Java CAS
CAS
什么是 CAS?
CAS 全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent 包中的原子类就是通过 CAS 来实现了乐观锁。
CAS 指的是 现代 CPU 广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。这个指令会对内存中的共享数据做原子的读写操作。
CAS 是一种乐观锁。
CAS 算法涉及到三个操作数:
- V:需要读写的内存值(Java 中可以简单理解为变量的内存地址)
- A:旧的预期值
- B:要修改的新值
当且仅当 V 的值等于 A 时,CAS 通过原子方式用新值 B 来更新 V 的值(” 比较 + 更新 “ 整体是一个原子操作),否则不会执行任何操作。一般情况下,” 更新 “ 是一个不断重试的操作。
当多个线程同时尝试使用 CAS 更新一个变量时,任何时候只有一个线程可以更新成功,若更新失败,线程会重新进入循环再次进行尝试。上述的处理过程是一个原子操作。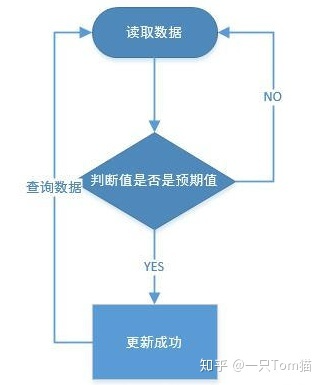
CAS 实现原理?
CAS 是通过 JDK 提供的 UnSafe 实现的,CAS 底层会根据操作系统和处理器的不同来选择对应的调用代码,以 Windows 和 X86 处理器为例,如果是多处理器,通过带 lock 前缀的 cmpxchg 指令对缓存加锁或总线加锁的方式来实现多处理器之间的原子操作;如果是单处理器,通过 cmpxchg 指令完成 比较+更新 原子操作
通过 CPU 的 cmpxchg 指令,去比较寄存器中的 A 和 内存中的值 V。如果相等,就把要写入的新值 B 存入内存中。如果不相等,就将内存值 V 赋值给寄存器中的值 A。然后通过 Java 代码中的 while 循环再次调用 cmpxchg 指令进行重试,直到设置成功为止。
CAS 都是硬件级别的操作,因此效率会比普通的加锁高一些。
CAS 适用场景?
乐观锁 (CAS) 适用于写比较少的情况下(读大于写的情况),而一般多写的场景下用悲观锁比较合适。
CAS 存在的问题?
1、ABA 问题
因为 CAS 需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果这个值被另外一个线程改变了原来是 A,变成了 B,又变成了 A,那么使用 CAS 进行检查时会发现它的值没有发生变化,但是实际上却变化了。
当我们去修改一个值时,另一个线程也去修改这个值,但是修改完之后又修改了回来。
解决:提供了⼀个带有标记的原⼦引⽤类 AtomicStampedReference,它可以通过控制变量值的版本来保证 CAS 的正确性。不过⽬前来说这个类⽐较 “ 鸡肋 “,⼤部分情况下 ABA 问题并不会影响程序并发的正确性,如果需
要解决 ABA 问题,使⽤传统的互斥同步可能会⽐原⼦类更加⾼效。
2、自旋时间长开销大
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。
3、只能保证单个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
- 用 synchronized
- 把多个共享变量合并成一个共享变量来操作,AtomicReference
CAS 和 synchronized 区别?
- CAS 是乐观锁,synchronized 是悲观锁
- CAS 的原理?synchronized 的原理。
CAS 在 Java 中的实现
java.util.concurrent 包完全建立在 CAS 之上的
AtomicInteger
AtomicInteger 这个类的存在是为了满足在高并发的情况下,原生的整形数值自增线程不安全的问题(如 i++ 和 ++i)。
在 JDK5 后,在 java.util.concurrent.atomic 包,多了很多原子处理类。使用非阻塞算法实现并发控制,用于在高并发环境下的高效程序处理,简化同步处理。
什么是 AtomicInteger?
一个提供原子操作的 Integer 的类。在 Java 语言中,++i 和 i++ 操作并不是线程安全的,在使用的时候,不可避免的会用到 synchronized 关键字。而 AtomicInteger 则通过一种线程安全的加减操作接口。
API
- int addAndGet(int delta) 以原子方式将输入的数值与实例中的值(AtomicInteger 里的 value)相加,并返回结果。
- boolean compareAndSet(int expect,int update) 如果输入的数值等于预期值,则以原子方式将该值设置为输入的值。
- int get() 获取当前值
- int getAndSet(int newValue) 以原子方式设置为 newValue 的值,并返回旧值。
- int getAndAdd(int delta) 获取当前值,并加上 delta 的值
- int getAndIncrement() 以原子方式将当前值加 1,注意,这里返回的是自增前的值。
- int getAndDecrement() 获取更新前的值,并原子自减 1
- int incrementAndGet() 原子自增 1,获取更新后的值
- int decrementAndGet() 原子自减 1,获取更新后的值
- void set(int newValue) 设置新值
注意
i++或者++i是线程安全的,那是因为并发量不够高而已- AtomicInteger 类只能保证在自增或者自减的情况下保证线程安全
原理
1
2
3
4
5
6
7
8
9
10
11
12
13
public class AtomicInteger extends Number implements java.io.Serializable {
// setup to use Unsafe.compareAndSwapInt for updates
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
// ...
}
value 使用了 volatile 关键字,可以使多个线程在变量改变时,对其他线程的可见性。但 volatile 使用导致 JVM 失去优化,效率降低。
案例
++操作符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public final class IntValueIncrementTest {
public static int value = 0;
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(1000);
for (int i = 0; i < 10000; i++) {
executorService.execute(() -> {
for (int j = 0; j < 4; j++) {
System.out.println(value++);
}
});
}
executorService.shutdown();
Thread.sleep(3000);
System.out.println("最终结果是" + value);
}
}
结果:
可以看到,每次都达不到 40000
- AtomicInteger
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public final class AtomicInteger2Demo {
public static final AtomicInteger atomicInteger = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
atomicIntegerTest();
Thread.sleep(3000);
System.out.println("最终结果是" + atomicInteger.get());
}
private static void atomicIntegerTest() {
ExecutorService executorService = Executors.newFixedThreadPool(1000);
for (int i = 0; i < 10000; i++) {
executorService.execute(() -> {
for (int j = 0; j < 4; j++) {
System.out.println(atomicInteger.getAndIncrement());
}
});
}
executorService.shutdown();
}
}
结果:
可以看到每次都是 40000
AtomicIntegerArray
主要是提供原子的方式更新数组里的整型
引用类型
原子更新基本类型的 AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic 包提供了以下 3 个类。
AtomicReference 原子更新引用类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/**
* 类说明:演示引用类型的原子操作类
*/
public class UseAtomicReference {
static AtomicReference<UserInfo> atomicUserRef;
public static void main(String[] args) {
UserInfo user = new UserInfo("Mark", 15);//要修改的实体的实例
atomicUserRef = new AtomicReference(user);
UserInfo updateUser = new UserInfo("Bill", 17);
atomicUserRef.compareAndSet(user, updateUser);
System.out.println(atomicUserRef.get()); // UserInfo{name='Bill', age=17}
System.out.println(user); // UserInfo{name='Mark', age=15}
}
//定义一个实体类
static class UserInfo {
private volatile String name;
private int age;
public UserInfo(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "UserInfo{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
}
AtomicStampedReference
利用版本戳的形式记录了每次改变以后的版本号,这样的话就不会存在 ABA 问题了,这就是 AtomicStampedReference 的解决方案。
AtomicStampedReference 是使用 pair 的 int stamp 作为计数器使用,AtomicMarkableReference 的 pair 使用的是 boolean mark。
还是那个水的例子,AtomicStampedReference 可能关心的是动过几次,AtomicMarkableReference 关心的是有没有被人动过,方法都比较简单。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/**
* 类说明:演示带版本戳的原子操作类
*/
public class UseAtomicStampedReference {
static AtomicStampedReference<String> asr
= new AtomicStampedReference("mark", 0);
public static void main(String[] args) throws InterruptedException {
//拿到当前的版本号(旧)
final int oldStamp = asr.getStamp();
final String oldReference = asr.getReference();
System.out.println(oldReference + "============" + oldStamp);
Thread rightStampThread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ":当前变量值:" + oldReference + "-当前版本戳:" + oldStamp + "-"
+ asr.compareAndSet(oldReference, oldReference + "+Java", oldStamp, oldStamp + 1));
}
});
Thread errorStampThread = new Thread(new Runnable() {
@Override
public void run() {
String reference = asr.getReference();
System.out.println(Thread.currentThread().getName() + ":当前变量值:" + reference + "-当前版本戳:" + asr.getStamp() + "-"
+ asr.compareAndSet(reference, reference + "+C", oldStamp, oldStamp + 1));
}
});
rightStampThread.start();
rightStampThread.join();
errorStampThread.start();
errorStampThread.join();
System.out.println(asr.getReference() + "============" + asr.getStamp());
}
}
// 输出
// mark============0
// Thread-0:当前变量值:mark-当前版本戳:0-true
// Thread-1:当前变量值:mark+Java-当前版本戳:1-false
// mark+Java============1
AtomicMarkableReference
原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是 AtomicMarkableReference(V initialRef,booleaninitialMark)
AtomicReference 和 AtomicReferenceFieldUpdater 区别
两者都是利用 UnSafe 提供的 CAS 机制实现在多线程场景下安全的、原子的数据更新操作,区别主要有:
- AtomicReference 是针对一个引用的增删改查做到线程安全
- AtomicReferenceFieldUpdater 是针对一个对象的一个属性的增删改查做到线程安全
- AtomicReferenceFieldUpdater 操作属性的方式是通过反射,按属性名操作
- AtomicReferenceFieldUpdater 比 AtomicReference 更省内存
它们之间的本质在于 AtomicReference 它本身上也是指向⼀个对象的,相⽐ AtomicReferenceFieldUpdater 要多创建⼀个对象,⽽这个对象它的 header 占 12 个字节,它的 Fields 占 4 个字节,这就多出来 16 个字节。当然,这是默认在 32 位的情况下,对于 64 位的机器下,如果我们使⽤
-XX:+UseCompressedOops启动了指针压缩的话,在 Java 中每⼀个引⽤占⽤的还是 4 个字节,同样 Total 还是 16 个字节。如果 64 位时我们没有启⽤这个压缩指针,那么 Fields 就会占⽤ 8 个字节,Header 会占⽤ 16 个字节,Total 会占⽤到 24 个字节。因此 AtomicReference 每创建⼀个实例的时候就会多出这么多内存(16 字
节或 24 字节),如果我们创建成千上万个,那 GC 和内存的压⼒会⾮常⼤。
- 虽然 AtomicReference 相⽐ AtomicReferenceFieldUpdater 使⽤更简单,也没有使⽤反射,但是很多框架都会使⽤后者。
Ref
07 Java的CAS机制(配合volatile,无锁的资源保护),常用API以及背后的unsafe对象 - 狗星 - 博客园
对 CAS 讲解很详细