Java并发工具类
原子类
基本类型原子类
AtomicReference
AtomicReferenceFieldUpdater
并发集合类
ConcurrentHashMap
ConcurrentHashMap 原理
- JDK7.0 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组 Segment,每个 Segment 小数组中有 n 个 HashEntry 组成,分段锁。
- JDK8.0 中的 ConcurrentHashMap 选择了与 HashMap 相同的 Node 数组 + 链表 + 红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用 CAS + synchronized 实现更加细粒度的锁。
JDK7.0 和 JDK8.0 ConcurrentHashMap 对比
- 数据结构:JDK7.0 Segment+HashEntry 分段;JDK8.0 取消了 Segment 分段锁的数据结构,取而代之的是数组 + 链表 + 红黑树的结构。
- 保证线程安全机制:JDK7.0 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock;JDK8.0 采用 CAS+synchronized 保证线程安全。
- 锁的粒度:JDK7.0 是对需要进行数据操作的 Segment 加锁,默认并发度 16;JDK8.0 调整为对每个数组元素加锁(Node)。
- 链表适时升级为红黑树:JDK7.0 链表遍历效率低,JDK8.0 会将链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从 JDK7.0 的遍历链表 O(n), JDK8.0 变成遍历红黑树 O(logN)。
CopyOnWrite(写入时复制)
什么是 Copy-On-Write?
当你想要对一块内存进行修改时,我们不在原有的内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后就将指向原来内存的指针指向新的内存,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
什么是 CopyOnWriteArrayList?
CopyOnWriteArrayList 是一个 ArrayList 的线程安全的变体;
优点
- 数据一致性,加锁了,并发数据不会乱
- 解决了 Arraylist、Vector 集合多线程遍历的迭代问题
缺点
- 内存占用问题明显:两个数组同时在内存中,如果数据比较多,比较大的情况下,占用内存会比较大
- 数据一致性:CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性,所以如果你期望写入的数据,马上能读到,不要用 CopyOnWrite 容器。
使用场景
- 读多写少:因为写时会复制新的数组
- 集合不大
- 实时性要求不高,因为在写的过程中,读取的还是旧的数据
哪些 List 是安全的?List 如何选型?
线程安全:
- 读多写少 CopyOnWriteArrayList
- 多少写多 Collections.synchronizedList
- 频繁更新 ConcurrentSkipList
读多写少选哪个集合?
CopyOnWriteList、CopyOnWriteSet
其他工具
CyclicBarrier 栅栏
阻塞当前线程,等待其它线程,所有线程必须同时到达栅栏位置后,才能继续执行,此时也能够触发执行另外⼀个预先设置的线程
- 等待其他线程,且会阻塞当前线程,所有线程必须同时到达栅栏位置后,才能继续进行
- 所有线程到达栅栏处,可以触发执行另外一个预先设置的线程
CyclicBarrier API
1
2
3
4
5
public CyclicBarrier(int parties, Runnable barrierAction) {
}
public CyclicBarrier(int parties) {
}
- parties 指让多少个线程或者任务等待至 barrier 状态;
- barrierAction 为当这些线程都达到 barrier 状态时会执行的内容。
然后 CyclicBarrier 中最重要的方法就是 await 方法,它有 2 个重载版本:
1
2
public int await() throws InterruptedException, BrokenBarrierException { };
public int await(long timeout, TimeUnit unit)throws InterruptedException,BrokenBarrierException,TimeoutException { };
- 第一个版本比较常用,用来挂起当前线程,直至所有线程都到达 barrier 状态再同时执行后续任务;
- 第二个版本是让这些线程等待至一定的时间,如果还有线程没有到达 barrier 状态就直接让到达 barrier 的线程执行后续任务。
案例
假若有若干个线程都要进行写数据操作,并且只有所有线程都完成写数据操作之后,这些线程才能继续做后面的事情,此时就可以利用 CyclicBarrier 了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class Test {
public static void main(String[] args) {
int N = 4;
CyclicBarrier barrier = new CyclicBarrier(N);
for(int i=0;i<N;i++)
new Writer(barrier).start();
}
static class Writer extends Thread{
private CyclicBarrier cyclicBarrier;
public Writer(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程"+Thread.currentThread().getName()+"正在写入数据...");
try {
Thread.sleep(5000); //以睡眠来模拟写入数据操作
System.out.println("线程"+Thread.currentThread().getName()+"写入数据完毕,等待其他线程写入完毕");
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
}catch(BrokenBarrierException e){
e.printStackTrace();
}
System.out.println("所有线程写入完毕,继续处理其他任务...");
}
}
}
Semaphore 信号量
控制某个资源可被同时访问的线程个数。
Exchanger 交互器
当两个线程到达同步点后,互相交换数据,而 exchange 方法就是同步点。
LockSupport
LockSupport 是一个工具类,提供了基本的线程阻塞和唤醒功能,它是创建锁和其他同步组件的基础工具,内部是使用 sun.misc.Unsafe 类实现的。
LockSupport 和使用它的线程都会关联一个许可,park 方法表示消耗一个许可,调用 park 方法时,如果许可可用则 park 方法返回,如果没有许可则一直阻塞直到许可可用。unpark 方法表示增加一个许可,多次调用并不会积累许可,因为许可数最大值为 1。
LockSupport 方法
- park(): 阻塞当前线程,直到 unpark 方法被调用或当前线程被中断,park 方法才会返回。
- park(Object blocker): 同 park() 方法,多了一个阻塞对象 blocker 参数。
- parkNanos(long nanos): 同 park 方法,nanos 表示最长阻塞超时时间,超时后 park 方法将自动返回。
- parkNanos(Object blocker, long nanos): 同 parkNanos(long nanos) 方法,多了一个阻塞对象 blocker 参数。
- parkUntil(long deadline): 同 park() 方法,deadline 参数表示最长阻塞到某一个时间点,当到达这个时间点,park 方法将自动返回。(该时间为从 1970 年到现在某一个时间点的毫秒数)
- parkUntil(Object blocker, long deadline): 同 parkUntil(long deadline) 方法,多了一个阻塞对象 blocker 参数。
- unpark(Thread thread): 唤醒处于阻塞状态的线程 thread。
阻塞对象 blocker 的作用
park、parkNanos、parkUntil 方法都有对应的带阻塞对象 blocker 参数的重载方法。Thread 类有一个变量为 parkBlocker,对应的就是 LockSupport 的 park 等方法设置进去的阻塞对象。
该参数主要用于问题排查和系统监控,在线程 dump 中会显示该参数的信息,有利于问题定位。
分别调用 park() 和 park(Object blocker),然后使用 jstack 查看线程堆栈信息,对比发现后者会多输出一条阻塞对象的信息:
和显式锁、隐式锁等待唤醒的区别
- park 和 unpark 方法的调用不需要获取锁
- 先调用 unpark 方法后调用 park 方法依然可以唤醒
- park 方法响应中断,线程被中断后 park 方法直接返回,但是不会抛 InterruptedException 异常。
- unpark 方法是直接唤醒指定的线程。
Fork/Join
java.util.concurrent.ForkJoinPool 由 Java 大师 Doug Lea 主持编写,它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。
Unsafe
Unsafe 提供的功能
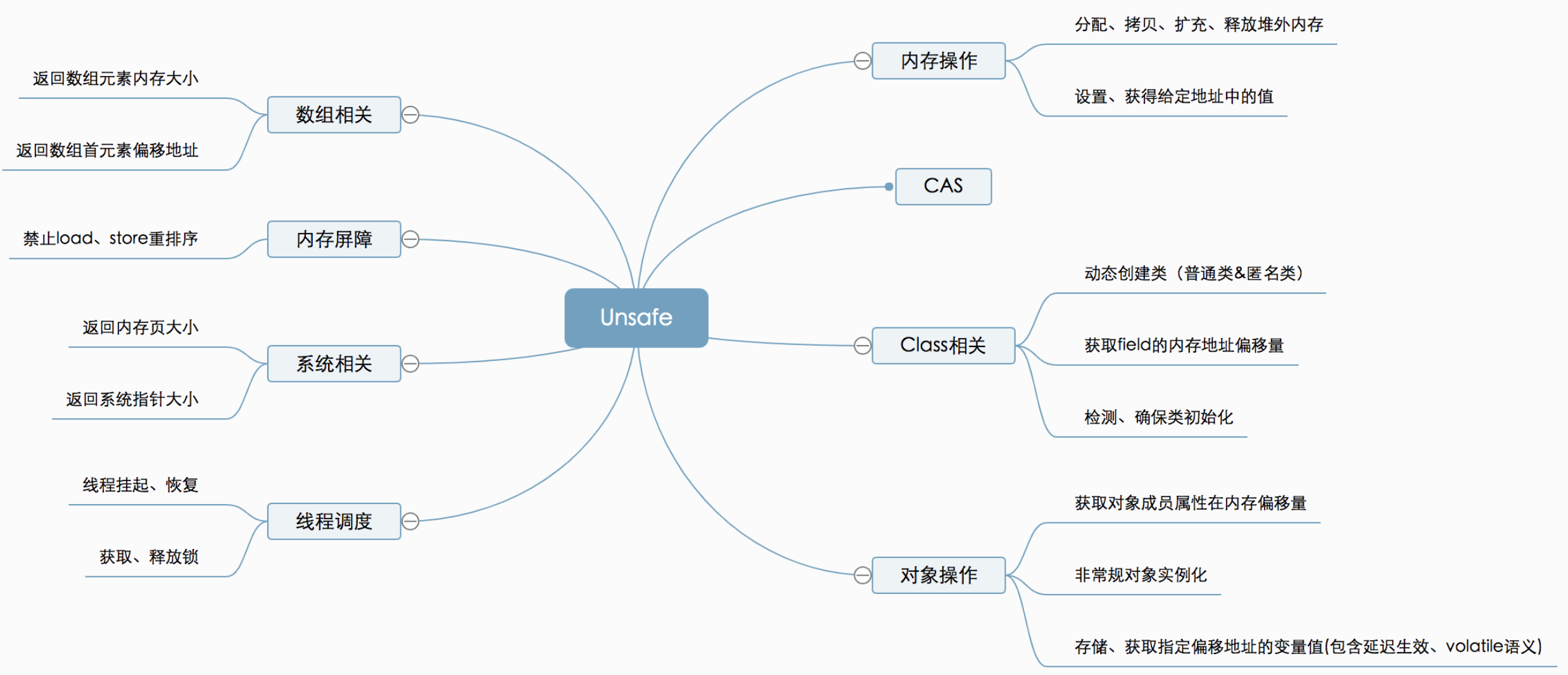
Unsafe 提供了 8 大功能,我们主要关注:
- 对象操作
- CAS
- 线程挂起/唤醒
Unsafe 操作对象
CAS
- public final boolean compareAndSwapInt(Object o, long offset, int expected, int x) 比较和交换一个整形值,是一个原子操作,由 CPU 保证,指令 cmpxchg 完成
- o 表示当前需要改变的变量 a 所在的对象 (假设要改变的变量名为 a)
- offset 表示当前需要改变的变量 a 在 o 里的偏移量
- expected 表示 a 当前的预期值
- x 表示要更改 a 的值为 x
返回值:true 表示更改成功
Unsafe 实例化对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
/**
* Do sneaky things to allocate objects without invoking their constructors.
*
* @author Joel Leitch
* @author Jesse Wilson
*/
public abstract class UnsafeAllocator {
public abstract <T> T newInstance(Class<T> c) throws Exception;
public static UnsafeAllocator create() {
// try JVM
// public class Unsafe {
// public Object allocateInstance(Class<?> type);
// }
try {
Class<?> unsafeClass = Class.forName("sun.misc.Unsafe");
Field f = unsafeClass.getDeclaredField("theUnsafe");
f.setAccessible(true);
final Object unsafe = f.get(null);
final Method allocateInstance = unsafeClass.getMethod("allocateInstance", Class.class);
return new UnsafeAllocator() {
@Override
@SuppressWarnings("unchecked")
public <T> T newInstance(Class<T> c) throws Exception {
assertInstantiable(c);
return (T) allocateInstance.invoke(unsafe, c);
}
};
} catch (Exception ignored) {
}
// try dalvikvm, post-gingerbread
// public class ObjectStreamClass {
// private static native int getConstructorId(Class<?> c);
// private static native Object newInstance(Class<?> instantiationClass, int methodId);
// }
try {
Method getConstructorId = ObjectStreamClass.class
.getDeclaredMethod("getConstructorId", Class.class);
getConstructorId.setAccessible(true);
final int constructorId = (Integer) getConstructorId.invoke(null, Object.class);
final Method newInstance = ObjectStreamClass.class
.getDeclaredMethod("newInstance", Class.class, int.class);
newInstance.setAccessible(true);
return new UnsafeAllocator() {
@Override
@SuppressWarnings("unchecked")
public <T> T newInstance(Class<T> c) throws Exception {
assertInstantiable(c);
return (T) newInstance.invoke(null, c, constructorId);
}
};
} catch (Exception ignored) {
}
// try dalvikvm, pre-gingerbread
// public class ObjectInputStream {
// private static native Object newInstance(
// Class<?> instantiationClass, Class<?> constructorClass);
// }
try {
final Method newInstance = ObjectInputStream.class
.getDeclaredMethod("newInstance", Class.class, Class.class);
newInstance.setAccessible(true);
return new UnsafeAllocator() {
@Override
@SuppressWarnings("unchecked")
public <T> T newInstance(Class<T> c) throws Exception {
assertInstantiable(c);
return (T) newInstance.invoke(null, c, Object.class);
}
};
} catch (Exception ignored) {
}
// give up
return new UnsafeAllocator() {
@Override
public <T> T newInstance(Class<T> c) {
throw new UnsupportedOperationException("Cannot allocate " + c);
}
};
}
/**
* Check if the class can be instantiated by unsafe allocator. If the instance has interface or abstract modifiers
* throw an {@link java.lang.UnsupportedOperationException}
* @param c instance of the class to be checked
*/
static void assertInstantiable(Class<?> c) {
int modifiers = c.getModifiers();
if (Modifier.isInterface(modifiers)) {
throw new UnsupportedOperationException("Interface can't be instantiated! Interface name: " + c.getName());
}
if (Modifier.isAbstract(modifiers)) {
throw new UnsupportedOperationException("Abstract class can't be instantiated! Class name: " + c.getName());
}
}
}
使用:
1
2
3
4
5
6
7
8
9
10
11
fun main() {
val unsafeAllocator = UnsafeAllocator.create()
try {
val obj = unsafeAllocator.newInstance(Person::class.java)
obj.name = "hacket"
println(obj)
} catch (e: Exception) {
throw RuntimeException("Unable to invoke no-args constructor for " + Person::class.java + ". "
+ "Registering an InstanceCreator with Gson for this type may fix this problem.", e)
}
}
线程挂起/唤醒
Unsafe.java 里有两个方法:park 和 unpark
1
2
3
4
5
6
7
8
9
10
#Unsafe.java
//调用该方法的线程会挂起
//isAbsolute--->是否使用绝对时间,会影响time的单位
//time--->指定最多挂起多长的时间
//isAbsolute=true -->绝对时间,则time单位为毫秒,表示线程将被挂起到time这个时间点
//isAbsolute=false--->相对时间,则time单位为纳秒,如time =1000表示线程将被挂起1000纳秒
public native void park(boolean isAbsolute, long time);
//唤醒线程,thread表示待唤醒的线程
public native void unpark(Object thread);
Ref
面试题
ConcurrentHashMap 面试题
ConcurrentHashMap 默认初始容量是多少?
16:private static final int DEFAULT_CAPACITY = 16;
JDK8.0 ConcurrentHashMap 做了什么改进?
JDK7.0 实现
JDK7.0 版本,ConcurrentHashMap 由 Segment 数组 +HashEntry 数组 + 分段锁实现。其内部分为一个个 Segment 数组,Segment 继承 ReentrantLock,通过锁住每一个 Segment 来降低锁的粒度。
JDK7.0 实现的不足
- 每次通过 hash 确认位置时需要 2 次才能定位到当前 key 应该落在哪个槽
- 通过
hash值和段数组长度-1进行位运算确认当前 key 属于哪个段,即确认其在 segments 数组的位置 - 再次通过
hash值和table数组(ConcurrentHashMap底层存储数据的数组)长度-1进行位运算确认其所在桶
- 通过
JDK8.0 实现
- JDK8.0 ConcurrentHashMap 的实现和 HashMap 实现基本一致:数组 + 链表/红黑树,支持比 HashMap 多了锁保证线程安全
- 取消了分段锁的设计,取而代之的是通过 CAS+synchronized 来实现加锁
为什么 key 和 value 不允许为 null?
在 HashMap 中,key 和 value 都是可以为 null 的,但是在 ConcurrentHashMap 中却不允许。
为什么不允许 null 值?
作者 Doug Lea 本身对这个问题有过回答,在并发编程中,null 值容易引来歧义, 假如先调用 get(key) 返回的结果是 null,那么我们无法确认是因为当时这个 key 对应的 value 本身放的就是 null,还是说这个 key 值根本不存在,这会引起歧义,如果在非并发编程中,可以进一步通过调用 containsKey 方法来进行判断,但是并发编程中无法保证两个方法之间没有其他线程来修改 key 值,所以就直接禁止了 null 值的存在。总结:允许 null 值容易引起二义性,是这个 key 不存在还是 key 存在存放的值为 null 呢?这就需要进一步通过 containsKey 确认,如果在单线程环境下没问题,如果是多线程环境下,可能存在 get(key) 后 containsKey() 前有其他的线程 put(key, null),假设真实是这个 key 不存在,这样实际拿到的结果是 key 存在值为 null,就与我们真实情况不一致了,有了二义性,干脆就禁止了 null 值
为什么不允许 null 键?
作者 Doug Lea 本身也认为,假如允许在集合,如 map 和 set 等存在 null 值的话,即使在非并发集合中也有一种公开允许程序中存在错误的意思,这也是 Doug Lea 和 Josh Bloch(HashMap 作者之一) 在设计问题上少数不同意见之一,而 ConcurrentHashMap 是 Doug Lea 一个人开发的,所以就直接禁止了 null 值的存在。总结一句话就是 Doug Lea 不喜欢 null 键。
ConcurrentHashMap 如何计数的?
在 HashMap 中,调用 put 方法之后会通过 ++size 的方式来存储当前集合中元素的个数,但是在并发模式下,这种操作是不安全的,所以不能通过这种方式,那么是否可以通过 CAS 操作来修改 size 呢?
直接通过 CAS 操作来修改 size 是可行的,但是假如同时有非常多的线程要修改 size 操作,那么只会有一个线程能够替换成功,其他线程只能不断地尝试 CAS,这会影响到 ConcurrentHashMap 集合的性能,所以作者就想到了一个分而治之的思想来完成计数。
作者定义了一个CounterCell数组来计数,而且这个用来计数的数组也能扩容,每次线程需要计数的时候,都通过随机的方式获取一个数组下标的位置进行操作,这样就可以尽可能的降低了锁的粒度,最后获取 size 时,则通过遍历数组来实现计数:
1
2
3
4
5
6
// 用来计数的数组,大小为2的N次幂,默认为2
private transient volatile CounterCell[] counterCells;
@sun.misc.Contended static final class CounterCell { // 数组中的对象
volatile long value; // 存储元素个数
CounterCell(long x) { value = x; }
}
ConcurrentHashMap 如何扩容?扩容多少
ConcurrentHashMap 扩容也支持多线程同时进行。
在 ConcurrentHashMap 中采用的是分段扩容法,即每个线程负责一段,默认最小是 16,也就是说如果 ConcurrentHashMap 中只有 16 个槽位,那么就只会有一个线程参与扩容。如果大于 16 则根据当前 CPU 数来进行分配,最大参与扩容线程数不会超过 CPU 数。扩容空间和 HashMap 一样,每次扩容都是将原空间大小左移 一 位 ,即扩大为之前的两倍。
ConCurrentHashmap 每次扩容是原来容量的 2 倍
ConcurrentHashMap 的 get 方法是否要加锁,为什么?
get 方法不需要加锁。
- JDK8.0 因为 Node 的元素 value 和指针 next 是用 volatile 修饰的,在多线程环境下线程 A 修改节点的 value 或者新增节点的时候是对线程 B 可见的。
1
2
3
4
5
6
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val; // volatile修饰的,保证可见性
volatile Node<K,V> next; // volatile修饰的,保证可见性
}
- JDK7.0 的 HashEntry 的 value 和 next 也都是 volatile,保证了可见性
这也是它比其他并发集合比如 Hashtable、用 Collections.synchronizedMap() 包装的 HashMap 效率高的原因之一。
JDK7.0 get 方法不需要加锁与 volatile 修饰的哈希桶数组有关吗?
没有关系。哈希桶数组 table 用 volatile 修饰主要是保证在数组扩容的时候保证可见性。
1
2
3
4
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 存放数据的桶
transient volatile HashEntry<K,V>[] table;
}
ConcurrentHashMap 迭代器是强一致性还是弱一致性?HashMap 呢?
ConcurrentHashMap 弱一致性,HashMap 强一直性。
ConcurrentHashMap 可以支持在迭代过程中,向 map 添加新元素,而 HashMap 则抛出了 ConcurrentModificationException,因为 HashMap 包含一个修改计数器,当你调用他的 next() 方法来获取下一个元素时,迭代器将会用到这个计数器。
ConcurrentHashmap、HashTable 和 HashMap 区别
- HashMap 是非线程安全的,而 HashTable 和 ConcurrentHashmap 都是线程安全的
- HashMap 的 key 和 value 均可以为 null;而 HashTable 和 ConcurrentHashMap 的 key 和 value 均不可以为 null
- HashTable 和 ConcurrentHashMap 的区别:保证线程安全的方式不同
- HashTable 是通过给整张散列表加锁的方式 (锁加在 get/put 方法上) 来保证线程安全,读写锁共用一把锁,这种方式保证了线程安全,但是并发执行效率低下。
- ConcurrentHashMap 在 JDK1.8 之前,采用分段锁机制来保证线程安全的,这种方式可以在保证线程安全的同时,一定程度上提高并发执行效率 (当多线程并发访问不同的 segment 时,多线程就是完全并发的,并发执行效率会提高)
ConcurrentHashMap JDK7.0 和 JDK8.0 的区别?
- 数据结构:JDK8.0 取消了 Segment 分段锁的数据结构,取而代之的是数组 + 链表 + 红黑树的结构。
- 保证线程安全机制:JDK7.0 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock 。JDK8.0 采用 CAS+synchronized 保证线程安全。
- 锁的粒度:JDK7.0 是对需要进行数据操作的 Segment 加锁,默认并发度 16,JDK8.0 调整为对每个数组元素加锁(Node)。
- 定位优化:JDK7.0 链表遍历效率低,JDK8.0 会将链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从 JDK7.0 的遍历链表 O(n), JDK8.0 变成遍历红黑树 O(logN)。
ConcurrentHashMap 的并发度是什么?
并发度可以理解为程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数。
JDK7.0:默认 16
在 JDK1.7 中,实际上就是 ConcurrentHashMap 中的分段锁个数,即 Segment[] 的数组长度,默认是 16,这个值可以在构造函数中设置。
如果自己设置了并发度,ConcurrentHashMap 会使用大于等于该值的最小的 2 的幂指数作为实际并发度,也就是比如你设置的值是 17,那么实际并发度是 32。
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache 命中率会下降,从而引起程序性能下降。
JDK8.0:table 数组大小,默认也是 16
在 JDK8.0 中,已经摒弃了 Segment 的概念,选择了 Node 数组 + 链表 + 红黑树结构,并发度大小依赖于数组的大小。
多线程下安全操作 Map 还有其他方式吗?
还可以使用 Collections.synchronizedMap 方法,对方法进行加同步锁。
如果传入的是 HashMap 对象,其实也是对 HashMap 做的方法做了一层包装,里面使用对象锁来保证多线程场景下,线程安全,本质也是对 HashMap 进行全表锁。在竞争激烈的多线程环境下性能依然也非常差,不推荐使用!