APT
注解处理器
什么是注解处理器(annotation processor)
annotation processors 是一种强大的机制,可以通过注解的方式生成代码。典型的使用场景包括依赖注入 (比如 Dagger),或者是减少样板代码 (比如 Butterknife)。但是使用 annotation processor 对构建性能有很多负面影响,因为构建的时候会插入自定义的一些操作。
annotation processor 基本上可以理解成一个Java 编译器插件。在 Java 编译器识别到一个可被 processor 处理的注解时就会触发这个 processor。
APT(
Annotation Processing Tool的简称) 注解处理器,不是运行时通过发射机制运行处理的注解,而是编译时处理的注解,可以在代码编译期解析注解,并且生成新的 Java 文件,减少手动的代码输入。Java5 就已经存在,Java6 才有可用 API
AbstractProcessor 注解处理器说明及定义
注解处理器会对其感兴趣的注解进行处理,一个注解处理器只能产生新的源文件,它不能修改一个已经存在的源文件。 继承 AbstractProcessor 就是一个处理器,需要指定处理器能够处理的注解类型以及支持的 Java 版本。注解处理器可以让我们在 Java 编译器编译代码之前,执行一段我们的代码。当然这代码也不一定就是要生成别的代码了,你可以去检查那些被注解标注的代码的命名是否规范。
1、注解处理器方法
public synchronized void init(ProcessingEnvironment processingEnvironment)
初始化方法会被注解处理工具调用,传入ProcessingEnvironment参数,这个参数提供了包含很多有用的工具类,如 Elements,Types,Filter 等。public Set getSupportedAnnotationTypes()
指定注解处理器能够处理的注解类型,这个方法返回一个可以支持的注解类型的字符串集合。public SourceVersion getSupportedSourceVersion()
指定注解处理器使用的 Java 版本,通常返回SourceVersion.latestSupported()即可,也可以指定某个 Java 版本,如SourceVersion.RELEASE_7。public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment)
在这个方法中实现注解处理器的具体业务,根据输入参数roundEnvironment可以得到包含特定注解的被注解元素,然后可以编写处理注解的代码最终生成所需的 Java 源文件等信息。
2、注解处理器上的注解
从 Java7 开始,可以使用注解来代替上面的 getSupportedAnnotationTypes() 和 getSupportedSourceVersion()
@SupportedAnnotationTypes
注解处理器能够处理的注解类型,值为支持的所有注解的完整类名字符串类型 的集合,支持通配符。
1
@SupportedAnnotationTypes({"me.hacket.BeanAnno"})
@SupportedSourceVersion
该注解处理器支持的 Java 版本;标识该处理器支持的源码版本
1
@SupportedSourceVersion(SourceVersion.RELEASE_7)
Note 注解处理器的类上可以添加注解 (需要 JDK7+),当然类上的这些注解的作用也可以被对应的方法复写。
注册注解处理器
注册注解处理器
新建一个 Java工程 或者 Java module,创建一个根目录 META-INF 里面新建 /services/javax.annotation.processing.Processor 文件,这个文件中去写我们处理器的类完整路径,如果存在多个注解处理器,以换行进行分隔,然后将其打包成 Jar 包:
1
2
me.hacket.JsonAnnotaionProcessor
me.hacket.BeanProcessor
Note注解处理器所在必须是 Java Library,而不是 Android Library 因为在实现编译时的注解可能会用到 javax 里面的类,而这个包不包含在 Android Library 的 JDK 中的。
使用注解处理器
需要在和 src/main/java 同级目录新建一个名为 resources 的目录,将 javax.annotation.processing.Processor 文件放进去。
Note手动执行注册过程是很繁琐的,Goodle 开源了一个名为 AutoService 的库,只需要在自己定义的注解处理器的 Processor 使用 @AutoService 就完成注册了。
注解处理器所在的 jar 包只在编译器起作用,不会打包到最终的 APK 中去。
让注解处理器支持增量编译(Making an annotation processor incremental)
Gradle 支持对两种常见的注解处理器进行增量编译:隔离(Isolating) 和 聚合(Aggregating)。注解处理器的增量也是基于 Java 的增量编译: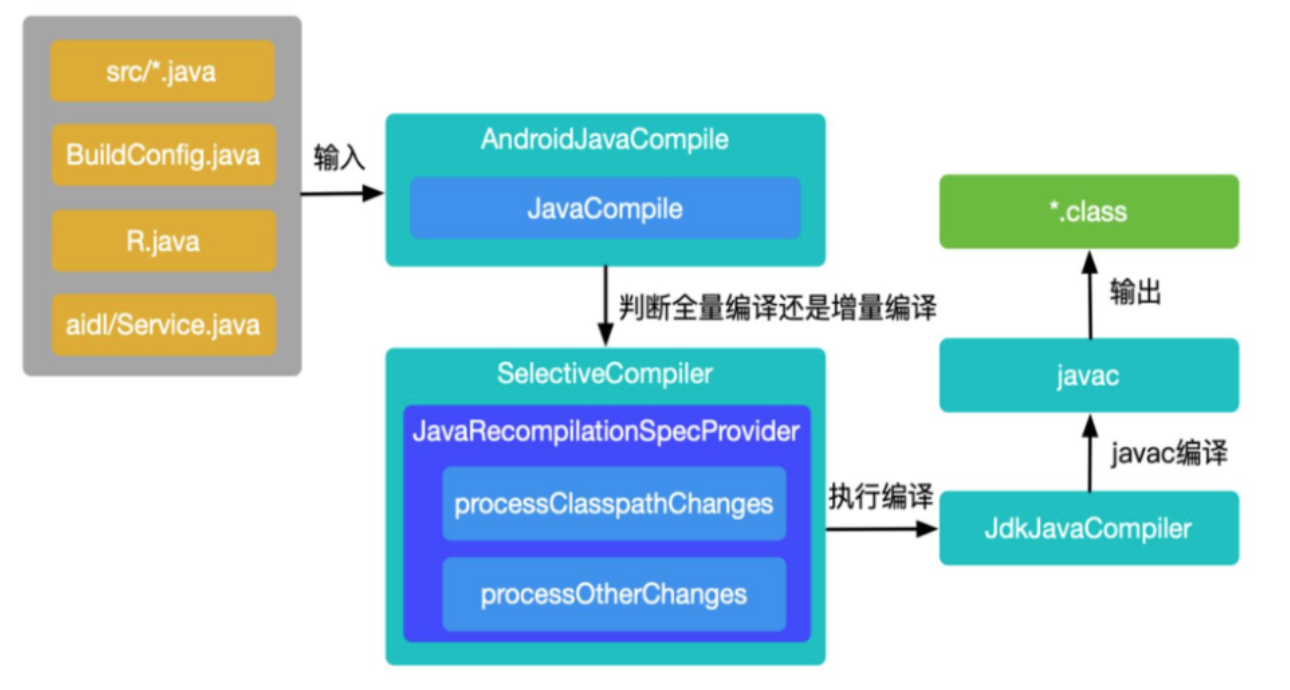
当编译 Java 类文件时,通过 compileJavaWithJavac 这个 task 实现,具体处理类是 AndroidJavaCompile 和 JavaCompile 首先做一些预处理操作,如校验注解类型,判断编译配置是否允许增量编译等。如果判断结果为全量编译,则直接走接下来的编译流程;如果判断结果为增量编译,还会进一步确定修改的影响范围,并把所有受到影响的类都作为编译的输入,再走接下来的编译流程。
注解处理器增量编译未支持警告
在 Gradle 编译时,会输出以下日志提醒你那些注解处理器没有支持增量编译:
1
w: [kapt] Incremental annotation processing requested, but support is disabled because the following processors are not incremental: com.x.XXProcessor (NON_INCREMENTAL).
低版本 ARouter 不支持 kapt 增量编译:
1
w: [kapt] Incremental annotation processing requested, but support is disabled because the following processors are not incremental: com.alibaba.android.arouter.compiler.processor.AutowiredProcessor (NON_INCREMENTAL), com.alibaba.android.arouter.compiler.processor.InterceptorProcessor (NON_INCREMENTAL), com.alibaba.android.arouter.compiler.processor.RouteProcessor (NON_INCREMENTAL).
让 APT 支持增量编译
首先 Gradle 支持两种注解处理器的增量编译:isolating 和 aggregating,你需要搞清你的注解处理器属于哪种。然后在 META-INF/gradle/incremental.annotation.processors 文件中声明支持增量编译的注解处理器。
比如我实现的一个支持增量编译的注解处理器的目录结构:
1
2
3
4
5
6
7
8
9
10
11
x_processor/src/main/
├── java
│ └── me
│ └── hacket
│ └── features_impl_processor
└── resources
└── META-INF
├── gradle
└── incremental.annotation.processors
└── services
└── javax.annotation.processing.Processor
incremental.annotation.processors 和 javax.annotation.processing.Processor 类似,一行一个注解处理器的声明:
1
<注解处理器全限定名>,isolating
同时要在后面声明注解处理器的类型,使用 , 号做分隔。
1
2
3
4
5
processor/src/main/resources/META-INF/gradle/incremental.annotation.processors
EntityProcessor,isolating // 隔离模式
EntityProcessor,aggregating // 聚合模式
ServiceRegistryProcessor,dynamic // 动态选项,这里的模式是需要覆写getSupportedOptions()来设置的。
如果你的注解处理器要在运行时才能决定是否支持增量编译,那么可以声明为 dynamic,然后在注解处理器的 getSupportedOptions 方法中返回包含 org.gradle.annotation.processing.aggregating 的 Set<String>。
1
2
3
4
5
6
7
8
9
10
incremental.annotation.processors:
<注解处理器全限定名>,dynamic
// ServiceRegistryProcessor
override fun getSupportedAnnotationTypes(): MutableSet<String> {
return mutableSetOf(
"<你的目标注解类名>",
"org.gradle.annotation.processing.aggregating"
)
}
两种增量编译如何选择?
两种增量编译注解处理器的共同限制:
- 只能通过
javax.annotation.processing.Filer接口去生成文件。任何其他方式生成的文件因为不能正确的被清理,会造成编译失败 - 要支持增量编译的注解处理器不能依赖编译器特有的类。因为 Gradle 包装了 processing API,任何依赖了特定编译器的类的编译都会失败
- 如果使用了
Filer#createResource, Gradle 将重编译所有源文件。
isolating
最快的注解处理器类别,这类注解处理器独立地搜索每个带注解的元素,并为其生成文件或验证消息。
限制
- 这类 APT 从 AST(Abstract Syntax Tree) 获得信息,为带注解的类做出所有决策(生成代码,编译检查等)。这意味着我们甚至可以递归地分析类的超类,方法返回类型,注解等。但是这类 APT 不能基于 RoundEnvironment 中不存在的元素进行决策。如果你的 APT 需要基于其他不相关元素的组合做出决策,你应该将它声明为 aggregating
重新编译源文件时,Gradle 将重新编译由源文件生成的所有文件。 删除源文件后,从其生成的文件也会被删除。
- ButterKnife:
aggregating
aggregating 类型的 APT, 可以将多个源文件聚合到一个或多个输出文件中。
限制
- 这类 APT 只能读取 CLASS 或 RUNTIME 类型的会保留在字节码中的注解
- 只能读到通过
-parameters传递给编译器的参数的参数名
Gradle 将始终重新处理(但不会重新编译)APT 已处理的所有带注解的源文件。Gradle 将始终重新编译 APT 生成的任何文件。
KAPT 支持增量编译
Kotlin Annotation Processor 也支持了增量编译,在项目的 gradle.propertice 中声明如下配置就能开启:
1
kotlin.incremental=true
Auto-Service 配置
一些 APT 会使用 auto-service 去生成 META-INF,所以 auto-service 在 1.0.0-rc6 也支持了增量编译
三方库对增量
ARouter
ARouter三个注解处理器对增量编译的支持
ARouter 的都是 aggregating 模式
其他
APT 之 AutoService 版
android-apt
android-apt,在 Android Studio 中使用注解处理器的一个辅助插件。
- 只在编译期间引入注解处理器所在的函数库作为依赖,不会打包到最终生成的 apk 中
- 为注解处理器生成的源代码设置好正确的路径,以便 Android studio 能够找到
kapt
ksp
Reference
Annotation-Processing-Tool 详解
http://qiushao.net/2015/07/07/Annotation-Processing-Tool详解/
详细
Android 利用 APT 技术在编译期生成代码
http://brucezz.itscoder.com/articles/2016/08/06/use-apt-in-android/
Annotation 实战【自定义 AbstractProcessor】
http://www.cnblogs.com/avenwu/p/4173899.html