HPROF文件及工具使用
hprof 基础
什么 hprof 文件?
hprof 是由 JVM TI Agent HPROF 生成的一种二进制堆转储格式,hprof 文件保存了当前 Java 堆上所有的内存使用信息,能够完整的反映虚拟机当前的内存状态。
保存的对象信息和依赖关系是静态分析内存泄漏的关键。
如何抓取 hprof 文件
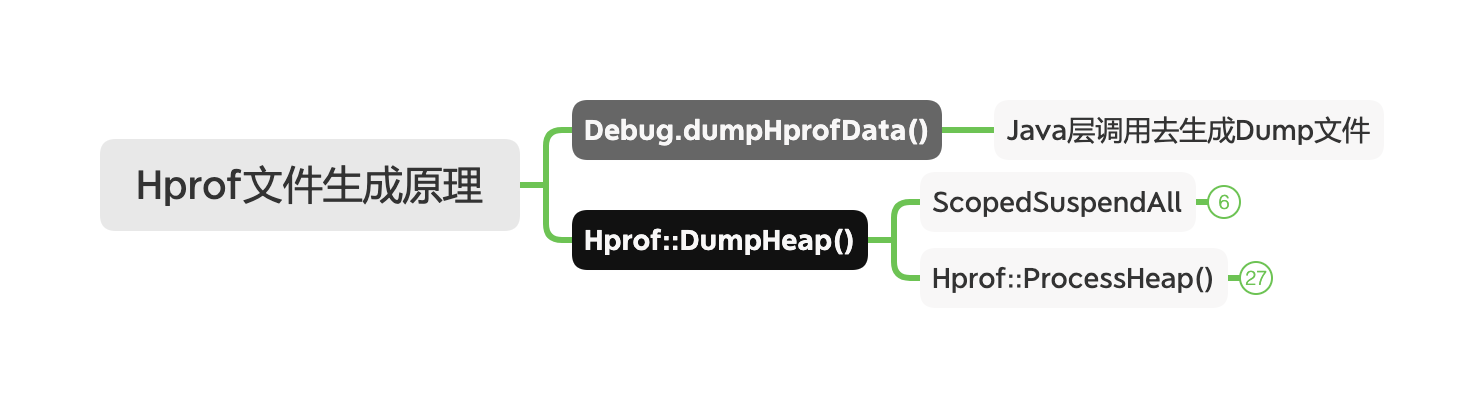
1. Debug.dumpHprofData(path)
但这个 dump 过程会 suspend 所有的 Java 线程,导致用户界面无响应很久,所以不能随意 dump;所以 LeakCanary 采用了预判的方式:在 onDestroy 先检测一下当前 Activity 是否存在泄漏的风险,如果有这种情况,就开始 dump,需要注意的是在 onDestroy 做检测仅仅是预判,并不能断定真正发生了泄漏,真正的泄漏需要通过分析 hprof 文件才能知晓
dump 原理?
2. adb 命令行
adb shell am dumpheap pid /data/local/tmp/x.hprof 生成指定进程的 hprof 文件到目标目录
https://juejin.cn/post/6867335105322188813
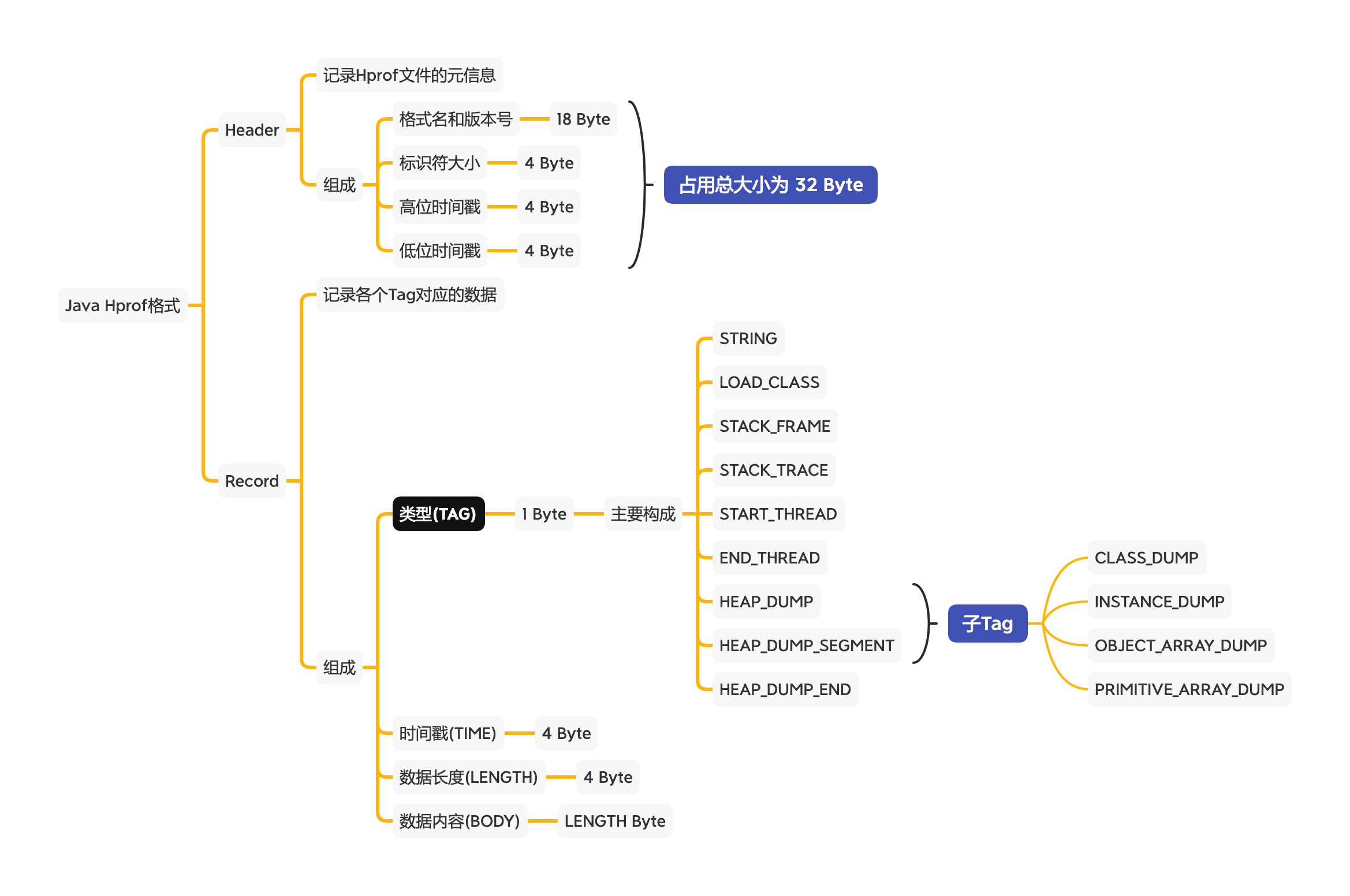
hprof 文件格式
Java hprof
Android hprof
Android 在 Java 的基础上新增了部分 Tag。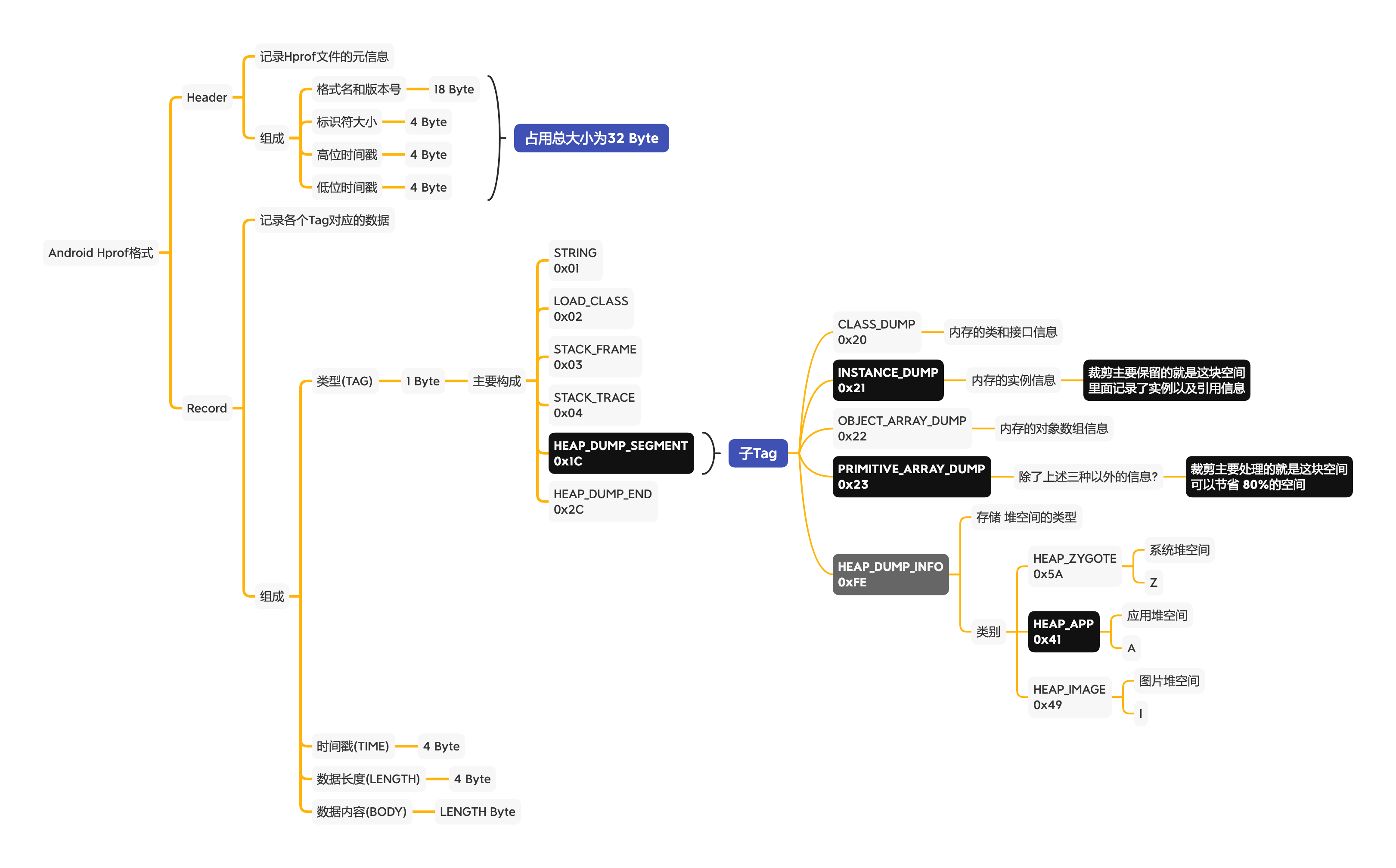
hprof 中一些术语
Allocations:堆中的实例数
Shallow Size
对象自身占用的内存大小,包含它的成员变量所占用大小,不包括它引用的对象大小
- 对于非数组类型的对象,它的大小就是对象本身与它所有成员变量大小的总和
- 对于数组类型的对象,它的大小是数组元素对象大小的总和
Shallow Size = 类定义 + 属性占用空间 + 位数对齐
64 位机器:
- 类定义:声明一个类本身所需的空间,固定为 8 个字节。类定义空间不会重复计算,即使类继承了其他类,也只算 8 个字节。定义了一个没有任何属性的类,查看其 Shallow Size 大小为 8 个字节。
- 属性占用空间:所有属性所占空间之和,包括自身的和父类的所有属性。属性分为基本类型和引用,如 int 类型占 4 个字节,long 类型占 8 个字节,引用固定 (String, Reference) 占 4 个字节。
- 位数对齐:使总空间为 8 的倍数。比如某个类以上两项共 21 字节,那么为了对齐,会取最接近 8 的倍数的值,即它的 Shallow Size 是 24 个字节。与系统有关,有的不会对齐。
案例: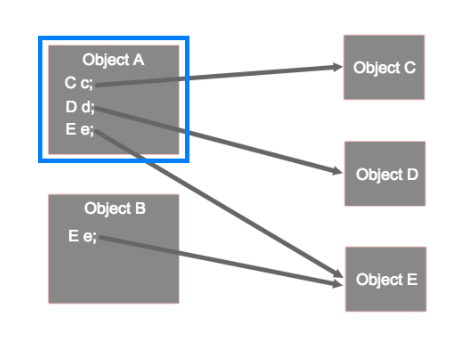
Object A 的 Shallow Size:Object A+c、d、e 属性占用大小 (不包括引用对象的大小)
1
2
3
4
5
6
7
8
9
10
11
// Shallow Size = 28 = 8 + 4 + 8 + 4 + 4,没有位数对齐
// Retained Size = 36 = 28 + 8
data class Resource( // 8B
val int: Int, // 4B
val long: Long, // 8B
val string: String, // 4B
val reference: Res // 4B
)
// Shallow Size = 8
class Res()
Retained Size GC 后能释放多少内存大小
Retained Size 是指某个实例被回收时,可以同时被回收的实例的 Shallow Size 之和;被其他所引用的对象不会被回收的不算进去
Retained Size 就是当前对象被 GC 后,从 Heap 上总共能释放掉的内存,需要排除被其他 GC Roots 直接或间接引用的对象
因此在进行内存分析时,我们需要重点关注 Retained Size 较大的实例;
也可以通过 Retained Size 判断出某个实例内部使用的实例是否被其他实例引用,比如说如果某个实例的 Retained Size 比较小,Shallow Size 比较大,说明它内部使用的某个实例还在其他地方被引用了 (比如说对 Bitmap 实例而言,如果它的 Retained Size 很小,可以说明它内部的 byte 数组被另外的 Bitmap 实例复用了)。
实例 A 的 Retained Size 是指, 当实例 A 被回收时,可以同时被回收的实例的 Shallow Size 之和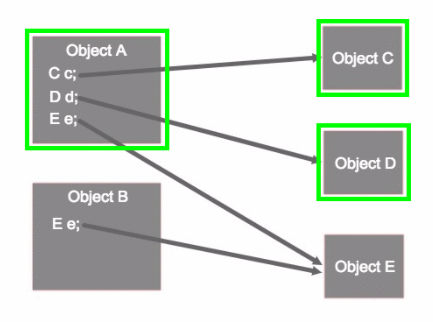
Object A 的 Retained Size=ObjectA 的大小和 c、d、e 引用对象的大小,但 e 引用对象的大小不会被算入,因为该对象被 ObjectB 引用着,不能被 GC
一个 ArrayList 对象持有 100 个对象,每一个占用 16 bytes,如果这个 list 对象被回收,那么其中 100 个对象也可以被回收,可以回收 16*100 + X 的内存,X 代表 ArrayList 的 shallow 大小。
Retained Heap 可以更精确的反映一个对象实际占用的大小
native size
native size:Android8.0 之后的手机会显示,主要反应 Bitmap 所使用的像素内存(8.0 之后,转移到了 native)
hprof 文件查看
Android Studio Profiler Memory
Profiler Memory 使用
有 2 个内存泄漏: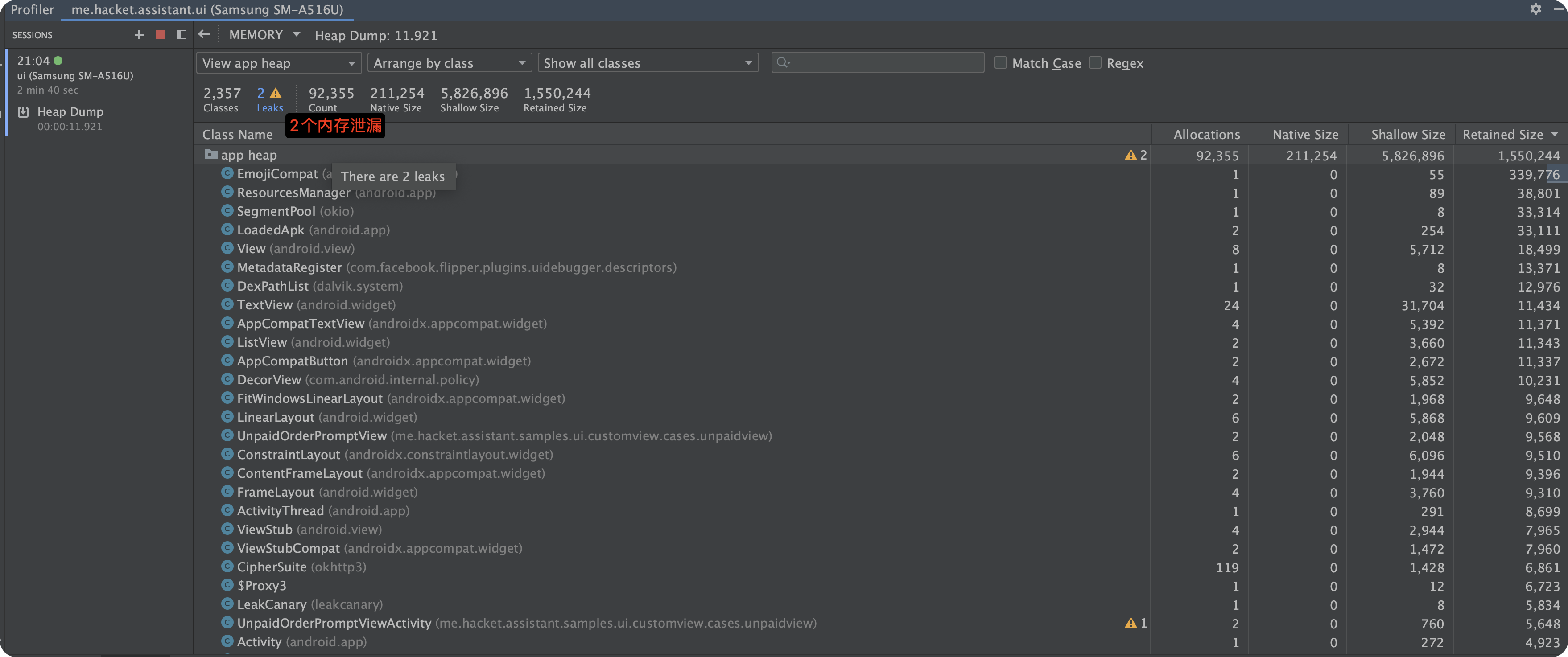
查看内存泄漏引用链条: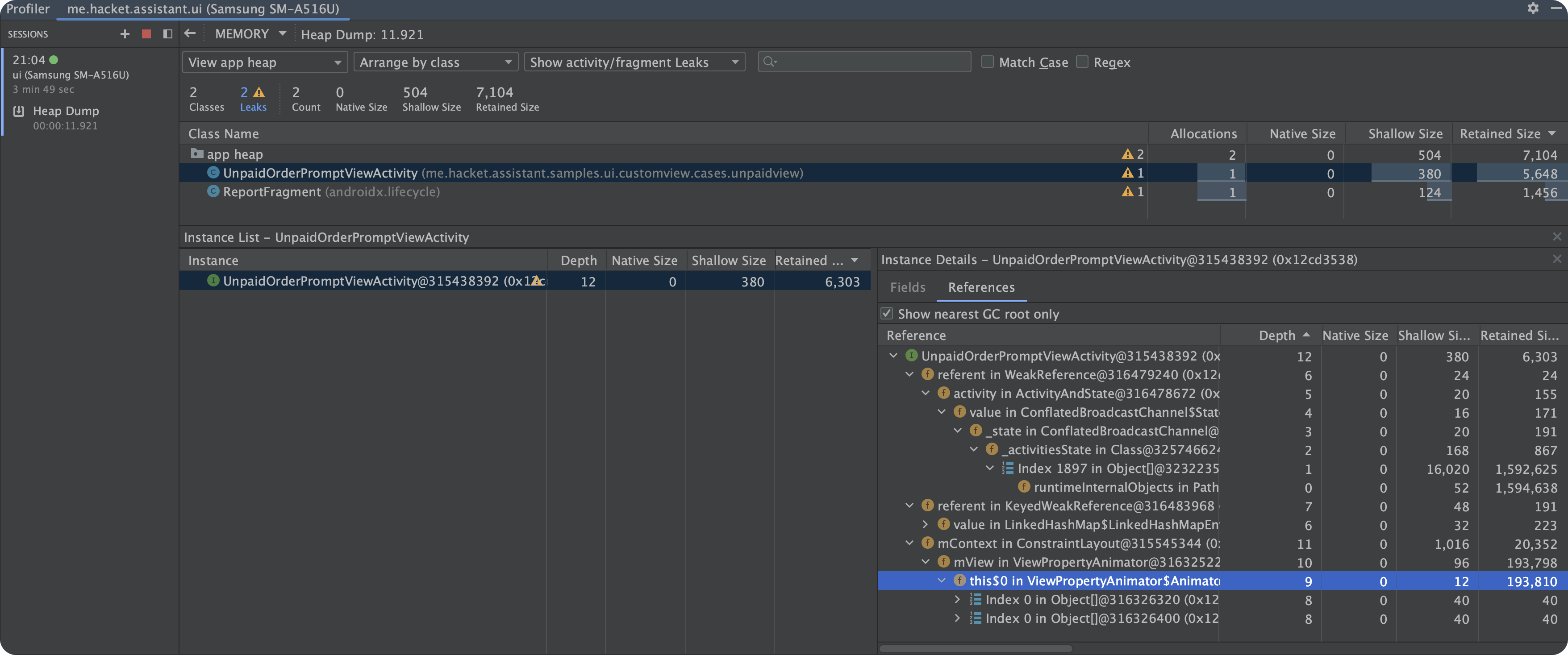
Profiler Memory 查看 HPROF 文件
Android Studio 的 Profiler 工具支持 hprof 的解析,并且很智能的提示当前 leak 了哪些对象,打开方式很简单,将 hprof 文件拖拽至 as,然后双击 hprof 文件即可: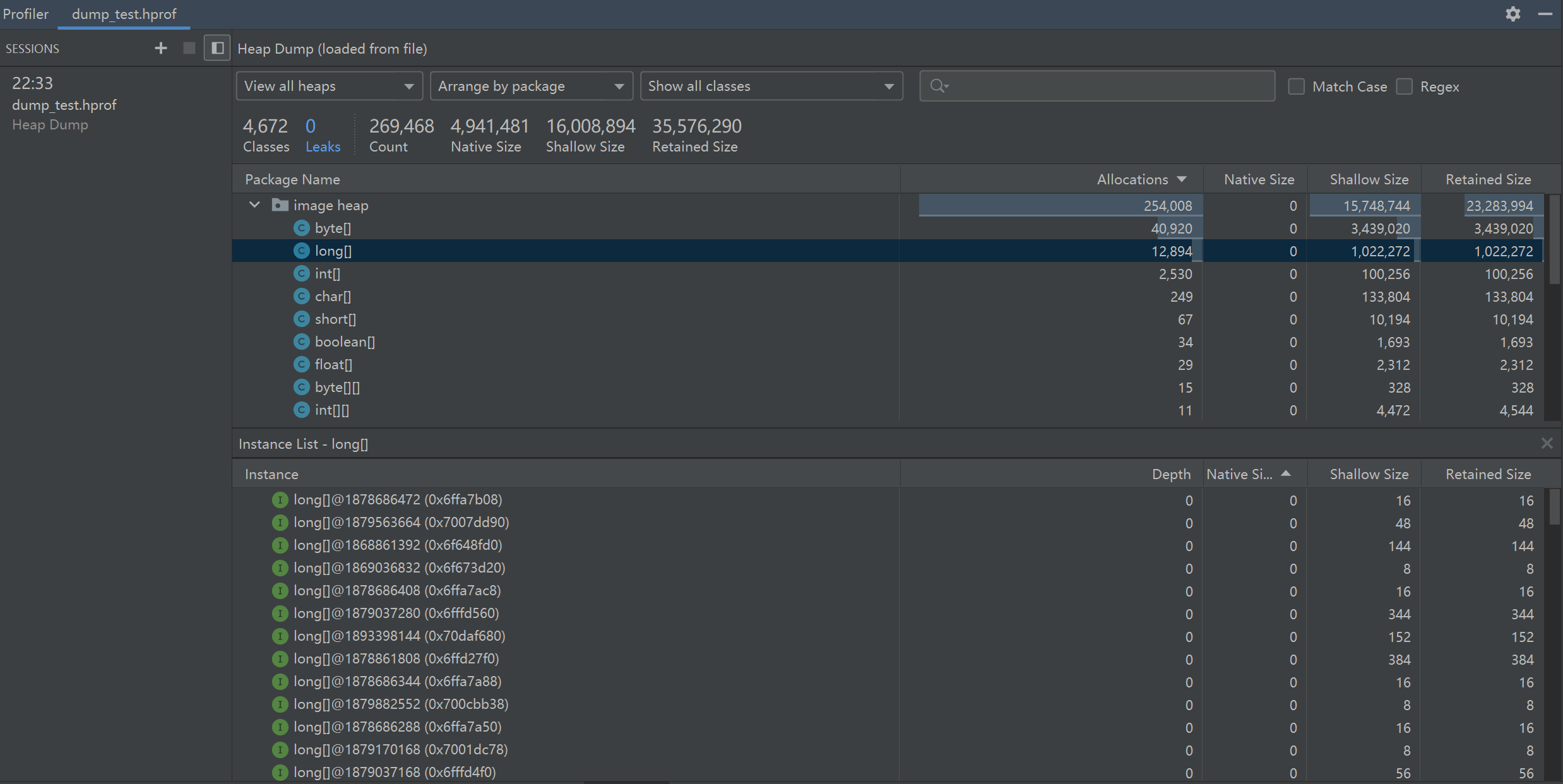
从左侧的菜单中,选择需检查的堆:
- default heap:当系统未指定堆时。
- image heap:系统启动映像,包含启动期间预加载的类。此处的分配确保绝不会移动或消失。
- zygote heap:写时复制堆,其中的应用进程是从 Android 系统中派生的。
- app heap:您的应用在其中分配内存的主堆。
- JNI heap:显示 Java 原生接口 (JNI) 引用被分配和释放到什么位置的堆。
从右侧的菜单中,选择如何安排分配:
- Arrange by class:根据类名称对所有分配进行分组。这是默认值。
- Arrange by package:根据软件包名称对所有分配进行分组。
- Arrange by callstack:将所有分配分组到其对应的调用堆栈。
如果我们的需求仅仅只是在开发阶段进行内存泄漏检测的话,并且又不想接入 LeakCanary(因为有时候想调试下自己模块的代码,其他模块经常报内存泄漏,冻结当前线程,很影响调试),那么我们可以在应用里面埋个彩蛋,比如单击 5 次版本号,然后调用 Debug.dumpHprofData ,然后将 hprof 文件导出到 as 进行分析,这就将原本可能会进行数次 dump 的过程,改成了自己需要去检测的时候再去 dump。
MAT
什么是 MAT?
Memory Analyzer 工具,简称:MAT 。MAT 是 Eclipse 下的一个软件,专门用来分析 Java 内存堆。
MAT 可以打开 ` .hprof ,但是从 Android 里面的导出的 .hprof 文件,MAT 是不支持查看的,所以需要转化一下,Android SDK 自带了转化工具。android_sdk/platform-tools/ 目录中提供的 hprof-conv 工具执行此操作:hprof-conv 源hprof文件 转换后hprof文件`
hprof-conv heap-original.hprof heap-converted.hprof
MAT 功能介绍
MAT 分析 HPROF 文件:
- File→Open File 打开 hprof 文件
- 在弹出的对话框,选择默认,Leak Suspects Report,可以帮我们分析内存泄漏
- 打开的页面
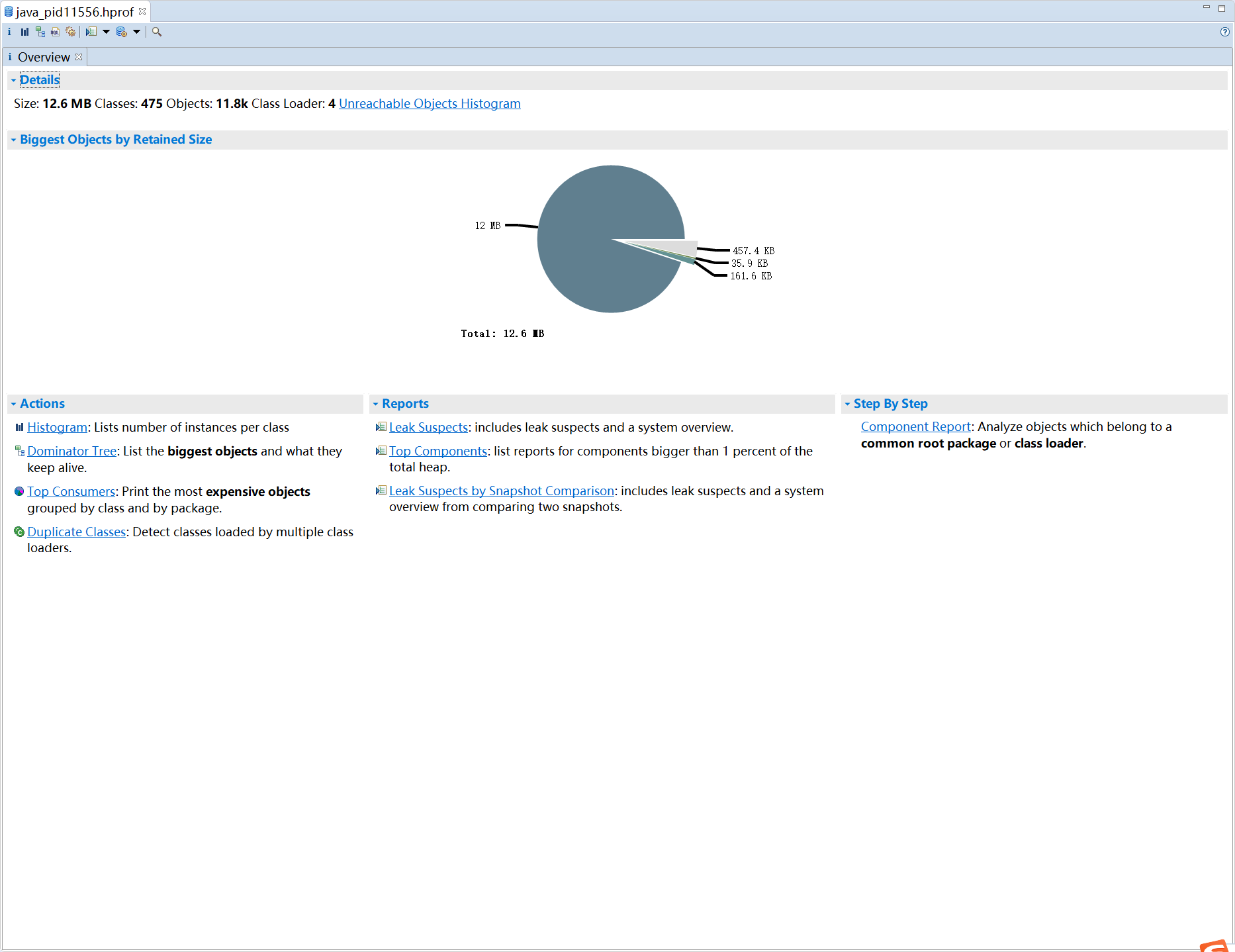
Overview 下功能解释
Overview 页签下分别包含了:Actions,Reports,Step By Step 三大块功能;
- Shallow Heap 对象本身大小,不包含其引用的对象大小,包含其成员变量的大小;数组的话是其成员的大小总和
- Retained Heap 当前对象的大小 + 当前对象直接或间接引用到的对象大小(回收当前对象可以回收多少内存,需要排除被当前对象引用但被 GC Roots 直接或间接引用的对象,导致回收不了)
Actions
- Histogram 列举每个类所对应的对象个数及所占用的内存大小
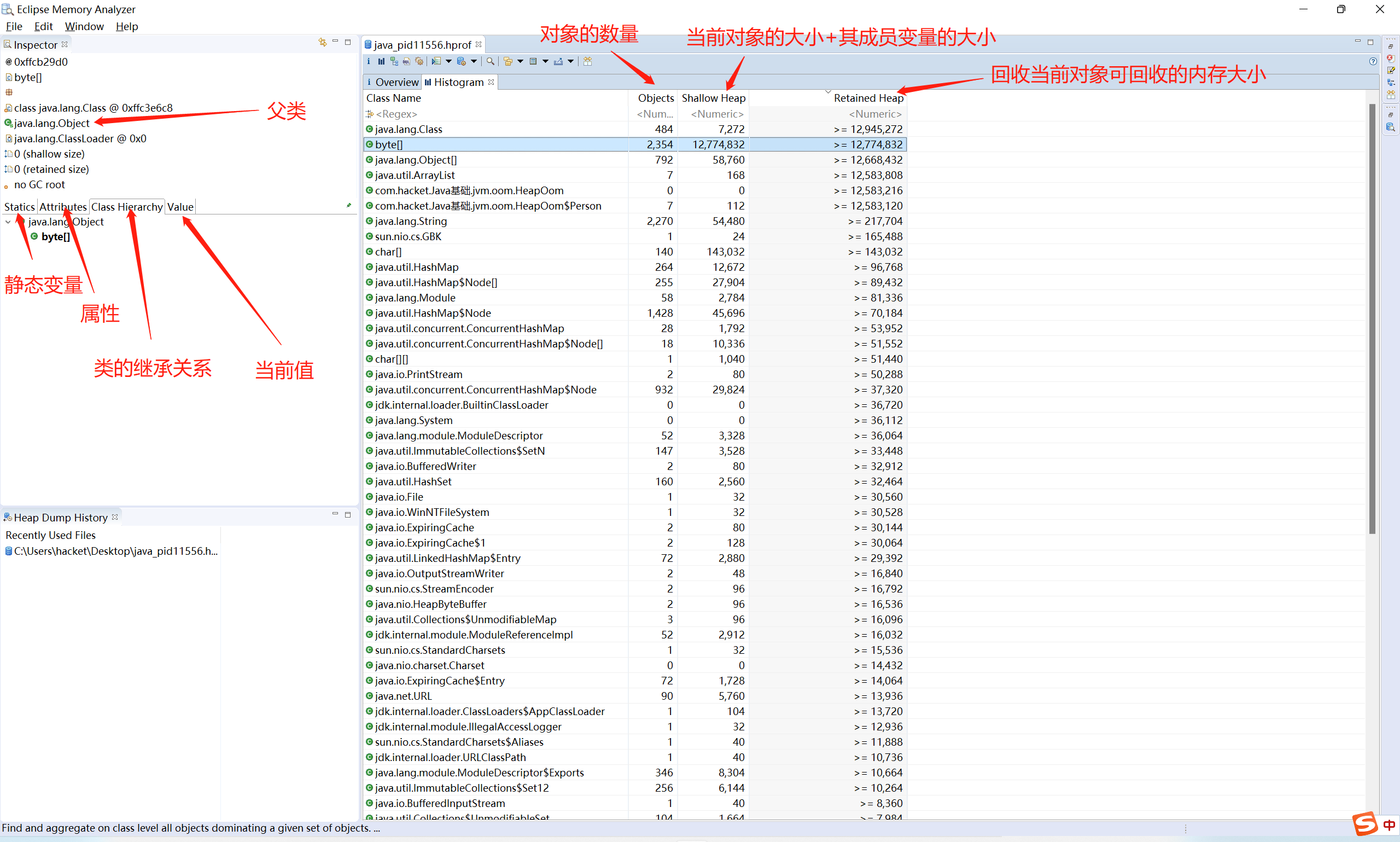
- Dominator Tree 以占用总内存的百分比的方式列举出所有的实例对象(列举出的对应的对象而不是类,这个视图是用来发现大内存对象的)
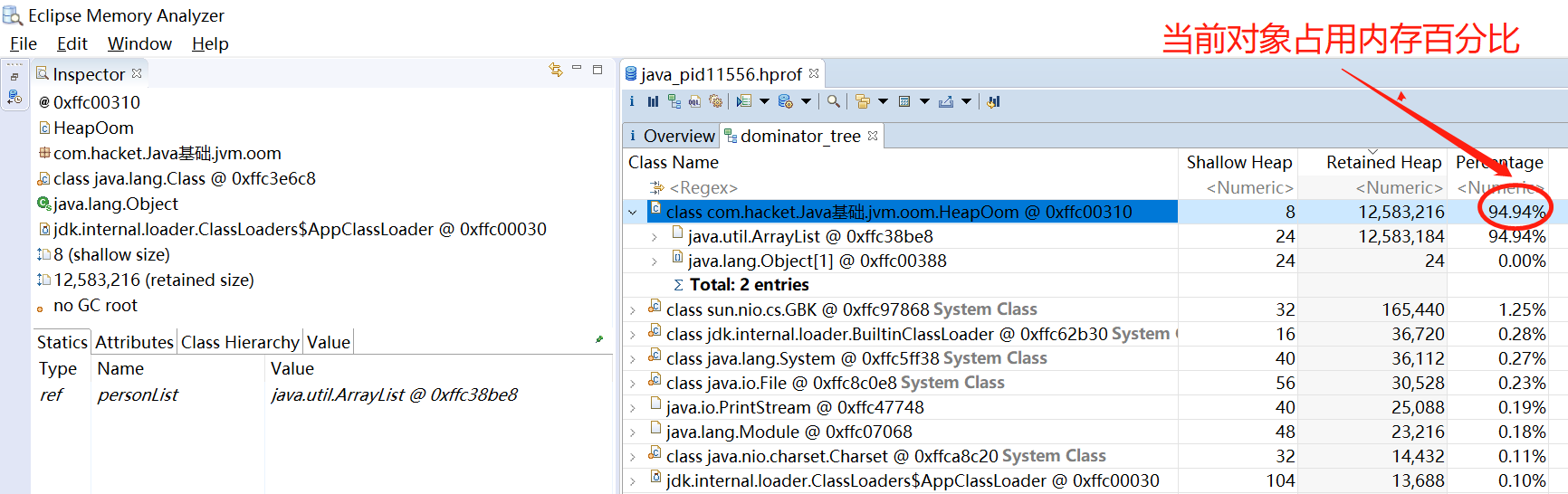
现在需要查看该对象都引用了哪些数据,已经当前对象被哪几个对象所引用了:鼠标在当前所要查看的对象右键,点击 List Objects 可以看到分别提供了:
- with outgoing references 列出该类引用了哪些类
- **with incoming references **列出哪些类引入该类
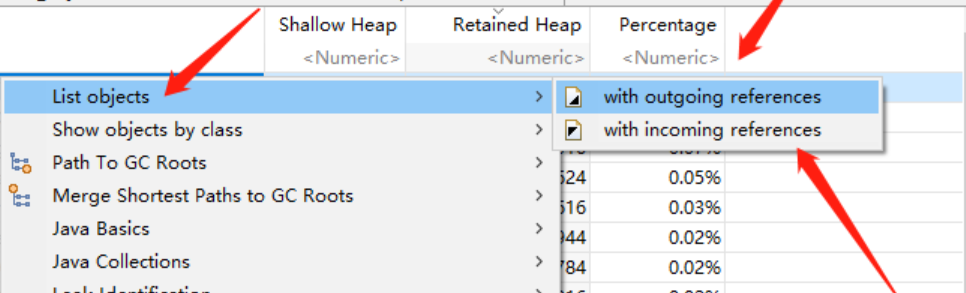
快速找出某个实例没被释放的原因,可以右健 Path to GC Roots-->exclude all phantom/weak/soft etc. references
它展示了对象间的引用关系
- Top Consumers 按照类和包分组的方式展示出占用内存最大的一个对象
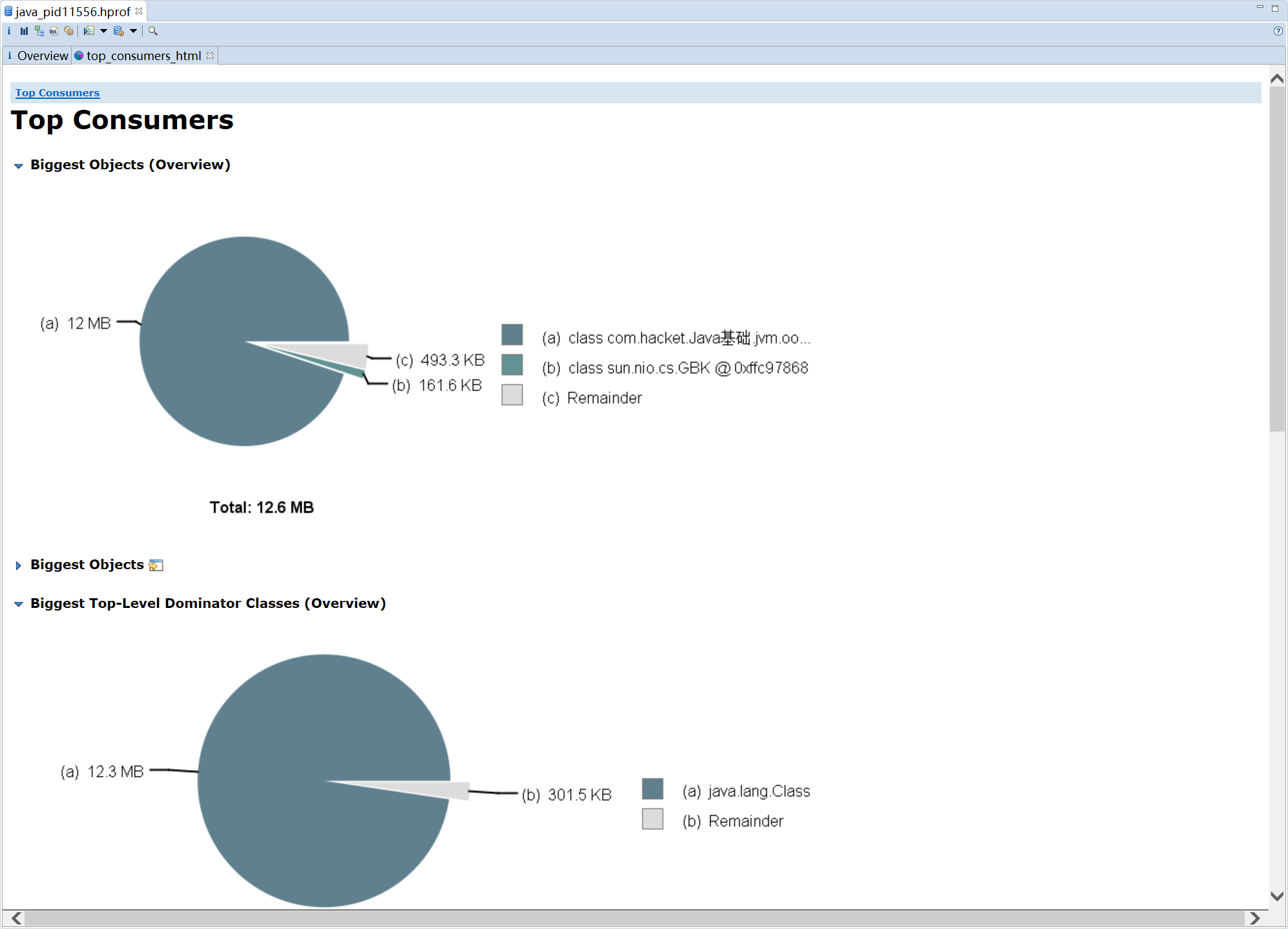
- Duplicate Classes 检测由多个类加载器所加载的类信息(用来查找重复的类)
Reports
- **Leak Suspects **通过 MAT 自动分析当前内存泄漏的主要原因
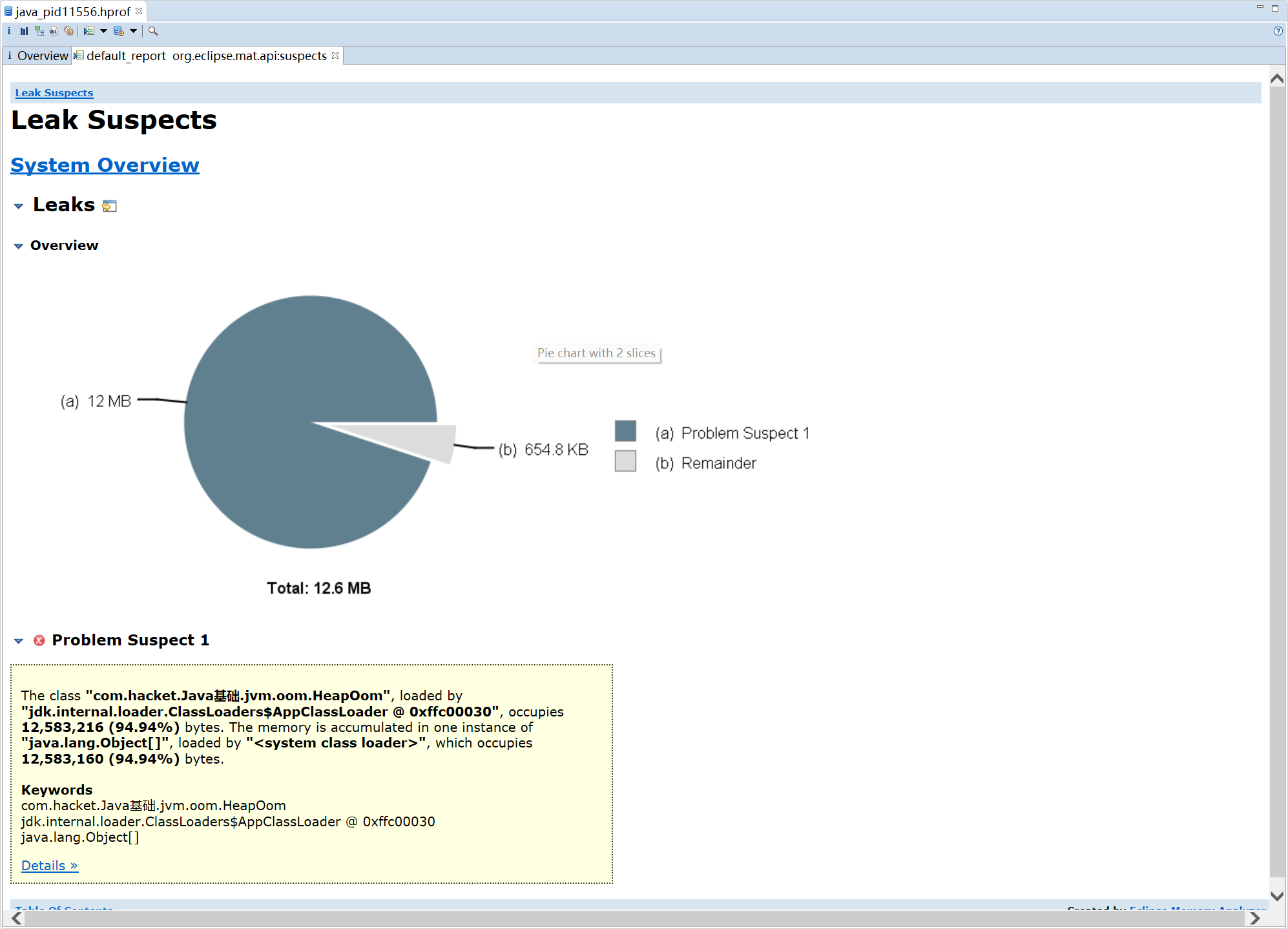
MAT 会给出内存泄漏的主要原因,点进去 Detail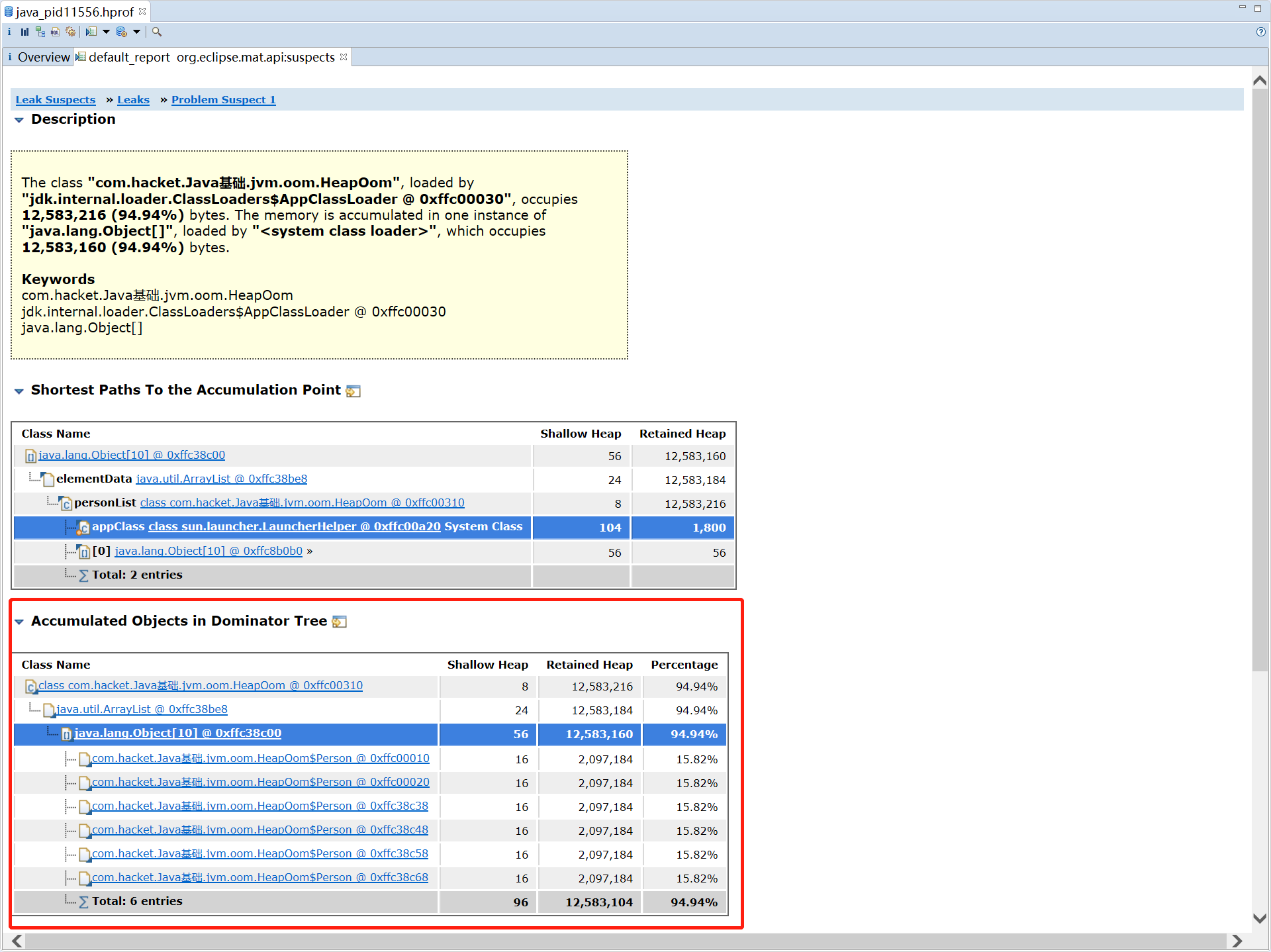
可以看到占用 94% 内存的是一个 ArrayList,其中每个 Person 对象占用了 15% 的内存
- Top Components Top 组件,列出大于总堆 1% 的组件的报告
Step By Step
- Component Report 组件报告,分析属于公共根包或类加载器的对象
其他
Thread_Overview
查看当前进程 dump 时的所有线程的堆栈信息,通过分析下面所对应的堆栈信息,可以很快速的定位到对应的线程所执行的方法等层级关系,以此来定位对应的异常问题;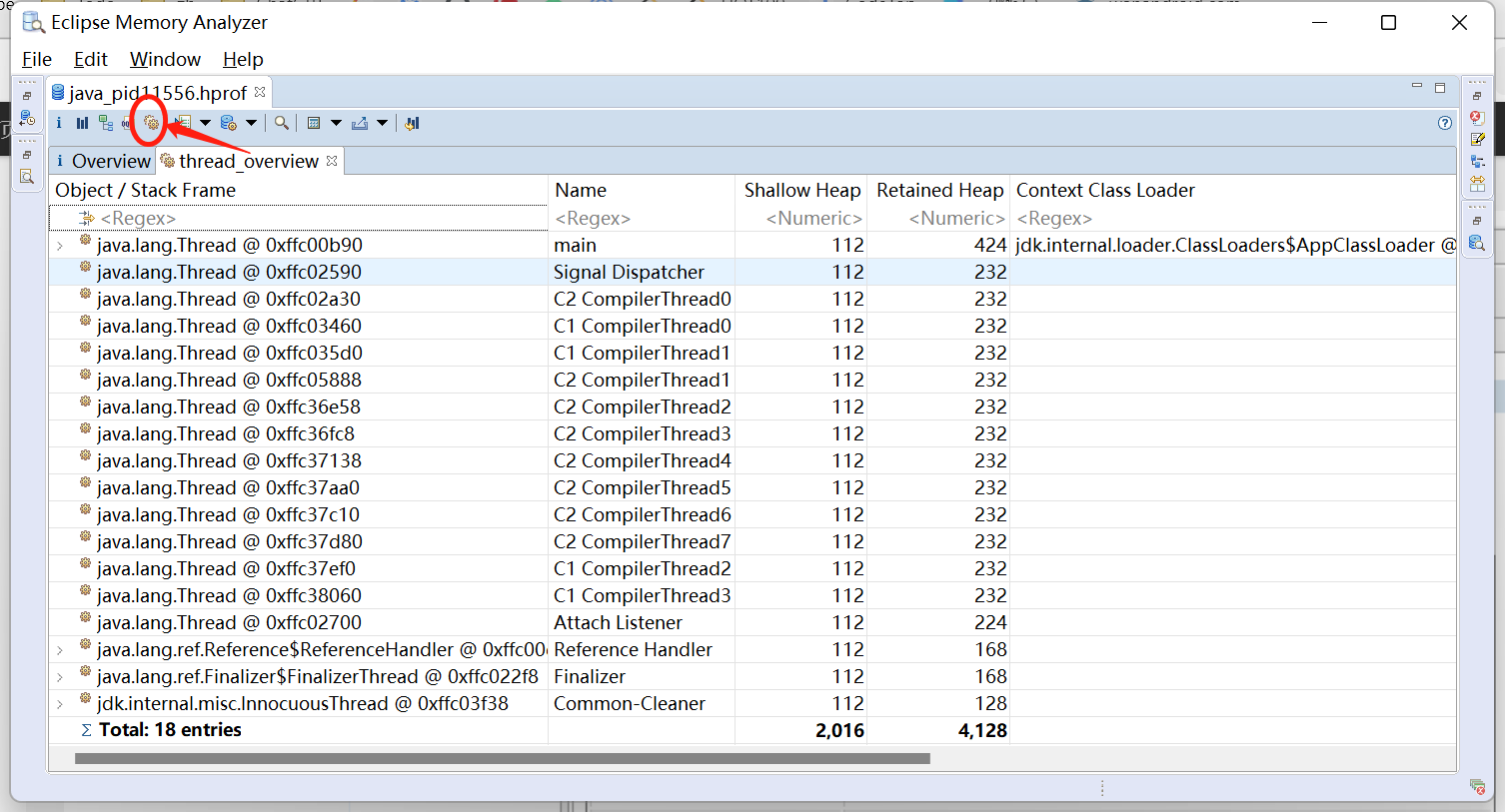
Heap Dump Overview
可以查看全局的内存占用信息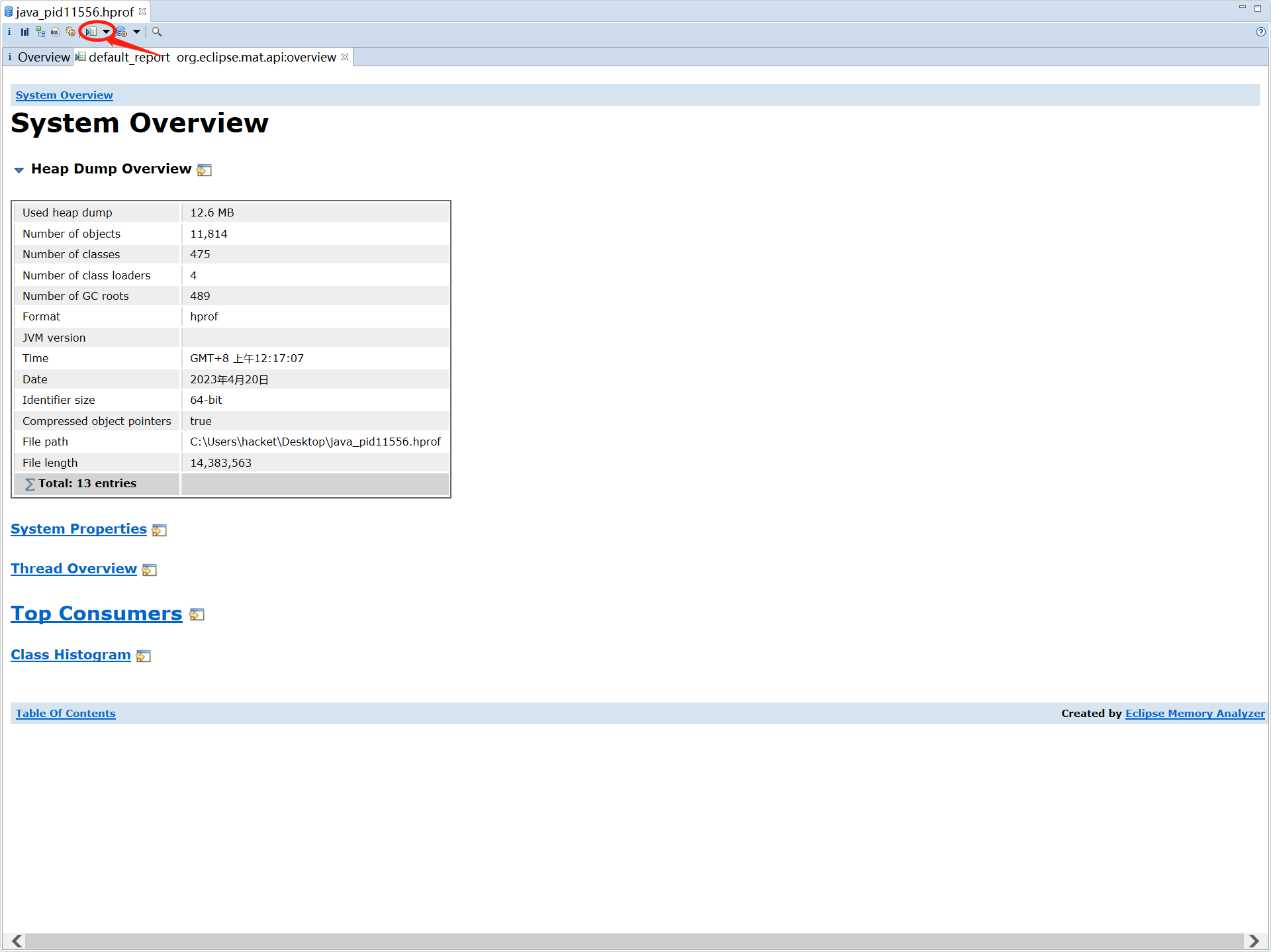
分析 hprof 文件示例
OOM 分析
OOM 示例代码
1
2
3
4
5
6
7
8
9
10
11
public class HeapOom {
static List<String[]> stringList = new ArrayList<>();
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
String[] strings = new String[4 * 1024 * 1024]; //35m的数组(堆)
stringList.add(strings);
}
System.out.println("HeapOom demo " + stringList);
}
}
JVM 参数配置
配置 JVM 运行参数:-Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=C:\Users\hacket\Desktop
- -Xms 和 -Xmx 参数来设置堆的初始大小和最大大小
- -XX:+PrintGCDetails 会在每次 GC 时打印详细信息
- -XX:+HeapDumpOnOutOfMemoryError 表示在发生内存溢出时导出此时堆中相关信息
-XX:HeapDumpPath=<file-path>用于指定导出堆信息时的路径或文件名
MAT 分析 HPROF 文件
- 得到 hprof 文件
- 使用 MAT 内存分析工具去检测占用大内存可疑对象
- 分析对象到 GC Roots 节点的可达性
流程很繁琐,是否有自动化工具,自动帮我们去分析那些常见的内存泄漏场景呢?
内存泄漏分析
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
private void initLeaks(Application application) {
application.registerActivityLifecycleCallbacks(new EmptyActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
ActivityMaker.getList().add(activity);
}
);
}
object ActivityMaker {
@JvmStatic
val list = mutableListOf<Activity>()
}
分析步骤:
- 通过 Leak Suspects 界面提示查找可能存在内存的泄露
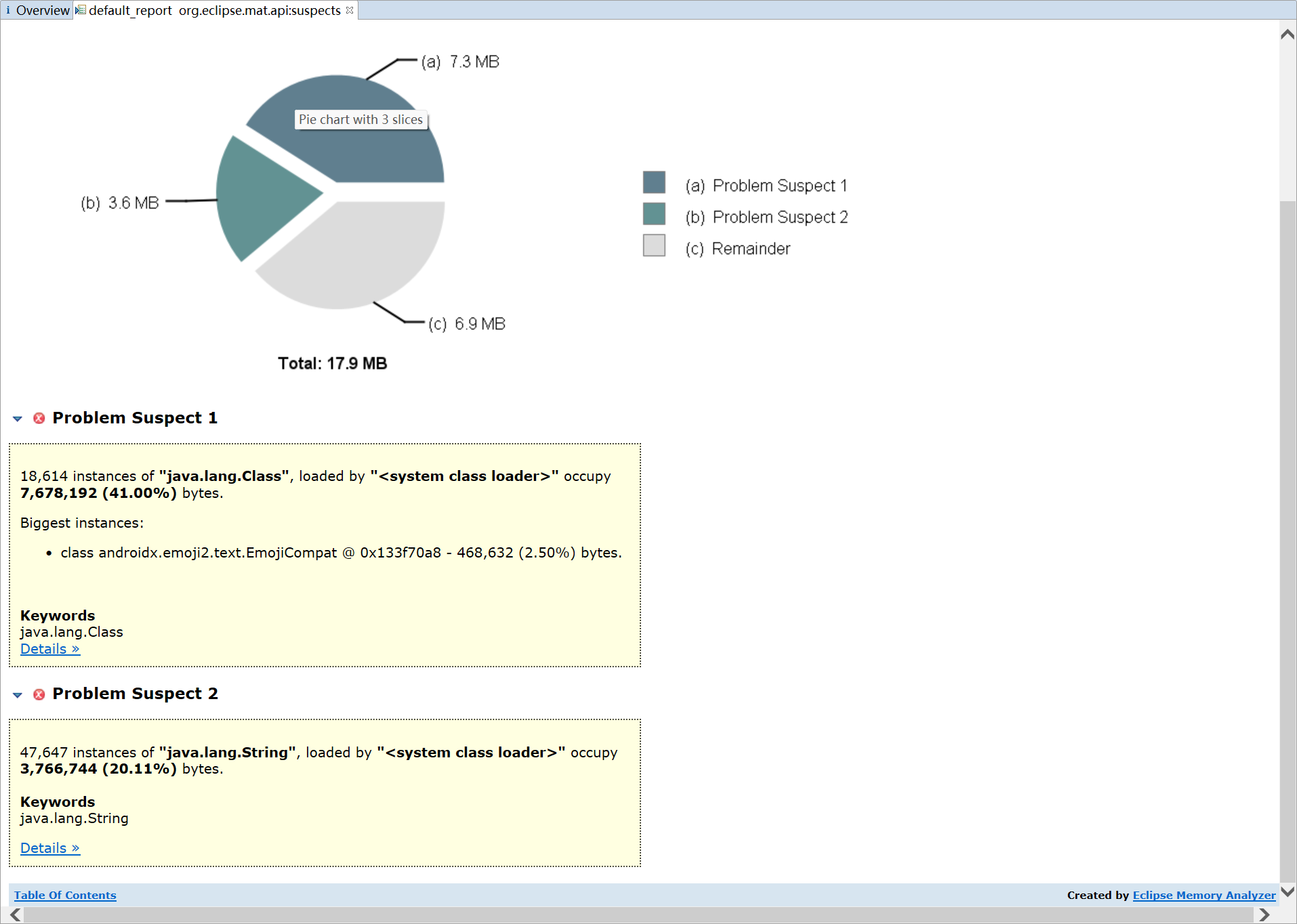
上图可以看到发现了 2 处可疑内存泄漏,点进去 Details,可能并没有
我们还可以通过 dominator tree 视图,搜索 Activity,右键选择某个 Activity,选择 Path To GC Roots 或 Shortest Paths To the Accumulation Point(表示 GC root 到内存消耗聚集点的最短路径,如果某个内存消耗聚集点有路径到达 GC root,则该内存消耗聚集点不会被当做垃圾被回收)
一般选择
Path To GC Roots或Shortest Paths To the Accumulation Point后,exclude 虚/弱/软引用,它们会被 GC 回收,不需要分析

内存快照对比
为了更有效率的找出内存泄露的对象,一般会获取两个堆转储文件(先 dump 一个,隔段时间再 dump 一个),通过对比后的结果可以很方便定位
基于 Haha
在 LeakCanary 的第一版的时候,是采用的 Haha 库来分析泄漏引用链,但由于后面新出的 Shark,比 HaHa 快 8 倍,并且内存占用还要少 10 倍,但查找泄漏路径的大致步骤与 Shark 无异
Matrix
LeakCanary 1.x
基于 Shark
Liko
Koom
LeakCanary 2.x
MMAT
https://github.com/hehonghui/mmat
在 App 运行结束之后进行全面、自动地离线分析 app 内存泄漏, 一次性分析出本次 App 运行产生的所有 Activity、Fragment 的内存泄漏, 那么将会让内存泄漏分析更加全面、高效.
hprof 文件的裁剪、压缩
Why?为什么要裁剪 hprof 文件?
- 存储不方便
hprof 是堆内存快照文件,通常文件都很大,可能超过 100M,会占用很大的应用空间,如果空间不够,会导致 dump 失败
- 分析时容易 OOM
如果 hprof 文件过大,在设备上进行分析操作时,可能导致 OOM
- 传输
要分析线上用户的 hprof 文件,需要网络传输,太大不方便传输且耗费网络,回传成功率会比较低
- 隐私
hprof 记录完整的内存数据,可能会记录一些用户的隐私数据在其中
How?裁剪的方式
先 dump hprof 文件后裁剪
过程
- 通过
Debug.dumpHprofData()得到一个完整的 hprof 文件 - 再分析 hprof 文件,进行裁剪,去掉一些无用的数据
- 裁剪完成后,得到一份精简的 hprof 文件
缺点:
- 直接 dump 出的 hprof 文件过大,存储问题不好解决
- 裁剪过程涉及到文件 IO 和 hprof 文件解析,可能影响 App 性能
- 裁剪过程不彻底,导致隐私数据的泄漏
在 dump 过程中实时裁剪(推荐)
过程:
- 通过 xHook 对 open()/write() 进行 hook 处理,替换成自身实现;
- 调用
Debug.dumpHprofData()时,优先执行自身实现的 open,为了过滤出写入目标文件的 fd;然后再调用到自身实现的 write,对目标文件写入的数据进行裁剪压缩 - 生成 hprof 文件完毕后,清除之前的 hook 内容,避免影响后续的流程
需要裁剪的内容
需要裁剪掉全部基本类型数组的值,如 char[](字符串)、byte[](图片),在处理内存泄漏相关问题时,一般也只关心对象间的引用以及对象大小,裁剪掉一些消息不会影响分析
保证基本 hprof 文件功能:
- 只对
HEAP_DUMP_SEGMENT的Record下进行裁剪,其他保持不变,如STRING、LOAD_CLASS等 - 在
HEAP_DUMP_SEGMENT的Record下,主要删除 Tag 为PRIMITIVE_ARRAY_DUMP,这一块主要占用 80% 的内容 - 在裁剪
INSTANCE_DUMP(实例)、OBJECT_ARRAY_DUMP(对象数组),CLASS_DUMP(类或接口)和HEAP_DUMP_INFO(记录当前堆位置)时需要再去掉Zygote Heap(系统堆)和Image Heap(图像堆)
主要通过判断 HEAP_DUMP_INFO 的 heapType 是否为 HEAP_ZYGOTE(Z) 和 HEAP_IMAGE(I)
开源库裁剪
Probe(美团)
Tailor(西瓜视频)
KOOM(快手)
dump hprof 注意
如何解决 Dump hprof 时暂停所有线程问题?
问题:
在主进程进行 Dump hprof 操作,会在主进程上所有线程都会停止,会导致应用停顿几秒,也就无法进行任何操作;还可能触发 ANR;这也是 LeakCanary 只能用于线下检测。
KOOM 和 Liko 采用 Linux 的 copy-on-write 机制,从当前的主进程 fork 出一个子进程,然后在子进程进行 dump 分析
坑:在 fork 子进程的时候 dump hprof,由于 dump 前会先 suspend 所有的 Java 进程,等所有线程都挂起来了,才会进行真正的 dump。由于 COW 机制,子进程也会将父进程中的 threadlist 也拷贝过来,但由于 threadlist 中 java 线程活动在父进程,子进程是无法挂起父进程中的的线程的,会一直处于等待中。
解决方案 1:子进程
启动一个子进程,并且需要从主进程 fork 出一个子进程,需要遵循 COW 机制 (为了节省 fork 子进程的内存消耗和耗时,fork 出的子进程并不会 copy 父进程的内存空间,而是共享)。
后续 fork 出的子进程在父进程修改时不受影响。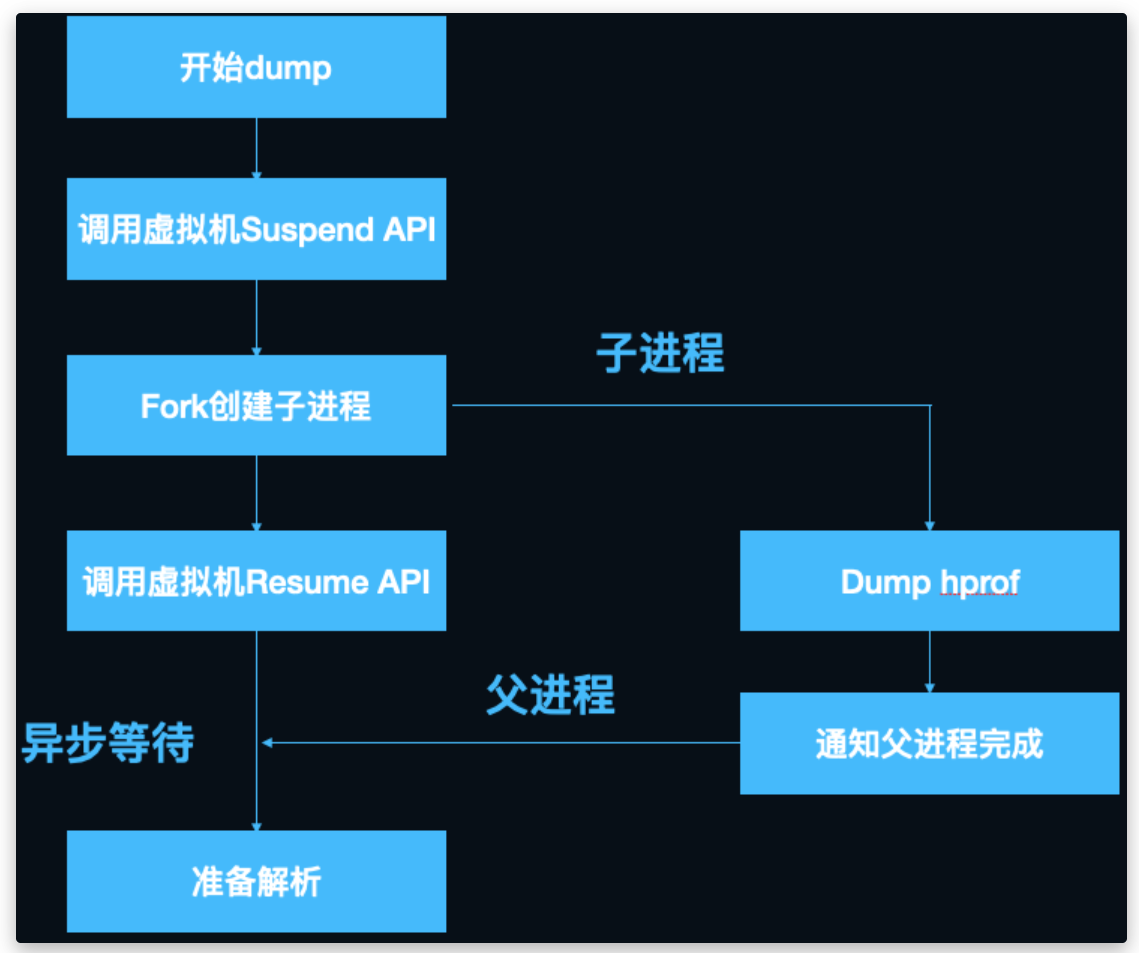
解决方案 2:头条 FileObserver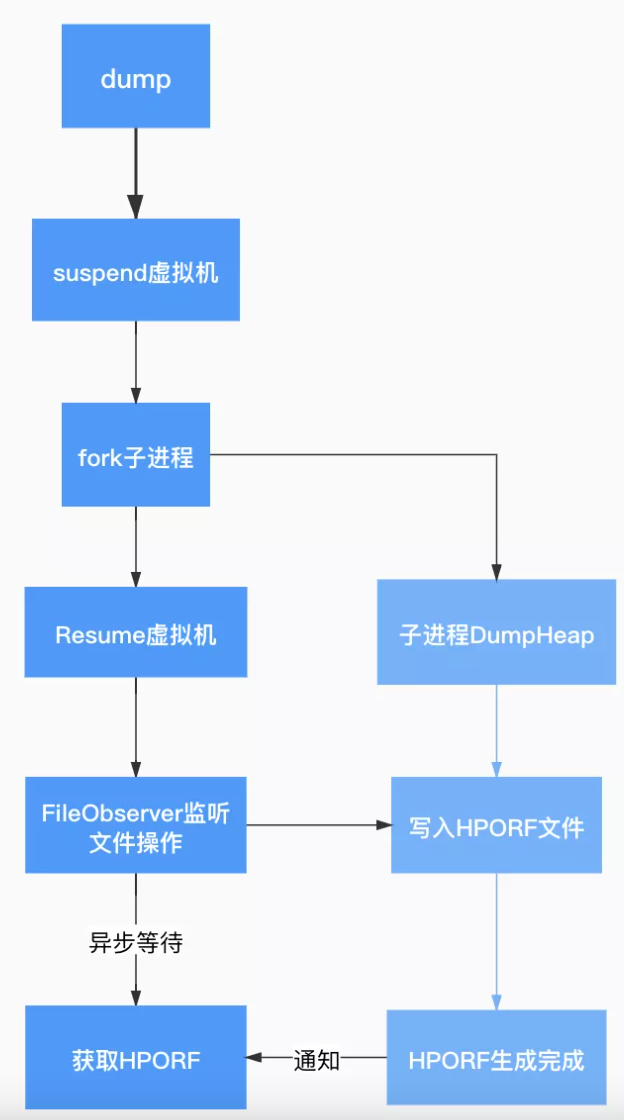
混淆问题
Shark支持混淆反解析,解析 mapping.txt 文件,每次读取一行,只解析类和字段;将混淆类名、字段名作为 key,原类名、原字段名作为 value 存入 map 集合,在分析出内存泄漏的引用路径类时,将类名和字段名都通过这个 map 集合去拿到原始类名和字段名即可,即完成混淆后的反解析。
LeakCanary 内部是写死的 mapping 文件为 leakCanaryObfuscationMapping.txt,如果打开该文件失败,则不做引用链反解析:也即意味着,如果想 LeakCanary 支持混淆反解析,只需要将自己的 mapping 文件重命名为 leakCanaryObfuscationMapping.txt,然后放入 asset 目录即可
Koom 的混淆反解析,Koom 并没有做