C++ 智能指针
C++ 的智能指针
- 智能指针本质上是原始指针的包装,当你创建一个智能指针,它会调用 new 并为你分配内存,然后基于你使用的智能指针,这些内存会在某一时刻自动释放。
- 优先使用
unique_ptr,其次考虑shared_ptr。
尽量使用
unique_ptr因为它有一个较低的开销,但如果你需要在对象之间共享,不能使用unique_ptr的时候,就使用shared_ptr
unique_ptr 独占指针
std::unique_ptr 是 C++ 标准库中的智能指针类,用于管理动态分配的对象。它提供了独占式拥有权,即在任何时候只能有一个 std::unique_ptr 拥有对对象的唯一所有权。当 std::unique_ptr 被销毁或重置时,它会自动删除所管理的对象,从而避免内存泄漏。
std::unique_ptr 的主要特点和用法如下:
- 独占式所有权:一个
std::unique_ptr实例拥有对对象的唯一所有权,不能拷贝或共享所有权。这意味着只能有一个std::unique_ptr实例指向同一个对象,从而避免了资源的多重释放和访问冲突。 - 托管动态分配的对象:
std::unique_ptr主要用于托管通过new或std::make_unique动态分配的对象。它可以管理任何可删除的对象,包括基本类型、自定义类型和数组等。 - 自动释放资源:当
std::unique_ptr被销毁或重置时,它会自动调用所管理对象的析构函数,并释放对象所占用的内存。这消除了手动管理资源释放的需求,提高了代码的可靠性和安全性。 - 移动语义:
std::unique_ptr支持移动语义,可以通过移动构造函数和移动赋值运算符将所有权从一个std::unique_ptr实例转移给另一个实例,从而避免不必要的对象拷贝和资源释放。 unique_ptr构造函数实际上是explicit 的,没有构造函数的隐式转换,需要显式调用构造函数- 最好使用
std::unique_ptr<Entity> entity = std::make_unique<Entity>();因为如果构造函数碰巧抛出异常,不会得到一个没有引用的悬空指针从而造成内存泄露,它会稍微安全一些。 std::make_unique<>()是在C++14引入的,C++11不支持。
示例 1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <iostream>
#include <memory>
class Entity
{
public:
Entity()
{
std::cout << "Create!" << std::endl;
}
~Entity()
{
std::cout << "Destroy!" << std::endl;
}
void Print(){}
};
int main()
{
{
//使用unique_ptr的一种方式
std::unique_ptr<Entity> entity = new Entity(); // error! unique_ptr不能隐式转换
std::unique_ptr<Entity> entity(new Entity());//ok,可以但不建议
std::unique_ptr<Entity> entity = std::make_unique<Entity>(); //推荐使用std::make_unique。因为如果构造函数碰巧抛出异常,它会稍微安全一些。std::make_unique<>()是在C++14引入的,C++11不支持。
entity->Print(); //像一般原始指针使用
}
std::cin.get();
}
示例 2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
#include <memory>
class UniquePtr {
public:
UniquePtr() { std::cout << "调用构造函数" << std::endl; }
~UniquePtr() { std::cout << "调用析构函数" << std::endl; }
void print() { std::cout << "调用print()函数" << std::endl; }
};
int main() {
std::unique_ptr<UniquePtr> ptr(new UniquePtr());
ptr->print();
return 0;
}
// 调用构造函数
// 调用print()函数
// 调用析构函数
- 无法进行复制构造和赋值操作
1
2
3
4
5
6
int main() {
std::unique_ptr<UniquePtr> ptr(new UniquePtr());
std::unique_ptr<UniquePtr> ptr1(ptr); //报错
std::unique_ptr<UniquePtr> ptr2 = ptr; //报错
return 0;
}
- 可以进行移动构造和移动赋值操作
unique_ptr 虽然没有拷贝和赋值操作,但却提供了一种移动机制来将指针的所有权从一个 unique_ptr 转移给另一个 unique_ptr。如果需要转移所有权,可以使用 std::move() 函数。
1
2
3
4
5
6
int main() {
std::unique_ptr<UniquePtr> ptr(new UniquePtr());
std::unique_ptr<UniquePtr> ptr2 = std::move(ptr); //转移所有权
std::unique_ptr<UniquePtr> ptr3(std::move(ptr));
return 0;
}
- 可以通过函数返回值返回 unique_ptr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
#include <memory>
class UniquePtr {
public:
UniquePtr() { std::cout << "调用构造函数" << std::endl; }
~UniquePtr() { std::cout << "调用析构函数" << std::endl; }
void print() { std::cout << "调用print()函数" << std::endl; }
};
std::unique_ptr<UniquePtr> return_unique_ptr() {
std::unique_ptr<UniquePtr> ptr(new UniquePtr());
return ptr;
}
int main() {
std::unique_ptr<UniquePtr> ptr = return_unique_ptr();
return 0;
}
shared_ptr 共享指针
shared_ptr的工作方式是通过引用计数
引用计数基本上是一种方法,可以跟踪你的指针有多少个引用,一旦引用计数达到零,他就被删除了。 例如:我创建了一个共享指针 shared_ptr,我又创建了另一个 shared_ptr 来复制它,我的引用计数是 2,第一个和第二个,共 2 个。当第一个死的时候,我的引用计数器现在减少 1,然后当最后一个 shared_ptr 死了,我的引用计数回到零,内存就被释放。
shared_ptr需要分配另一块内存,叫做控制块,用来存储引用计数,如果您首先创建一个new Entity,然后将其传递给shared_ptr构造函数,它必须分配,做 2 次内存分配。先做一次 new Entity 的分配,然后是 shared_ptr 的控制内存块的分配。然而如果你用make_shared()你能把它们组合起来,这样更有效率。
1
2
std::shared_ptr<Entity> sharedEntity = sharedEntity(new Entity());//不推荐!
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();//ok
- 使用格式:
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Entity2
{
public:
Entity2() {
std::cout << "Created Entity2!" << std::endl;
}
~Entity2() {
std::cout << "Destroyed Entity2!" << std::endl;
}
void Print() {
std::cout << "Test!" << std::endl;
}
};
void SmartPointerDemo::testSharedPointer()
{
{
std::shared_ptr<Entity2> e0;
{
// std::shared_ptr<Entity2> sharedEntity = sharedEntity(new Entity());//不推荐!
std::shared_ptr<Entity2> sharedEntity = std::make_shared<Entity2>();//ok
e0 = sharedEntity; //可以复制
} //此时sharedEntity已经“死了”,但没有调用析构,因为e0仍然是活的,并且持有对该Entity的引用,此时计数由2-》1
} //析构被调用,因为所有的引用都消失了,计数由2-》0,内存被释放
}
代码运行到 60、61 行,此时还有 e0 指向 Entity2 了,析构函数没有调用
| 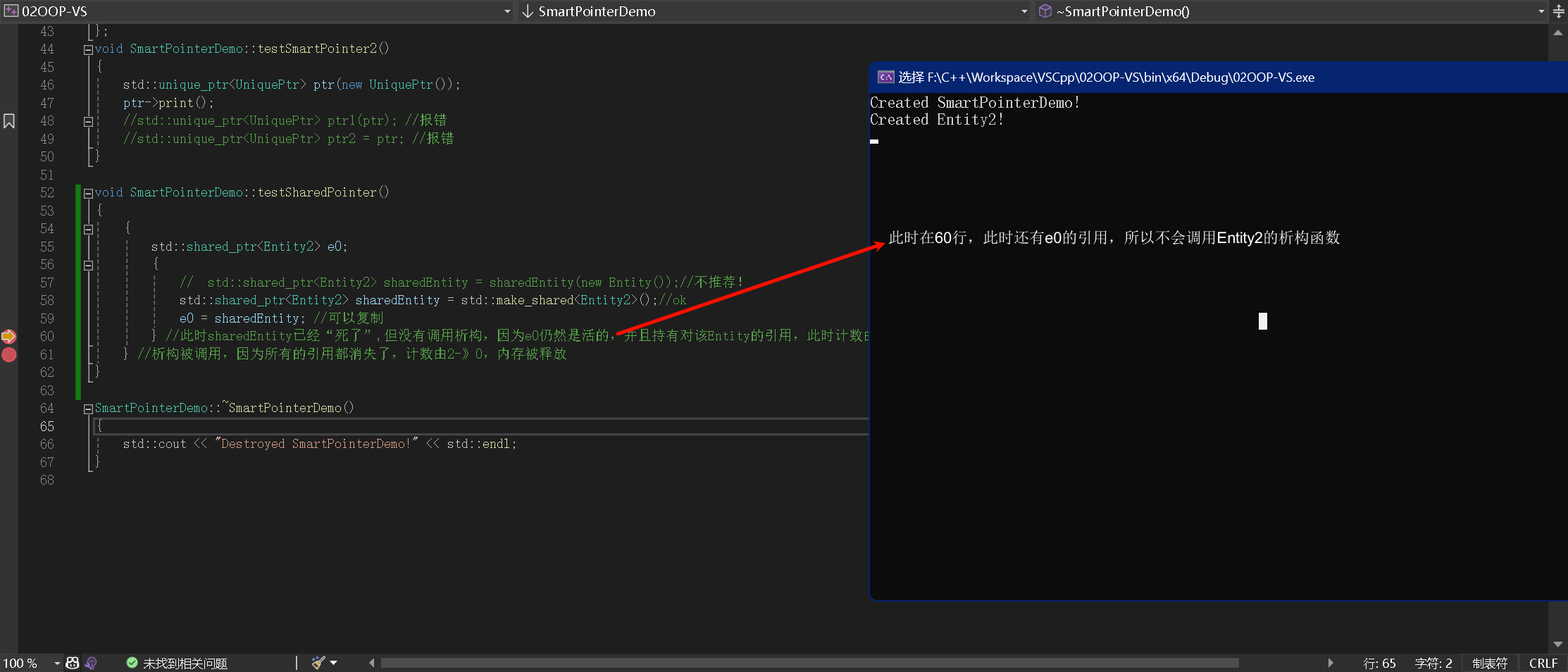 |
当运行到 62 行,此时已经没有指向 Entity2 的指针了,Entity2 的析构函数调用了
| 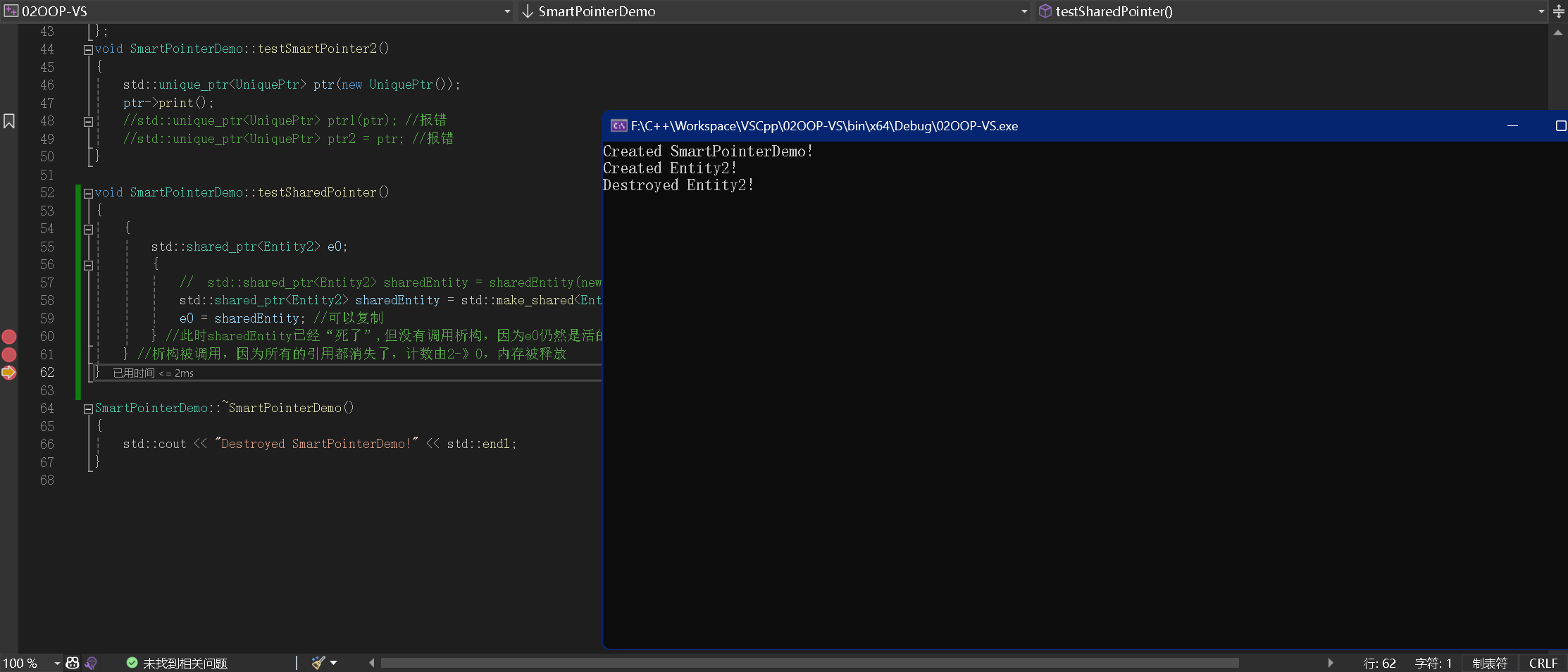 |
std::make_shared() 和 std::shared_ptr()
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
using namespace std::chrono;
class Timer
{
typedef std::chrono::high_resolution_clock Clock;
public:
Timer()
{
m_StartTimePoint = Clock::now();
}
~Timer()
{
Stop();
}
void Stop()
{
auto endTimePoint = Clock::now();
auto start = std::chrono::time_point_cast<std::chrono::microseconds>(m_StartTimePoint).time_since_epoch().count();
//microseconds 将数据转换为微秒
//time_since_epoch() 测量自时间起始点到现在的时长
auto end = std::chrono::time_point_cast<std::chrono::microseconds>(endTimePoint).time_since_epoch().count();
auto duration = end - start;
double ms = duration * 0.001; ////转换为毫秒数
std::cout << duration << "us(" << ms << "ms)\n";
}
private:
time_point<Clock> m_StartTimePoint;
};
void BenchmarkTest::testBenchmark()
{
struct Vector2 {
float x, y;
};
{
Timer* timer = new Timer();
std::array<std::shared_ptr<Vector2>, 1000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::make_shared<Vector2>();
}
delete timer;
}
{
Timer timer;
std::array<std::shared_ptr<Vector2>, 1000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::shared_ptr<Vector2>(new Vector2());
}
}
}
std::make_shared是一个模板函数,用来构造一个对象,并返回这个对象的std::shared_ptr。它是一种更安全、更高效的方式来创建std::shared_ptr,因为它会同时分配引用计数和对象本身在同一块内存中。这意味着只进行一次内存分配,并减少了内存碎片和申请内存的开销。- 而
std::shared_ptr<Vector2>(new Vector2())在这种情况下,对象和它的引用计数是分开分配的两块内存。首先使用 new 关键字创建了一个Vector2的实例,然后将这个指针传递给std::shared_ptr的构造函数。这导致了两次内存分配:一次用于对象,一次用于引用计数。 - 就性能而言,
std::make_shared通常更优,因为它只进行一次内存分配,这会更快,并且还可以减少程序的内存使用。此外,它还能避免悬挂指针的潜在问题,因为它确保创建了一个有效的共享指针。然而,std::make_shared会延长对象存活期直到最后一个 weak_ptr 销毁,因为对象和它的引用计数存在同一块内存中。
总结:在大多数情况下,使用 std::make_shared 会比直接使用 std::shared_ptr 的构造函数拥有更好的性能和安全性。但如果您需要控制过对象的精确销毁时间,可能需要权衡和选择后者。
weak_ptr 弱指针
- 可以和共享指针
shared_ptr一起使用。 weak_ptr可以被复制,但是同时不会增加额外的控制块来控制计数,仅仅声明这个指针还活着。类似 Java 中的WeakReference
当你将一个 shared_ptr 赋值给另外一个 shared_ptr,引用计数 ++,而若是把一个 shared_ptr 赋值给一个 weak_ptr 时,它不会增加引用计数。这很好,如果你不想要 Entity 的所有权,就像你可能在排序一个 Entity 列表,你不关心它们是否有效,你只需要存储它们的一个引用就可以了。
1
2
3
4
5
6
7
{
std::weak_ptr<Entity> e0;
{
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();
e0 = sharedEntity;
} //此时,此析构被调用,内存被释放
}
代码执行 72 行,由于是 e0 是弱指针,不会增加引用计数,所以 sharedEntity 过了作用域就释放了
| 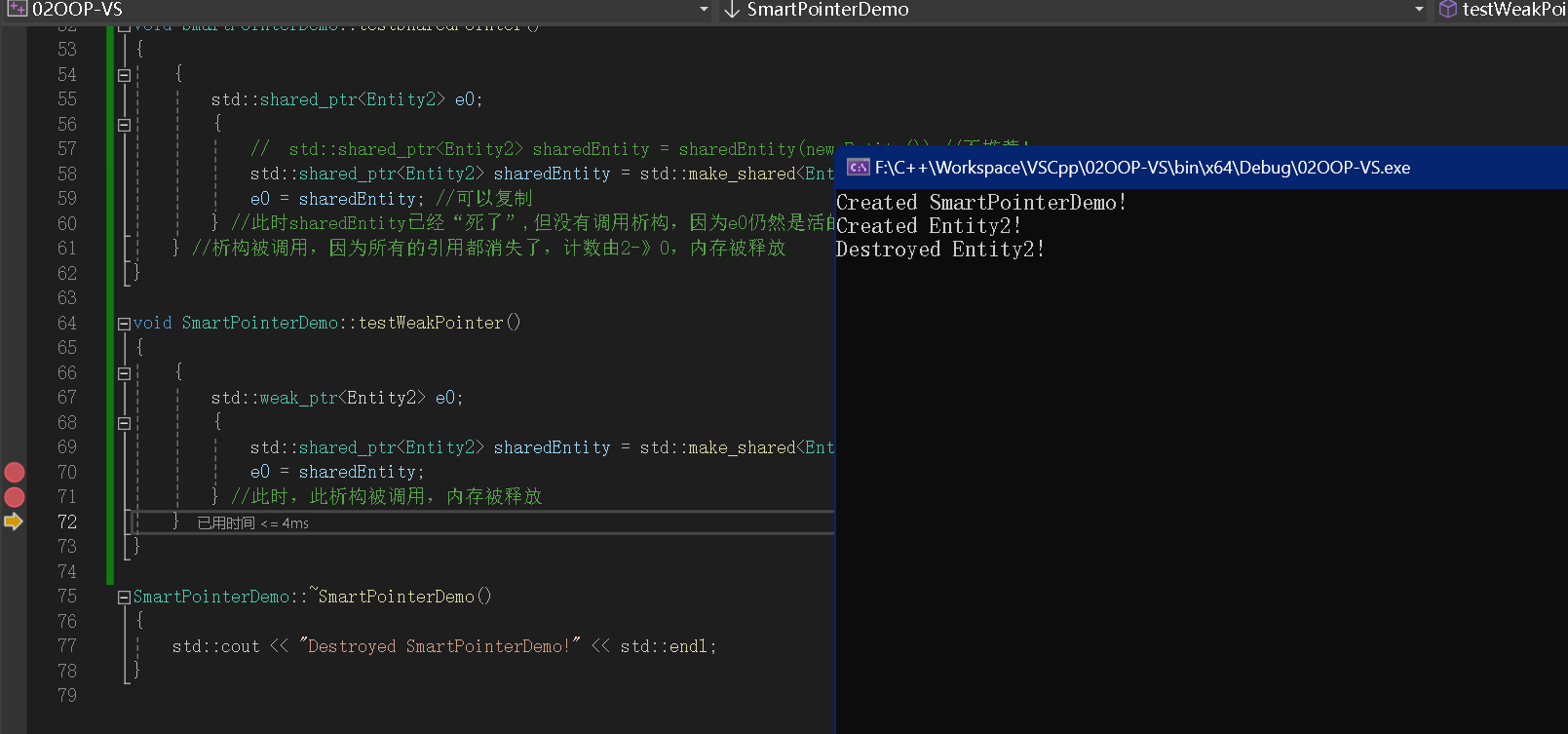 |
unique_ptr 和 shared_ptr 基准测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
#include "stdafx.h"
#include "BenchmarkTest.h"
#include <chrono>
using namespace std::chrono;
// Timer出了作用域就会统计耗时
class Timer
{
typedef std::chrono::high_resolution_clock Clock;
public:
Timer()
{
m_StartTimePoint = Clock::now();
}
~Timer()
{
Stop();
}
void Stop()
{
auto endTimePoint = Clock::now();
auto start = std::chrono::time_point_cast<std::chrono::microseconds>(m_StartTimePoint).time_since_epoch().count();
//microseconds 将数据转换为微秒
//time_since_epoch() 测量自时间起始点到现在的时长
auto end = std::chrono::time_point_cast<std::chrono::microseconds>(endTimePoint).time_since_epoch().count();
auto duration = end - start;
double ms = duration * 0.001; ////转换为毫秒数
std::cout << duration << "us(" << ms << "ms)\n";
}
private:
time_point<Clock> m_StartTimePoint;
};
void BenchmarkTest::testBenchmark()
{
struct Vector2 {
float x, y;
};
{
// 指针
Timer* timer = new Timer();
std::array<std::shared_ptr<Vector2>, 10000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::make_shared<Vector2>();
}
delete timer;
}
{
Timer timer;
std::array<std::shared_ptr<Vector2>, 10000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::shared_ptr<Vector2>(new Vector2());
}
}
{
Timer timer;
std::array<std::unique_ptr<Vector2>, 10000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::make_unique<Vector2>();
}
}
}
|  |
1
2
3
4
5
6
7
8
9
10
11
{
// 指针
Timer timer;
// Timer* timer = new Timer();
std::array<std::shared_ptr<Vector2>, 10000> sharedPtrs;
for (size_t i = 0; i < sharedPtrs.size(); i++)
{
sharedPtrs[i] = std::make_shared<Vector2>();
}
// delete timer;
}
| 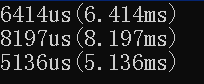 |
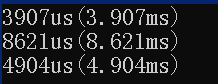
通过值声明的(堆栈上),另一个是通过 new(堆上)动态分配的。首先要指出的是,使用 new 关键字会在堆上动态分配内存,而直接声明则在栈上创建对象。动态分配通常比栈分配要慢,因为它涉及到更复杂的内存管理过程。然而,你提到的情况似乎与这个常规的期望相悖。
如果你发现通过值声明的 Timer 执行慢很多,这很可能是由以下原因造成的:
- 堆栈清理:当通过值声明的 Timer 离开作用域时,可能需要更多的堆栈清理工作。例如,如果有大量的对象在栈上创建并且销毁,那些析构函数的调用可能会显著增加执行时间。
- 异常处理逻辑:如果构造函数内部或者其调用有可能引发异常,堆栈展开和异常处理可能导致额外的延迟。
- 局部优化:编译器可能优化动态分配的 Timer 示例,因为 new 和 delete 可能被推迟或者重排以优化性能。
- 测量错误:数值测量可能会因缓存效应、启动开销或其他外部因素而导致不一致结果。
指针其他
pointer-like classes(仿指针)
在 C++ 中,智能指针(smart pointers)是包装原始指针(raw pointer)的类,它们通过重载 operator* 和 operator-> 来提供类似指针的行为。智能指针的目的是为了自动化内存管理,减少内存泄漏,确保动态分配的对象能够被适时删除。
迭代器是另一种 pointer-like classes 的指针,它与智能指针有些不一样。它有如下特点:
- 迭代器中一定有一个一般的指针。
- 他除了有
*、—>这两个操作符的重载,还有++、--等等其他操作符的重载。且*、—>重载的实现手法与智能指针不一样。