Java 其他Map
ConcurrentSkipListMap
跳表
对于单链表,即使链表是有序的,如果想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低。
跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整;而对跳表的插入和删除,只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,需要一个全局锁,来保证整个平衡树的线程安全;而对于跳表,则只需要部分锁即可。这样,在高并发环境下,就可以拥有更好的性能。就查询的性能而言,跳表的时间复杂度是 O(logn)
JDK 使用跳表来实现一个 Map。
跳表的本质,是同时维护了多个链表,并且链表是分层的(2 级索引跳表):
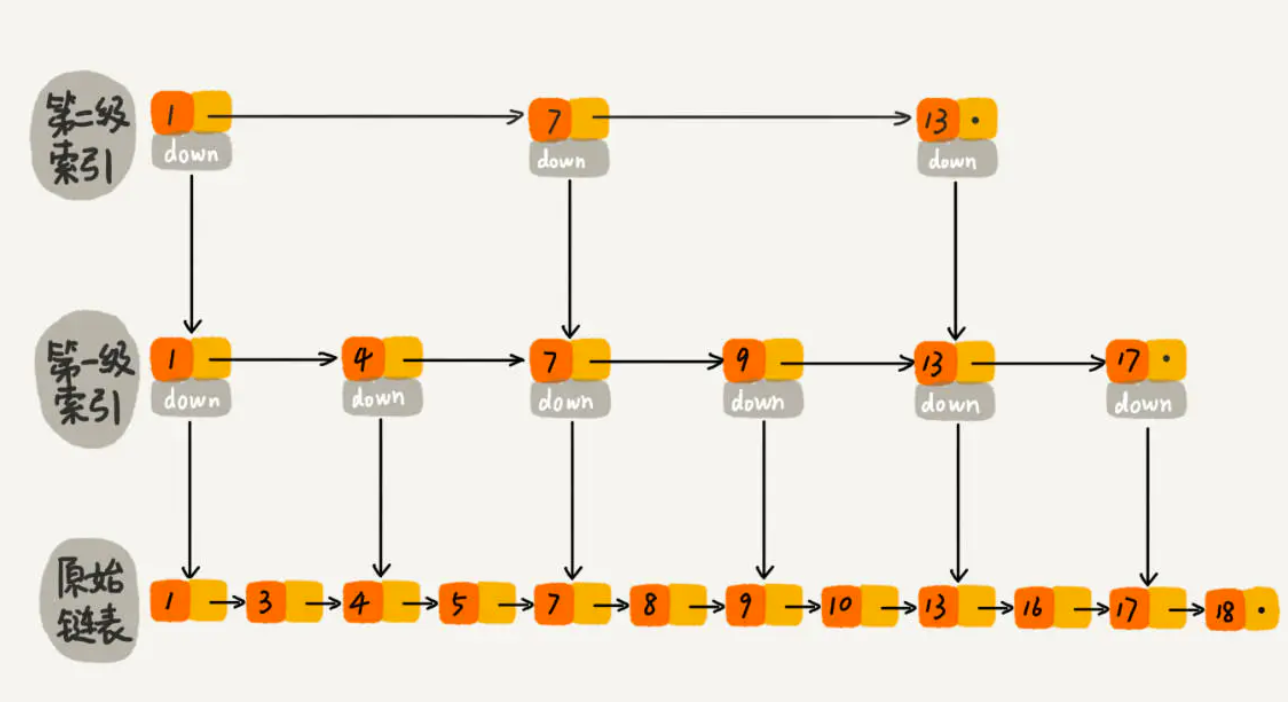
跳表内所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素 18。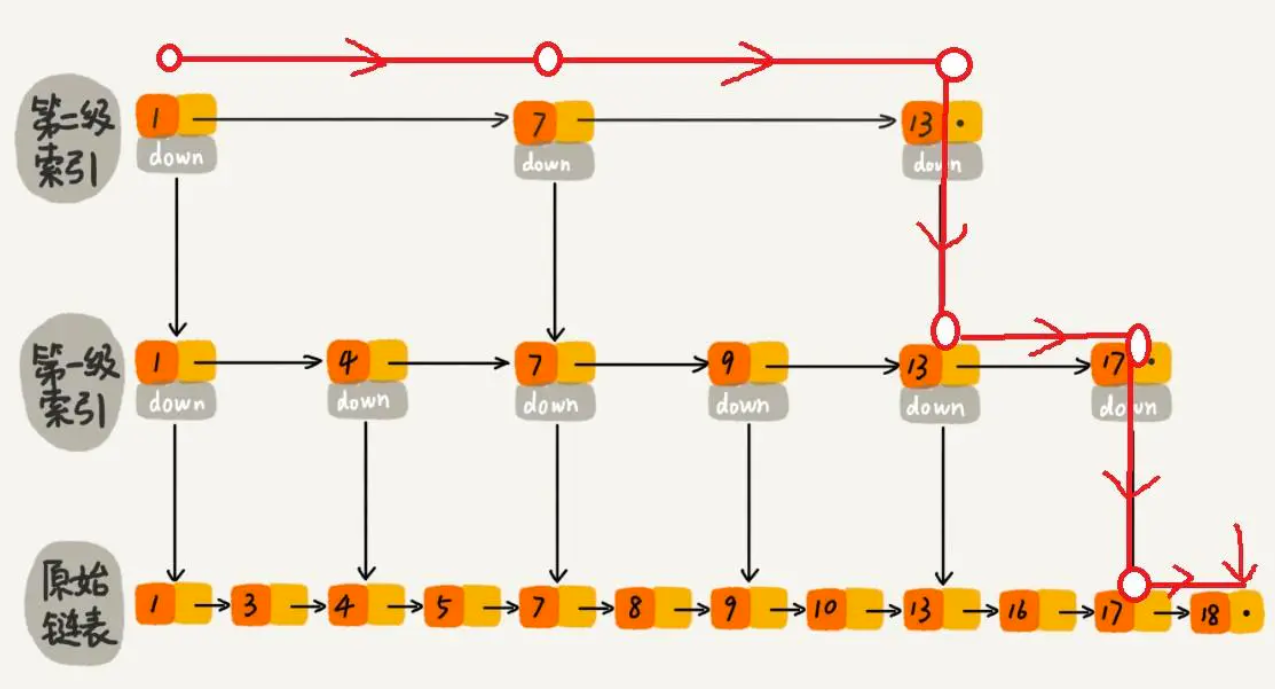
在跳表中查找元素 18
查找 18 的时候,原来需要遍历 18 次,现在只需要 7 次即可。针对链表长度比较大的时候,构建索引,查找效率的提升就会非常明显。
跳表是一种利用空间换时间的算法。
使用跳表实现 Map,和使用哈希算法实现 Map 的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此,在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择,JDK 中实现这一数据结构的类是 ConcurrentSkipListMap。
ConcurrentSkipListMap
ArrayMap 和 SparseMap
ArrayMap
ArrayMap 使用
1
2
3
4
5
6
7
8
9
ArrayMap<String, String> supportArrayMap = new ArrayMap<String, String>(16);
supportArrayMap.put("key", "value");
supportArrayMap.get("key");
supportArrayMap.entrySet().iterator();
SimpleArrayMap<String, String> simpleArrayMap = new SimpleArrayMap<String, String>(16);
simpleArrayMap.put("key", "value");
simpleArrayMap.get("key");
// simpleArrayMap.entrySet().iterator(); <- will not compile
ArrayMap 特点
- 不能保证有序,hash 冲突时在相邻位置插入
- 底层基于数组实现的,key,value 可为任何类型的
- 因为 ArrayMap 存在复用,但要求 hash 数组长度为 4 或 8。因此,尽量将 ArrayMap 的大小指定成 4/8,方便复用
- 这个 ArrayMap 还是没能解决自动装箱的问题。当 put 一对键值对进入的时候,它们只接受 Object,但是我们相对于 HashMap 来说每一次 put 会少创建一个对象 (HashMapEntry)。这是不是值得我们用 O(1) 的查找复杂度来换呢?对于大多数 app 应用来说是值得的。
- 使用 SparseArray 和 ArrayMap 肯定会减少对象创建的数目。
ArrayMap 原理
- ArrayMap 和 SparseArray 有点类似;其中含有两个数组,一个是 mHashes(key 的 hash 值数组,为一个有序数组),另一个数组存储的是 key 和 value,其中 key 和 value 是成对出现的,key 存储在数组的偶数位上,value 存储在数组的奇数位上。
- 通过二分查找 key;key 为任意类型,存在 hash 冲突
- 扩容
ArrayMap 使用场景
- 1000 以内的数量,用 ArrayMap
- key 为 int 用 SparseArray,避免自动装箱;key 为其他类型,就用 ArrayMap
SparseArray
SparseArray 采用时间换取空间的方式来提高手机 App 的运行效率,这也是其与 HashMap 的区别;HashMap 通过空间换取时间,查找迅速;HashMap 中当 table 数组中内容达到总容量 0.75 时,则扩展为当前容量的两倍
SparseArray 特点
- SparseArray 的 key 为 int,value 为 Object。key 不需要装箱
- 默认初始容量为 10
- 不能保证插入的顺序
- 数据长度小于 1000 时,key 为 int 时,可用于替换 HashMap
- 它的数据结构是键值 key 一个数组,value 值一个数组,不像 HashMap,基于 Entry 对 key-value 进行封装再进行读写
- 因为 Int 为 key,所以不会出现 hash 冲突,但依旧存在扩容问题
- 删除时并不会直接移动数组,而是将对应值设置成 DELETED(一个特殊的 object),在合适时机统一处理。减少了数组的移动,提高性能
SparseArray 原理
构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public SparseArray() {
this(10);
}
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = EmptyArray.INT;
mValues = EmptyArray.OBJECT;
} else {
// key value各自为一个数组,默认长度为10
mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);
mKeys = new int[mValues.length];
}
mSize = 0;
}
put(int key, E value)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public void put(int key, E value) {
// 二分查找,key在mKeys列表中对应的index
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
// 如果找到,则直接赋值
if (i >= 0) {
mValues[i] = value;
}
// 找不到
else {
// binarySearch方法中,找不到时,i取了其非,这里再次取非,则非非则正
i = ~i;
// 如果该位置的数据正好被删除,则赋值
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
// 如果有数据被删除了,则gc
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
// 插入数据,增长mKeys与mValues列表
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
其他 SparseXXXArray
- SparseIntArray key 和 value 都是基本数据类型 int,不需要装箱
- SparseLongArray key 和 value 都是基本数据类型 long,不需要装箱
- SparseBooleanArray key 和 value 都是基本数据类型 boolean,不需要装箱