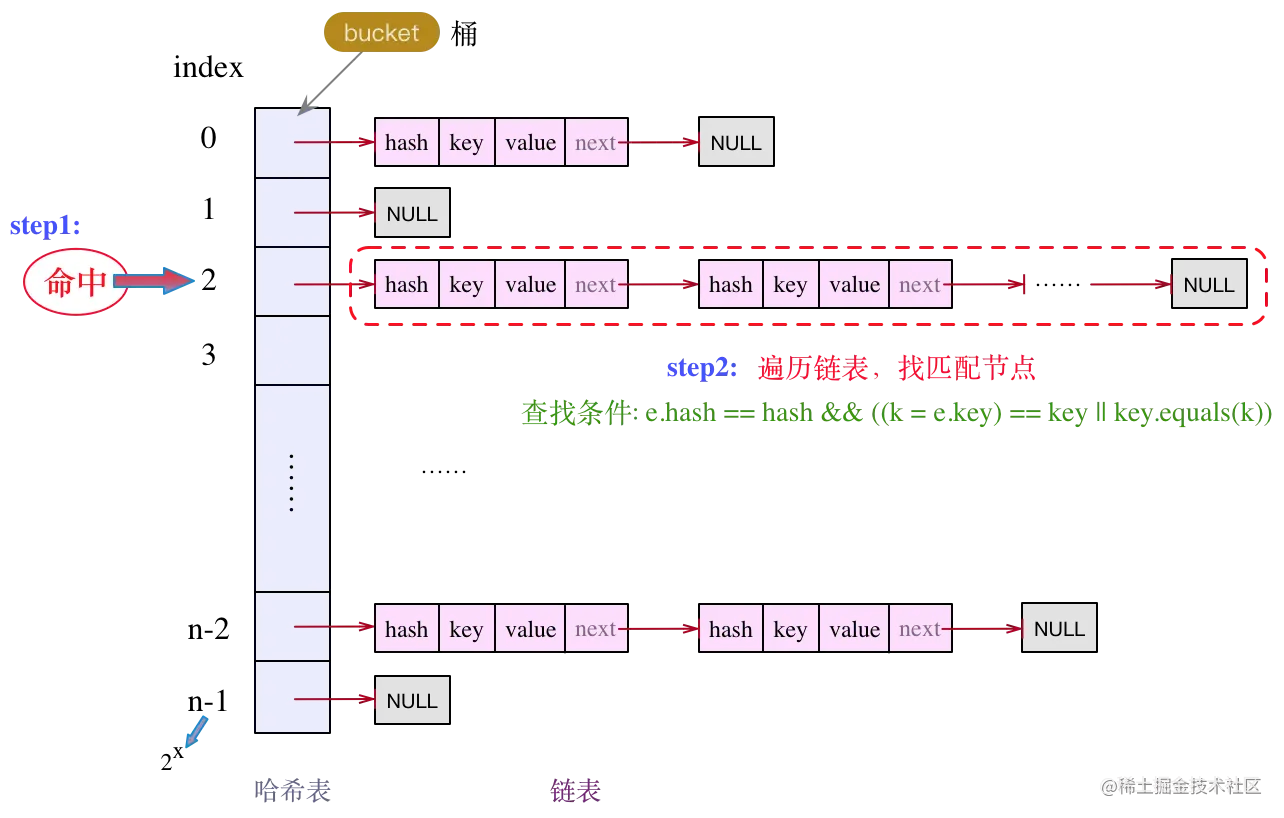
查找条件:e.hash == hash && ((k = e.key) == key || key.equals(k)) 结点的 key 与目标 key 的相等,要么内存地址相等,要么逻辑上相等,两者有一个满足即可。
5. 添加新的 Entry createEntry
1
2
3
4
5
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; // 位置bucketIndex的元素,e不为nulL表示该位置有元素了
table[bucketIndex] = new Entry<>(hash, key, value, e); // 如果索引bucketIndex存在元素了,那么进行链表头插法
size++; // 大小加1
}
头插法插入到链表
put JDK8.0
- JDK8.0 put 流程
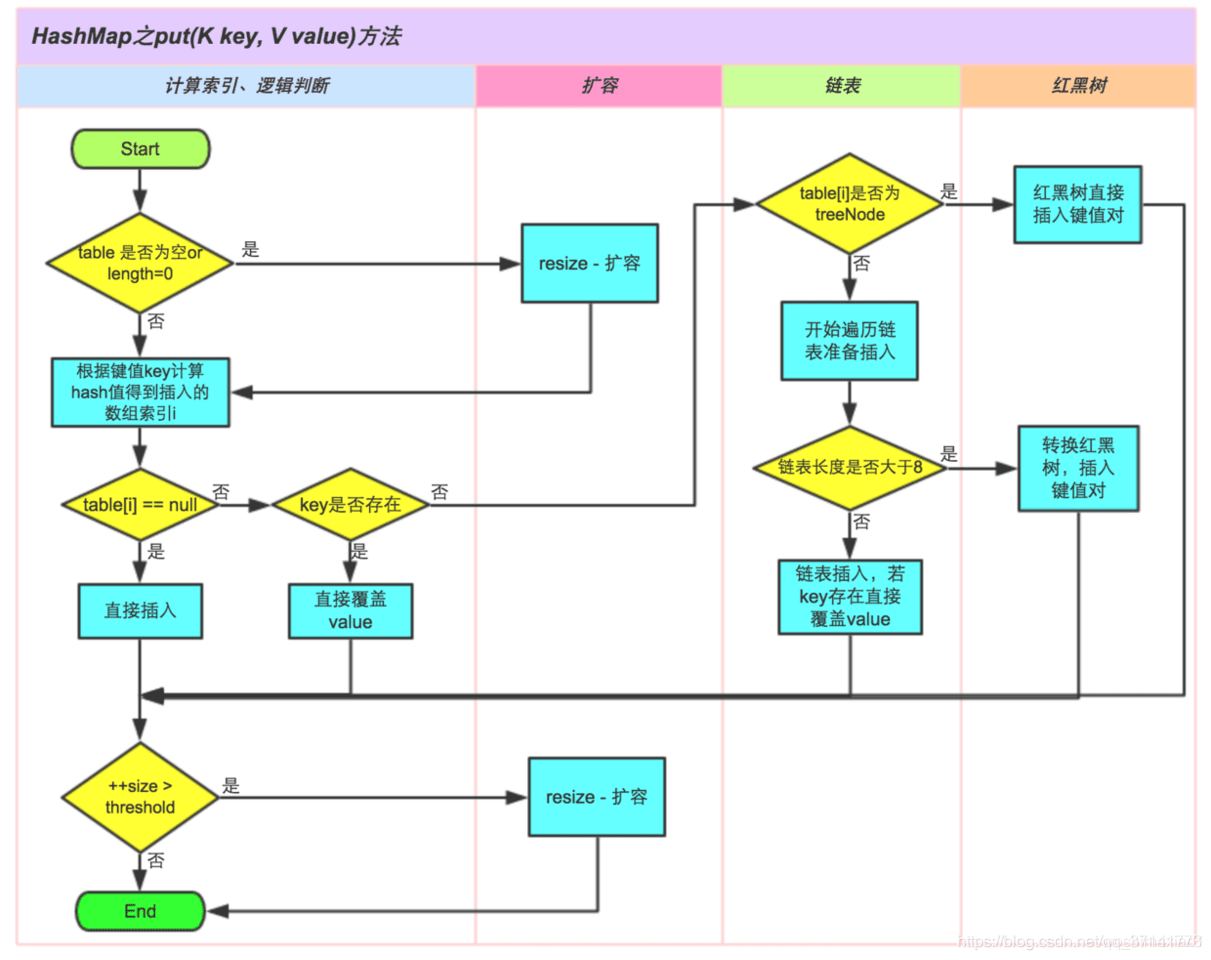
- JDK8.0 put 源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
// HashMap JDK8.0
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // 1. table为null或者table数组大小为0
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 2. (n - 1) & hash计算索引,根据index找到目标bucket后,若当前bucket上没有结点,那么直接新增一个结点,赋值给该bucket
tab[i] = newNode(hash, key, value, null);
else { // 3. 该位置已经有元素
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) // 3.1 当前bucket上有链表,且头结点key就匹配,那么直接做替换即可;
e = p;
else if (p instanceof TreeNode) // 3.2 若当前bucket上的是树结构,则转为红黑树的插入操作;
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // 3.3 链表结构
for (int binCount = 0; ; ++binCount) { // 遍历链表,插入到合适的位置
if ((e = p.next) == null) { // 3.3.2 遍历到链表最后,未找到相同的key,那么插入
p.next = newNode(hash, key, value, null); // 插入到链表尾部
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st // 若链表长度大于TREEIFY_THRESHOLD-1,则执行红黑树转换操作,转换为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 3.3.1 遍历链表的过程中,找到了相同的key,直接break
break;
p = e;
}
}
if (e != null) { // existing mapping for key // 3.4 替换该位置元素
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 4 看当前Map中存储的k-v对的数量是否超出了threshold,若超出,还需再次扩容。
resize();
afterNodeInsertion(evict);
return null;
}
put 主要流程
- table 为 null 或者 table 数组大小为 0,进行一次 resize 扩容
- 根据 index 找到目标 bucket 后,若当前 bucket 上没有结点,那么直接新增一个结点,赋值给该 bucket
- 该位置有元素,替换还是插入到链表或红黑树
- 3.1 当前 bucket 上有链表,且头结点 key 就匹配,那么直接做替换即可;
- 3.2 若当前 bucket 上的是树结构,则转为红黑树的插入操作;
- 3.3 遍历链表(第一个节点的 key 不相等)
- 3.3.1 若链表中有结点匹配,则做 value 替换
- 3.3.2 若没有结点匹配,则在链表末尾追加
- 若链表长度大于
TREEIFY_THRESHOLD-1且数组长度大于MIN_TREEIFY_CAPACITY=64,则执行红黑树转换操作,转换为红黑树 - 若链表长度大于
TREEIFY_THRESHOLD-1且数组长度小于MIN_TREEIFY_CAPACITY,则执行扩容 resize() 操作
- 若链表长度大于
- 3.4 替换该位置元素
- 看当前 Map 中存储的 k-v 对的数量是否超出了 threshold,若超出,还需再次扩容。
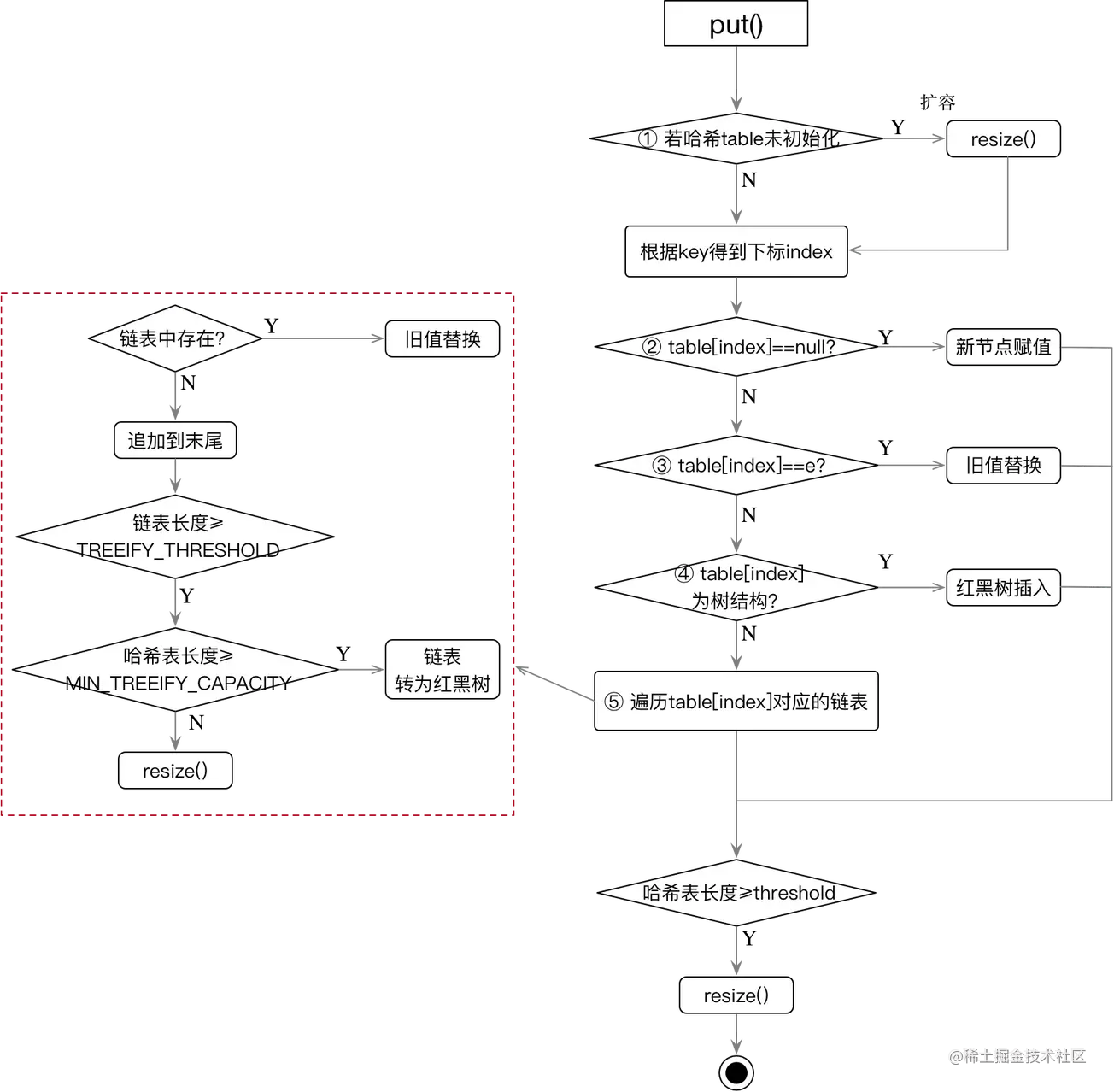
红黑树的转换操作如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) // 若表为空,或table长度小于MIN_TREEIFY_CAPACITY,也不做转换,直接做扩容处理。
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) { // 转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
扩容 resize
什么场景下会触发扩容?
- 哈希 table 为 null 或长度为 0;
- Map 中存储的 k-v 对数量超过了阈值 threshold(
threshold = capacity*loadFactor); - 链表中的长度超过了
TREEIFY_THRESHOLD(8),但表长度却小于MIN_TREEIFY_CAPACITY(64)。
扩容分为 2 步
- 对哈希表原有长度的扩展(2 倍)
- 将旧 table 中的数据搬到新 table 上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // 旧table数组
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 旧table容量大小
int oldThr = threshold; // 阈值
int newCap, newThr = 0;
if (oldCap > 0) { // 1. 旧table大小大于0
if (oldCap >= MAXIMUM_CAPACITY) { // 1.1 达到最大容量2^30,阈值threshold等于Int最大值
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) // 1.2 原有oldCap扩容一倍;且oldCap大于等于默认容量16
newThr = oldThr << 1; // double threshold,阈值*2
}
else if (oldThr > 0) // initial capacity was placed in threshold // 2.1 初始化为threshold,在构造器中,threshold等于initCapacity
newCap = oldThr; // 也就是说初始化的容量就是构造器的initCapacity
else { // zero initial threshold signifies using defaults // 3.1 未指定initCapacity,容量和阈值都设置为默认的
newCap = DEFAULT_INITIAL_CAPACITY; // 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 12
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 4 创建一个新的Node数组
table = newTab; // newTab赋值给table
// 下面就是旧数据的迁移到newTab中去
if (oldTab != null) { // 5. 旧table有数据
for (int j = 0; j < oldCap; ++j) { // 循环遍历旧数据的哈希table的每个不为null的bucket
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) // 5.1 // 若只有一个结点,则原地存储
newTab[e.hash & (newCap - 1)] = e; // 该位置的Node没有下一个元素,重新计算索引,放到新的table中newTab
else if (e instanceof TreeNode) // 5.2 是红黑树
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order // 5.3 链表迁移,"lo"前缀的代表要在原bucket上存储,"hi"前缀的代表要在新的bucket上存储
Node<K,V> loHead = null, loTail = null; // 原bucket的头、尾节点
Node<K,V> hiHead = null, hiTail = null; // 在新bucket的头、尾节点
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { // 0,不需要移动
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else { // 1,需要移动
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null); // 循环遍历每个桶上的链表
if (loTail != null) { // 不需要迁移的数据
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) { // 需要迁移的数据
hiTail.next = null;
newTab[j + oldCap] = hiHead; // 新下标为从当前下标往前挪oldCap个距离
}
}
}
}
}
return newTab;
}
我们使用的是 2 次幂的扩展 (指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。看下图可以明白这句话的意思,n 为 table 的长度。
- 图(a)表示扩容前的 key1 和 key2 两种 key 确定索引位置的示例,
- 图(b)表示扩容后 key1 和 key2 两种 key 确定索引位置的示例,其中 hash1 是 key1 对应的哈希与高位运算结果。
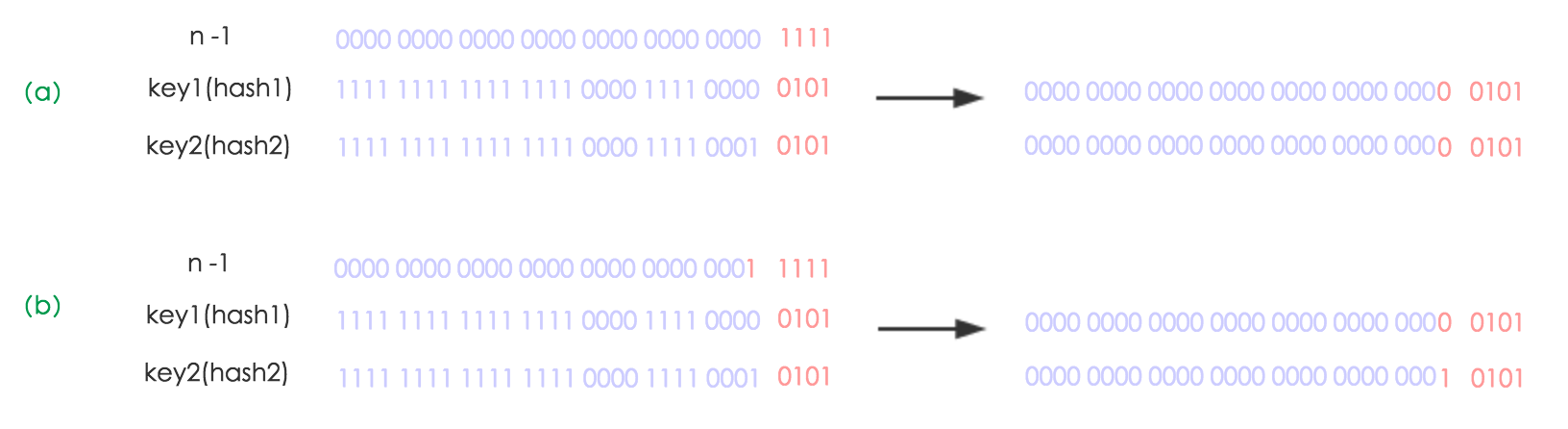
元素在重新计算 hash 之后,因为 n 变为 2 倍,那么 n-1 的 mask 范围在高位多 1bit(红色),因此新的 index 就会发生这样的变化: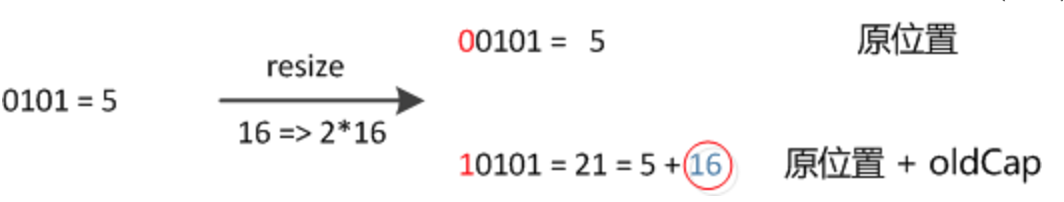
因此,我们在扩充 HashMap 的时候,不需要像 JDK1.7 的实现那样重新计算 hash,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成 “ 原索引 +oldCap”,可以看看下图为 16 扩充为 32 的 resize 示意图:
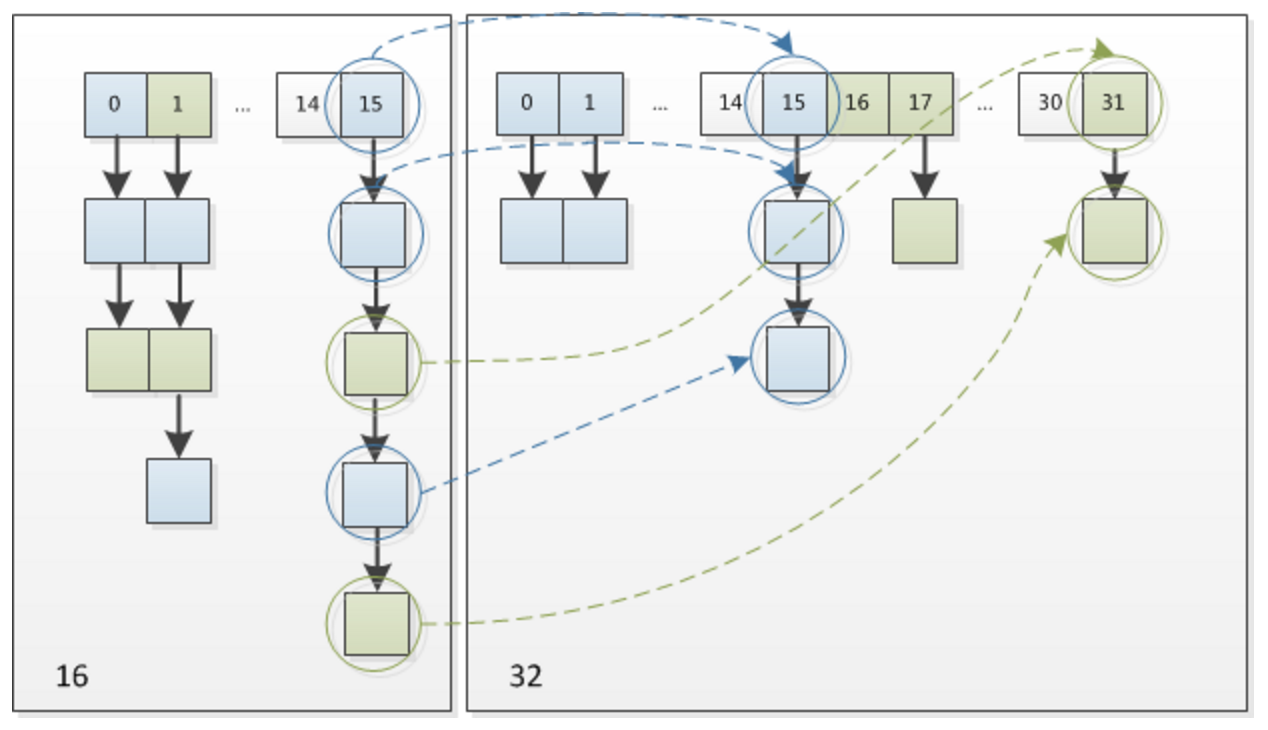
这个设计确实非常的巧妙,既省去了重新计算 hash 值的时间,而且同时,由于新增的 1bit 是 0 还是 1 可以认为是随机的,因此 resize 的过程,均匀的把之前的冲突的节点分散到新的 bucket 了。这一块就是 JDK1.8 新增的优化点。有一点注意区别,JDK1.7 中 rehash 的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8 不会倒置。
get 获取元素
get JDK7.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public V get(Object key) {
if (key == null) // 1. 获取key为null的,索引0位置
return getForNullKey();
Entry<K,V> entry = getEntry(key); // 2. 根据key获取Entry
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key); // 获取hash
for (Entry<K,V> e = table[indexFor(hash, table.length)]; // 获取index
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 找到返回
return e;
}
return null;
}
get JDK8.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
fail-fast 机制
fail-fast 经常和 ConcurrentModificationException 一起出现,来看看这两者的关系?
什么是 fail-fast?我们可以称它为 “ 快速失效策略 “,下面是 Wikipedia 中的解释:
1
2
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process.
Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
就是在系统设计中,当遇到可能会诱导失败的条件时立即上报错误,快速失效系统往往被设计在立即终止正常操作过程,而不是尝试去继续一个可能会存在错误的过程。
简洁点说,就是尽可能早的发现问题,立即终止当前执行过程,由更高层级的系统来做处理。
在 HashMap 中,我们前面提到的 modCount 域变量 (集合框架中的其他集合也是类似的),就是用于实现 hashMap 中的 fail-fast。出现这种情况,往往是在非同步的多线程并发操作。
在对 Map 的做迭代 (Iterator) 操作时,会将 modCount 域变量赋值给 expectedModCount 局部变量。在迭代过程中,用于做内容修改次数的一致性校验。若此时有其他线程或本线程的其他操作对此 Map 做了内容修改时,那么就会导致 modCount 和 expectedModCount 不一致,立即抛出异常 ConcurrentModificationException。
比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public static void main(String[] args) {
Map<String, Integer> testMap = new HashMap<>();
testMap.put("s1", 11);
testMap.put("s2", 22);
testMap.put("s3", 33);
for (Map.Entry<String, Integer> entry : testMap.entrySet()) {
String key = entry.getKey();
if ("s1".equals(key)) {
testMap.remove(key);
}
}
}
---- output ---
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1437)
at java.util.HashMap$EntryIterator.next(HashMap.java:1471)
at java.util.HashMap$EntryIterator.next(HashMap.java:1469)
...
正确的删除 Map 元素的姿势:只有一个,Iterator 的 remove() 方法。
1
2
3
4
5
6
7
8
Iterator<Entry<String, Integer>> iterator = testMap.entrySet().iterator();
while (iterator.hasNext()) {
Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey() + ":" + next.getValue());
if (next.getKey().equals("s2")) {
iterator.remove();
}
}
但也要注意一点,能安全删除,并不代表就是多线程安全的,在多线程并发执行时,若都执行上面的操作,因未设置为同步方法,也可能导致 modCount 与 expectedModCount 不一致,从而抛异常 ConcurrentModificationException。
HashMap 面试题
HashMap、HashTable 是什么关系?
- 共同点
- 底层都是哈希表 + 链表实现
- 区别
- 从层级结构上看,HashMap、HashTable 有一个共用的 Map 接口。另外,HashTable 还单独继承了一个抽象类 Dictionary;
- HashTable 诞生自 JDK1.0,HashMap 从 JDK1.2 之后才有;H3. ashTable 线程安全,HashMap 线程不安全;
- 初始值和扩容方式不同。HashTable 的初始值为 11,扩容为原大小的
2*d+1。容量大小都采用奇数且为素数,且采用取模法,这种方式散列更均匀。但有个缺点就是对素数取模的性能较低(涉及到除法运算),而 HashTable 的长度都是 2 的次幂,设计就较为巧妙,这种方式的取模都是直接做位运算,性能较好。 - HashMap 的 key、value 都可为 null,且 value 可多次为 null,key 多次为 null 时会覆盖。当 HashTable 的 key、value 都不可为 null,否则直接 NPE(NullPointException)。
HashMap 怎么计算数组下标的?
1
index = (n - 1) & hash]
- hash 为 key 的哈希值
- n 为 table 长度,为 2 的 n 次幂,如 4、8、16,默认 16
以 16 为例:
1
2
3
n = 16
n-1 = 15 = 0000 1111
hash & 1111 = hash的后四位为1的为1,为0的为0
上面的公式等于对 n 取模,这里 n 为 16,n 为 2 的倍数
这就是为什么容量要为 2 的倍数,可以减少很多 hash 冲突
HashMap 的 hash 函数设计?为什么要用异或运算符?还有哪些算法可以计算出 hash 值?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// JDK7.0
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// JDK8.0
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
JDK 8.0 中,是通过 hashCode() 的高 16 位异或低 16 位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度,功效和质量来考虑的,减少系统的开销,也不会造成因为高位没有参与下标的计算,从而引起的碰撞。
为什么要用异或运算符?
保证了对象的 hashCode 的 32 位值只要有一位发生改变,整个 hash() 返回值就会改变。尽可能的减少碰撞。
其他可以计算出 hash 值的算法有:
- 平方取中法
- 取余数
- 伪随机数法
一个 HashMap 的容量(capacity)默认是 16,设计成 16 的好处?为何总是 2 的 n 次方?
HashMap 根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的 2 的幂。
设计成 2 的幂次方?
- 使数据分布均匀,减少碰撞
- 性能更好:当 length 为 2 的 n 次方时,
h&(length - 1)就相当于对 length 取模,而且在速度、效率上比直接取模要快得多
为什么 HashMap 的底层数组长度为何总是 2 的 n 次方?
- 当 length 为 2 的 N 次方的时候,h & (length-1) = h % length
为什么&效率更高呢?因为位运算直接对内存数据进行操作,不需要转成十进制,所以位运算要比取模运算的效率更高
- 当 length 为 2 的 N 次方的时候,数据分布均匀,减少冲突
我们来举例当 length 为奇数、偶数时的情况: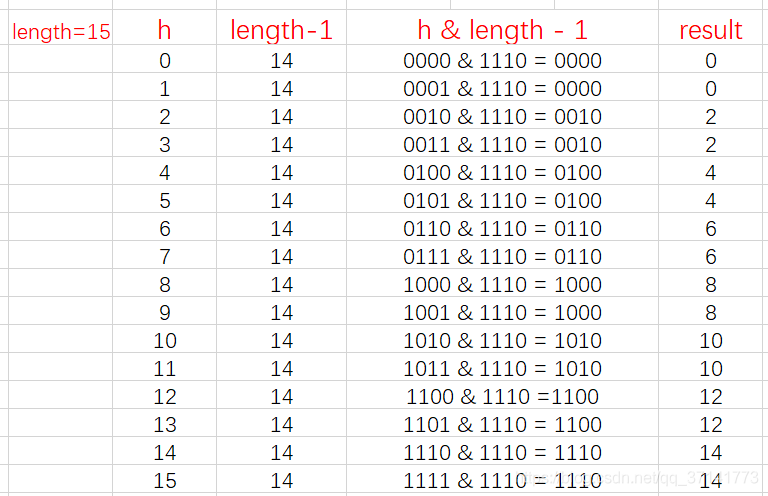
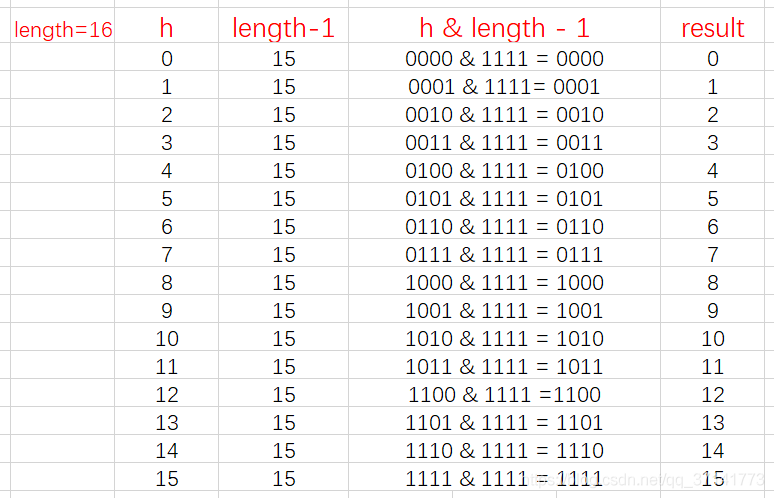
从上面的图表中我们可以看到,当 length 为 15 时总共发生了 8 次碰撞,同时发现空间浪费非常大,因为在 1、3、5、7、9、11、13、15 这八处没有存放数据。
这是因为 hash 值在与 14(即 1110)进行&运算时,得到的结果最后一位永远都是 0,那么最后一位为 1 的位置即 0001、0011、0101、0111、1001、1011、1101、1111 位置处是不可能存储数据的。这样,空间的减少会导致碰撞几率的进一步增加,从而就会导致查询速度慢
而当 length 为 16 时,length – 1 = 15, 即 1111,那么,在进行低位&运算时,值总是与原来 hash 值相同,而进行高位运算时,其值等于其低位值。所以,当 length=2^n 时,不同的 hash 值发生碰撞的概率比较小,这样就会使得数据在 table 数组中分布较均匀,查询速度也较快。
多试一些数,就可以发现规律:
当 length 为奇数时,length-1 为偶数,而偶数二进制的最后一位永远为 0,那么与其进行 & 运算,得到的二进制数最后一位永远为 0,那么结果一定是偶数,那么就会导致下标为奇数的桶永远不会放置数据,这就不符合我们均匀放置,减少冲突的要求了。
那 length 是偶数不就行了么,为什么一定要是 2 的 N 次方,这不就又回到第一点原因了么?JDK 的工程师把各种位运算运用到了极致,想尽各种办法优化效率。
那么为什么默认是 16 呢?怎么不是 4?不是 8?
关于这个默认容量的选择,JDK 并没有给出官方解释,那么这应该就是个经验值,既然一定要设置一个默认的 2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。
16 就作为一个经验值被采用了。
装载因子为 0.75 原因?为啥不设计为 0.5 或 1.0?
装载因子,loadFactor 的默认值为 0.75f。负载因子衡量的是一个散列表的空间的使用程度。
- loadFactor=0.5 loadFactory 越小,空间利用率低,数组中个存放的数据 (entry) 也就越少,表现得更加稀疏
- loadFactor=1.0
loadFactory 越趋近于 1,空间利用率高,那么数组中存放的数据(entry 也就越来越多),数据也就越密集,也就会有更多的链表长度处于更长的数值,我们的查询效率就会越低,当我们添加数据,产生 hash 冲突的概率也会更高
默认的的负载因子 0.75 是对空间和时间效率的一个平衡选择
HashMap 允许空键空值么?
HashMap 最多只允许一个键为 Null(多条键为 null 的后面的会覆盖前面的),但允许多个值为 Null
JDK7.0 和 JDK8.0 的 initialCapacity 和 threshold 初始化区别?JDK11 初始容量计算?
- JDK7.0,初始化容量就是传进去的 initialCapacity,首次 put,调用 inflateTable,将数组容量调整为 2 的幂次方
- JDK8.0,初始化容量为传递进去的 initialCapacity,大于 initialCapacity 最近的的 2 的 n 次幂,如 3→4;
- JDK8.0 采用的多次右移运行得到 2 的 n 次幂;JDK11 初始容量的位运算是通过补码,性能大于 JDK8.0
见:HashMap在JDK8和JDK11的容量计算算法tableSizeFor分析
JDK7.0 HashMap 怎么在链表上添加数据,在链表的前⾯还是链表的后⾯?
头插法
JDK7.0 HashMap 是怎么预防和解决 Hash 冲突的?
二次哈希 + 拉链法
JDK7.0 HashMap 默认容量是多少?为什么是 16 可以是 15 吗?
- 默认容量 16
- 不可以是 15,必须是 2 的幂次方,这样可以更好的减少 hash 冲突
JDK7.0 HashMap 的数组是什么时候创建的?
首次 put 的时候
JDK7.0 和 JDK8.0 HashMap 数据结构有什么不同?
- JDK7.0,由 “
数组 + 链表” 组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
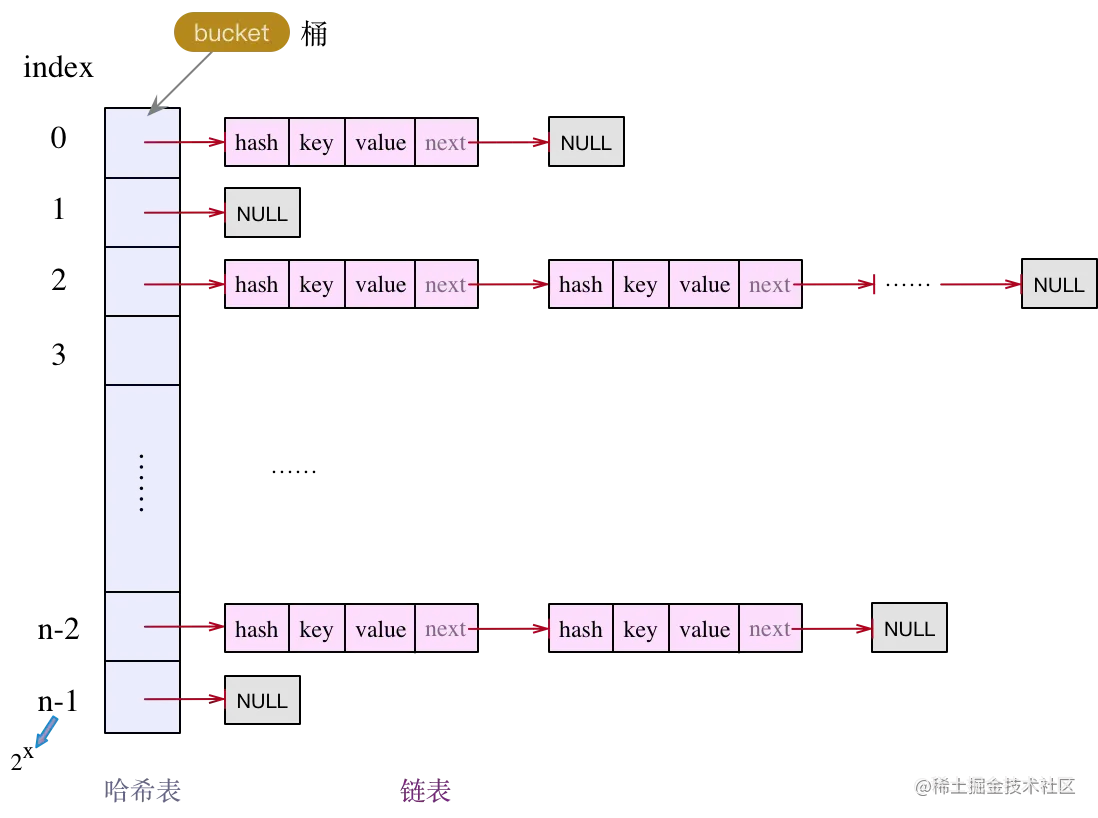
- JDK8.0 中,有 “
数组 + 链表 + 红黑树“ 组成。当链表过长,则会严重影响 HashMap 的性能,红黑树搜索时间复杂度是O(logn),而链表是 O(n)。因此,JDK8.0 对数据结构做了进一步的优化,引入了红黑树,链表和红黑树在达到一定条件会进行转换
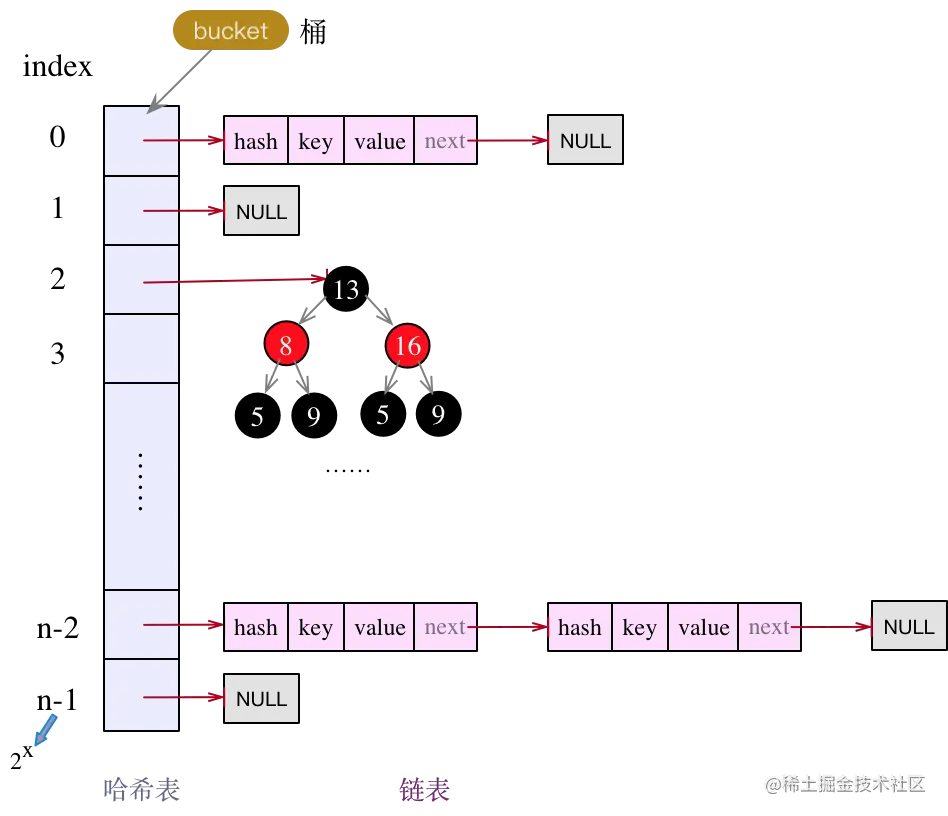
- 当链表超过 8 且数组长度 (数据总量) 超过 64 才会转为红黑树
- 链表超过 8,将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树,以减少搜索时间
JDK8.0 HashMap 往链表上插⼊数据的⽅式和 JDK7.0 有什么不同?
- JDK7.0 是头插法,插入到链表的最前面
- JDK8.0 是尾插法,插入到链表的最后面
JDK8.0 HashMap 什么时候会把链表转化为红⿊树?为什么 Map 桶中节点个数超过 8 才转为红黑树?
链表长度超过 8;并且数组长度不小于 64
为什么 Map 桶中节点个数超过 8 才转为红黑树?
树节点占用空间是普通 Node 的两倍,如果链表节点不够多却转换成红黑树,无疑会耗费大量的空间资源,并且在随机 hash 算法下的所有 bin 节点分布频率遵从泊松分布,链表长度达到 8 的概率只有 0.00000006,几乎是不可能事件,所以 8 的计算是经过重重科学考量的
- 从平均查找长度来看,红黑树的平均查找长度是 logn,如果长度为 8,则 logn=3,而链表的平均查找长度为 n/4,长度为 8 时,n/2=4,所以阈值 8 能大大提高搜索速度
- 当长度为 6 时红黑树退化为链表是因为 logn=log6 约等于 2.6,而 n/2=6/2=3,两者相差不大,而红黑树节点占用更多的内存空间,所以此时转换最为友好
为什么 JDK8.0 改用红黑树?
比如某些人通过找到你的 hash 碰撞值,来让你的 HashMap 不断地产生碰撞,那么相同 key 位置的链表就会不断增长,当你需要对这个 HashMap 的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。Java8 使用红黑树来替代超过 8 个节点数的链表后,查询方式性能得到了很好的提升,从原来的是 O(n) 到 O(logn)。
JDK8.0 拉链法导致的链表过深问题为什么不用二叉查找树代替,而选择红黑树?为什么不一直使用红黑树?
之所以选择红黑树是为了解决二叉查找树的缺陷,二叉查找树在特殊情况下会退化为链表(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。
而红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,引入红黑树就是为了查找数据快,解决链表查询深度的问题,我们知道红黑树属于平衡二叉树,但是为了保持 “ 平衡 “ 是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少,所以当长度大于 8 的时候,会使用红黑树,如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
JDK8.0 HashMap 扩容后存储位置的计算⽅式?和 JDK7.0 相比有什么不同?
- JDK7.0 再次
indexFor(n, length)找到数组索引
1
2
3
4
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
- JDK8.0 不需要再次 indexFor,直接
n & length,看结果是 0 表示索引未动,不为 0 表示需要移动
使用的是 2 次幂的扩展 (指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置;JDK8.0,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成 “ 原索引 +oldCap”
解决 hash 冲突的办法有哪些?HashMap 用的哪种?
- 何为 hash 冲突?
hash 冲突就是在操作哈希表(散列表)的时候,不同的 key 值经过 hash 函数(散列算法)之后得到相同的 hash 值,那么一个位置没法放置两份 value,这种情况就是 hash 冲突。
- 解决 hash 冲突
解决 hash 冲突方法有:开放定址法、再哈希法、链地址法(HashMap 中常见的拉链法)、建立公共溢出区。
- HashMap 中采用的是链地址法。
- 开放地址法(open addressing)
也称为再散列法,基本思想就是,如果 p=H(key) 出现冲突时,则以 p 为基础,再次 hash,p1=H(p),如果 p1 再次出现冲突,则以 p1 为基础,以此类推,直到找到一个不冲突的哈希地址 pi。因此开放定址法所需要的 hash 表的长度要大于等于所需要存放的元素,而且因为存在再次 hash,所以只能在删除的节点上做标记,而不能真正删除节点
通过计算出来冲突的 hash 值进行再次的运算,直到得到可用的地址
- 再哈希法(再散列)
提供多个 hash 函数,冲突时使用其他的 hash 函数再次运算。
这样做虽然不易产生堆集,但增加了计算的时间。
- 链地址法
链地址法(拉链法),将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第 i 个单元中,查找、插入和删除主要在同义词链表中进行,链表法适用于经常进行插入和删除的情况。
就是在哈希表中,针对相同的 hash 值使用链表的方式来存放
- 建立公共溢出区
建立公共溢出区,将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区
开放定址法和再哈希法的区别:开放定址法只能使用同一种 hash 函数进行再次 hash,再哈希法可以调用多种不同的 hash 函数进行再次 hash
JDK8.0 中做了哪些优化优化?
- 数组 + 链表改成了数组 + 链表或红黑树,如果链表的长度超过了 8,那么链表将转换为红黑树。(桶的数量必须大于 64,小于 64 的时候只会扩容)
- 发生 hash 碰撞时,JDK7.0 会在链表的头部插入,而 JDK8.0 会在链表的尾部插入
- 扩容的时候 7.0 需要对原数组中的元素进行重新 hash 定位在新数组的位置,8.0 采用更简单的判断逻辑,
位置不变或索引+旧容量大小 - 在插入时,7.0 先判断是否需要扩容,再插入,8.0 先进行插入,插入完成再判断是否需要扩容
HashMap 线程安全方面会出现什么问题?
1、数据覆盖问题
两个线程执行 put() 操作时,可能导致数据覆盖。JDK7 版本和 JDK8 版本的都存在此问题。
以 JDK7.0 为例,假设 A、B 两个线程同时执行 put() 操作,且两个 key 都指向同一个 buekct,那么此时两个结点,都会做头插法。 先看这里的代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
public V put(K key, V value) {
...
addEntry(hash, key, value, i);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
...
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
看下最后的 createEntry() 方法,首先获取到了 bucket 上的头结点,然后再将新结点作为 bucket 的头部,并指向旧的头结点,完成一次头插法的操作。
当线程 A 和线程 B 都获取到了 bucket 的头结点后,若此时线程 A 的时间片用完,线程 B 将其新数据完成了头插法操作,此时轮到线程 A 操作,但这时线程 A 所据有的旧头结点已经过时了(并未包含线程 B 刚插入的新结点),线程 A 再做头插法操作,就会抹掉 B 刚刚新增的结点,导致数据丢失。
其实不光是 put() 操作,删除操作、修改操作,同样都会有覆盖问题。
2、扩容时导致死循环(JDK7.0 才有)
只有 JDK7 及以前的版本会存在死循环现象,在 JDK8 中,resize() 方式已经做了调整,使用两队链表,且都是使用的尾插法,及时多线程下,也顶多是从头结点再做一次尾插法,不会造成死循环。而 JDK7 能造成死循环,就是因为 resize() 时使用了头插法,将原本的顺序做了反转,才留下了死循环的机会。
过程见: HashMap 扩容时导致的死循环
如何规避 HashMap 的线程不安全?
- Collections.SynchronizedMap()
1
2
3
Map<String, Integer> testMap = new HashMap<>();
// 转为线程安全的map
Map<String, Integer> map = Collections.synchronizedMap(testMap);
- 使用 ConcurrentHashMap
- JDK7.0 Lock+segment 分段锁
- JDK8.0 synchronized
Reference
- JDK7.0下载(Oracle)
- JDK7.0下载(国内镜像)
- HashMap 夺命 14 问,你能坚持到第几问?
https://juejin.cn/post/7077363148281348126 - Java HashMap 工作原理及实现
http://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/ - HashMap 面试题,看这一篇就够了!
https://juejin.cn/post/6844904013909983245 - Java 8 系列之重新认识 HashMap (美团)
https://tech.meituan.com/2016/06/24/java-hashmap.html