ANR系统原理
ANR 原理
系统 ANR 完整流程可以分为如下三个部分:
- 超时检测
- ANR 信息收集
- ANR 信息输出
超时检测
触发 ANR 的过程可分为三个步骤:埋炸弹,、拆炸弹,、引爆炸弹
ANR(Application Not Responding)的监测原理本质上是消息机制,设定一个 delay 消息,超时未被移除则触发 ANR。具体逻辑处理都在 system server 端,包括发送超时消息,移除超时消息,处理超时消息以及 ANR 弹框展示等;对于 app 而言,触发 ANR 的条件是主线程阻塞。
1、Service Timeout
Service Timeout 是位于 ActivityManager 线程中的 AMS.MainHandler 收到 SERVICE_TIMEOUT_MSG 消息时触发。对于 Service 有两类:
- 对于前台服务,则超时为
SERVICE_TIMEOUT = 20s; - 对于后台服务,则超时为
SERVICE_BACKGROUND_TIMEOUT = 200s
- 埋炸弹 在 system_server 进程
ActiveServices.realStartServiceLocked()调用的过程会埋下一颗炸弹, 超时没有启动完成则会爆炸
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// How long we wait for a service to finish executing.
static final int SERVICE_TIMEOUT = 20 * 1000 * Build.HW_TIMEOUT_MULTIPLIER;
// How long we wait for a service to finish executing.
static final int SERVICE_BACKGROUND_TIMEOUT = SERVICE_TIMEOUT * 10;
private void realStartServiceLocked(ServiceRecord r, ProcessRecord app,
IApplicationThread thread, int pid, UidRecord uidRecord, boolean execInFg,
boolean enqueueOomAdj) throws RemoteException {
bumpServiceExecutingLocked(r, execInFg, "create", null /* oomAdjReason */);
// ...
}
private boolean bumpServiceExecutingLocked(ServiceRecord r, boolean fg, String why,
@Nullable String oomAdjReason) {
scheduleServiceTimeoutLocked(r.app);
// ...
}
void scheduleServiceTimeoutLocked(ProcessRecord proc) {
if (proc.mServices.numberOfExecutingServices() == 0 || proc.getThread() == null) {
return;
}
Message msg = mAm.mHandler.obtainMessage(
ActivityManagerService.SERVICE_TIMEOUT_MSG);
msg.obj = proc;
mAm.mHandler.sendMessageDelayed(msg, proc.mServices.shouldExecServicesFg()
? SERVICE_TIMEOUT : SERVICE_BACKGROUND_TIMEOUT);
}
- 拆炸弹 主线程 handleCreateService() 拆除炸弹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// ActivityThread.java
private void handleCreateService(CreateServiceData data) {
// ...
ActivityManager.getService().serviceDoneExecuting(data.token, SERVICE_DONE_EXECUTING_ANON, 0, 0);
}
// ActivityManagerService.java
public void serviceDoneExecuting(IBinder token, int type, int startId, int res) {
synchronized(this) {
// ...
mServices.serviceDoneExecutingLocked((ServiceRecord) token, type, startId, res, false);
}
}
// ActiveServices.java
private void serviceDoneExecutingLocked(ServiceRecord r, boolean inDestroying, boolean finishing) {
...
if (r.executeNesting <= 0) {
if (r.app != null) {
r.app.execServicesFg = false;
r.app.executingServices.remove(r);
if (r.app.executingServices.size() == 0) {
// 当前服务所在进程中没有正在执行的service
mAm.mHandler.removeMessages(ActivityManagerService.SERVICE_TIMEOUT_MSG, r.app);
...
}
...
}
- 引爆炸弹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// MainHandler.java
final class MainHandler extends Handler {
public void handleMessage(Message msg) {
switch (msg.what) {
case SERVICE_TIMEOUT_MSG: {
mServices.serviceTimeout((ProcessRecord)msg.obj);
} break;
// ...
}
// ...
}
}
// ActiveServices.java
void serviceTimeout(ProcessRecord proc) {
if (anrMessage != null) {
// 当存在timeout的service,则执行appNotResponding
mAm.mAnrHelper.appNotResponding(proc, anrMessage);
}
}
ANR 信息收集
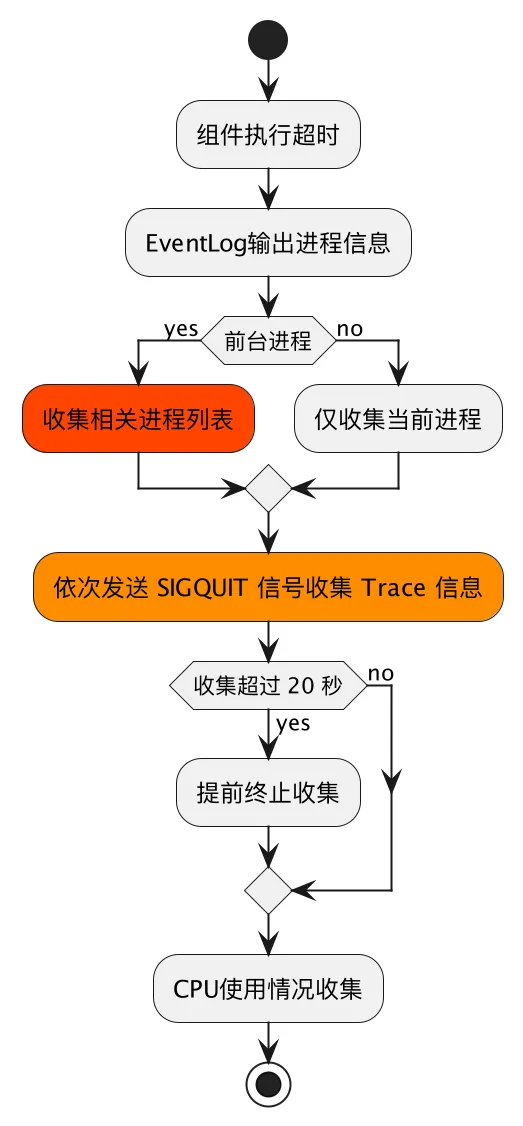
如上图所示,从系统源码中,得到的启示有:
- ANR Trace 的堆栈抓取时机是滞后的,其堆栈不一定是 ANR 根因。
- System Server 会对多个进程发送 SIGQUIT 信号,请求堆栈抓取的操作。
- 收到 SIGQUIT 不代表当前进程发生了 ANR ,可能是手机里有一个其他的 App 发生了 ANR,如果不进行 ANR 的二次确认,就会导致 ANR 误报。
- App 可以通过进程 ANR 错误状态感知发生了前台 ANR 。
ANR 信息输出
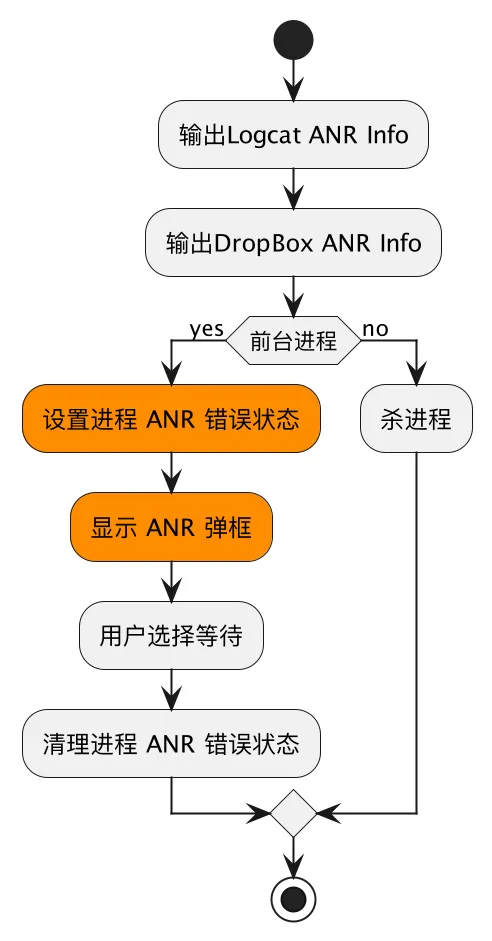
WatchDog 机制
什么是 WatchDog?
Android 系统中的WatchDog(看门狗) 是一种用于检测系统关键服务是否发生死锁或长时间阻塞的监控机制,目的是防止系统因关键服务无响应而陷入不可用状态。
WatchDog 如何工作?
初始化
Android 的 Watchdog 是一个单例线程,在 System Server 时就会初始化 Watchdog。Watchdog 在初始化时,会构建很多HandlerChecker,大致可以分为两类:
- Monitor Checker,用于检查是 Monitor 对象可能发生的死锁, AMS, PKMS, WMS 等核心的系统服务都是 Monitor 对象。
- Looper Checker,用于检查线程的消息队列是否长时间处于工作状态。Watchdog 自身的消息队列,Ui, Io, Display 这些全局的消息队列都是被检查的对象。此外,一些重要的线程的消息队列,也会加入到Looper Checker中,譬如 AMS, PKMS,这些是在对应的对象初始化时加入的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
private final ArrayList<HandlerChecker> mHandlerCheckers = new ArrayList<>();
private final HandlerChecker mMonitorChecker;
private Watchdog() {
mThread = new Thread(this::run, "watchdog");
// Initialize handler checkers for each common thread we want to check. Note
// that we are not currently checking the background thread, since it can
// potentially hold longer running operations with no guarantees about the timeliness
// of operations there.
// The shared foreground thread is the main checker. It is where we
// will also dispatch monitor checks and do other work.
mMonitorChecker = new HandlerChecker(FgThread.getHandler(),
"foreground thread", DEFAULT_TIMEOUT);
mHandlerCheckers.add(mMonitorChecker);
// Add checker for main thread. We only do a quick check since there
// can be UI running on the thread.
mHandlerCheckers.add(new HandlerChecker(new Handler(Looper.getMainLooper()),
"main thread", DEFAULT_TIMEOUT));
// Add checker for shared UI thread.
mHandlerCheckers.add(new HandlerChecker(UiThread.getHandler(),
"ui thread", DEFAULT_TIMEOUT));
// And also check IO thread.
mHandlerCheckers.add(new HandlerChecker(IoThread.getHandler(),
"i/o thread", DEFAULT_TIMEOUT));
// And the display thread.
mHandlerCheckers.add(new HandlerChecker(DisplayThread.getHandler(),
"display thread", DEFAULT_TIMEOUT));
// And the animation thread.
mHandlerCheckers.add(new HandlerChecker(AnimationThread.getHandler(),
"animation thread", DEFAULT_TIMEOUT));
// And the surface animation thread.
mHandlerCheckers.add(new HandlerChecker(SurfaceAnimationThread.getHandler(),
"surface animation thread", DEFAULT_TIMEOUT));
// Initialize monitor for Binder threads.
addMonitor(new BinderThreadMonitor());
mInterestingJavaPids.add(Process.myPid());
// See the notes on DEFAULT_TIMEOUT.
assert DB ||
DEFAULT_TIMEOUT > ZygoteConnectionConstants.WRAPPED_PID_TIMEOUT_MILLIS;
mTraceErrorLogger = new TraceErrorLogger();
}
两类HandlerChecker的侧重点不同:
- Monitor Checker预警我们不能长时间持有核心系统服务的对象锁,否则会阻塞很多函数的运行;
- Looper Checker预警我们不能长时间的霸占消息队列,否则其他消息将得不到处理。 这两类都会导致系统卡住 (System Not Responding)。
Watchdog 初始化以后,就可以作为 system_server 进程中的一个单独的线程运行了。
mHandlerCheckers 包含了所有的 HandlerChecker,包括一个 mMonitorChecker;
启动 watchdog
在 SystemServer 中启动的
1
2
3
4
5
6
7
8
9
private void startBootstrapServices(@NonNull TimingsTraceAndSlog t) {
t.traceBegin("startBootstrapServices");
// Start the watchdog as early as possible so we can crash the system server
// if we deadlock during early boot
t.traceBegin("StartWatchdog");
final Watchdog watchdog = Watchdog.getInstance();
watchdog.start();
t.traceEnd();
}
注册 watchdog 监测
AMS 注册监测
以 AMS 的注册为例:
1
2
3
4
5
6
7
8
// AMS
public ActivityManagerService(Context systemContext, ActivityTaskManagerService atm) {
Watchdog.getInstance().addMonitor(this);
Watchdog.getInstance().addThread(mHandler);
}
public void monitor() {
synchronized (this) { }
}
注册机制
注册 watchdog 监听有两种监听:addMonitor 和 addThread
addMonitor 监听死锁
1
2
3
4
5
6
7
8
9
10
11
// WatchDog.java
private final HandlerChecker mMonitorChecker;
private Watchdog() {
mMonitorChecker = new HandlerChecker(FgThread.getHandler(),
"foreground thread", DEFAULT_TIMEOUT);
}
public void addMonitor(Monitor monitor) {
synchronized (mLock) {
mMonitorChecker.addMonitorLocked(monitor);
}
}
HandlerChecker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public final class HandlerChecker implements Runnable {
private final Handler mHandler;
private final String mName;
private final long mWaitMax;
private final ArrayList<Monitor> mMonitors = new ArrayList<Monitor>();
private final ArrayList<Monitor> mMonitorQueue = new ArrayList<Monitor>();
private boolean mCompleted;
private Monitor mCurrentMonitor;
private long mStartTime;
private int mPauseCount;
HandlerChecker(Handler handler, String name, long waitMaxMillis) {
mHandler = handler;
mName = name;
mWaitMax = waitMaxMillis;
mCompleted = true;
}
void addMonitorLocked(Monitor monitor) {
// We don't want to update mMonitors when the Handler is in the middle of checking
// all monitors. We will update mMonitors on the next schedule if it is safe
mMonitorQueue.add(monitor);
}
// ...
}
把 monitor 注册到一个 mMonitorChecker 的用来保存 monitor 的叫做 mMonitorQueue 的数组中。
addThread 监听消息队列卡顿
1
2
3
4
5
6
7
8
9
10
11
12
13
// WatchDog.java
/* This handler will be used to post message back onto the main thread */
private final ArrayList<HandlerChecker> mHandlerCheckers = new ArrayList<>();
public void addThread(Handler thread) {
addThread(thread, DEFAULT_TIMEOUT);
}
public void addThread(Handler thread, long timeoutMillis) {
synchronized (this) {
final String name = thread.getLooper().getThread().getName();
mHandlerCheckers.add(new HandlerChecker(thread, name, timeoutMillis));
}
}
把这个 HandlerChecker 放入 watchdog 的用来保存 HandlerChecker 的全局容器 mHandlerCheckers 中。用来监听 Handler 的消息队列的。
总结一下
- Watchdog 提供了 HandlerChecker,是一个检查者,它可以跟踪
一个Handler的消息队列或多个自定义Monitor(注意:跟踪 Monitor 的 Checker 是一个专门的 Checker:mMonitorChecker)。 - Watchdog 提供了 Monitor 接口,实现接口的 monitor 就可以注册进 watchdog 被监听了。
- Watchdog 的构造中已经注册了多个 HandlerChecker 分别对 UiThread、IoThread、DisplayThread 等线程队列监听,其他需要注册监听的通过调用提供的 addThread 方法注册,都会单独创建一个 HandlerChecker 对其监听。
- 以上的所有 HandlerChecker 统一由全局容器 mHandlerCheckers 保存。
WatchDog 运行
1
public class Watchdog extends Thread
watchdog 实际就是一个 Thread 线程,启动方式 watchdog.start() 实际就是启动它这个线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
private static final long DEFAULT_TIMEOUT = DB ? 10 * 1000 : 60 * 1000;
private static final long CHECK_INTERVAL = DEFAULT_TIMEOUT / 2;
@Override
public void run() {
boolean waitedHalf = false;
while (true) {
final List<HandlerChecker> blockedCheckers;
final String subject;
final boolean allowRestart;
synchronized (this) {
long timeout = CHECK_INTERVAL; // 30s
// 1 遍历 mHandlerCheckers 里所有的 Checker,调用其 scheduleCheckLocked
for (int i=0; i<mHandlerCheckers.size(); i++) {
HandlerChecker hc = mHandlerCheckers.get(i);
hc.scheduleCheckLocked();
}
long start = SystemClock.uptimeMillis();
// 2 wait够CHECK_INTERVAL(30s)的时长
while (timeout > 0) {
try {
wait(timeout);
} catch (InterruptedException e) {
Log.wtf(TAG, e);
}
timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start);
}
// 3
// 遍历所有的 Checker,取其中最“糟糕”的状态
final int waitState = evaluateCheckerCompletionLocked();
if (waitState == COMPLETED) {
// COMPLETED表示所有的Checker监听的对象都没有block,
// 还原所有状态(waitedHalf 用来标记是否已经堵过半分钟了)
// 并continue本次循环
waitedHalf = false;
continue;
} else if (waitState == WAITING) {
// 发现有正在block的对象
continue;
} else if (waitState == WAITED_HALF) {
// 发现有已经block过半分钟的对象
if (!waitedHalf) {
Slog.i(TAG, "WAITED_HALF");
ArrayList<Integer> pids = new ArrayList<>(mInterestingJavaPids);
ActivityManagerService.dumpStackTraces(pids, null, null,
getInterestingNativePids(), null);
waitedHalf = true;
}
continue;
}
// 上面三个if分支都没走进去,说明已经有高于阻塞半分钟(即有对象连续两个半分钟都在block)的对象了
// 说明已经发生异常,需要处理了。
// 取出罪魁祸首,发生严重block的对象
blockedCheckers = getBlockedCheckersLocked();
// 取出问题对象们的名称、线程名等信息
subject = describeCheckersLocked(blockedCheckers);
// 标记需要重启
allowRestart = mAllowRestart;
}
EventLog.writeEvent(EventLogTags.WATCHDOG, subject);
ArrayList<Integer> pids = new ArrayList<>(mInterestingJavaPids);
// ************* 开始收集信息,写日志 *************
long anrTime = SystemClock.uptimeMillis();
StringBuilder report = new StringBuilder();
report.append(MemoryPressureUtil.currentPsiState());
ProcessCpuTracker processCpuTracker = new ProcessCpuTracker(false);
StringWriter tracesFileException = new StringWriter();
final File stack = ActivityManagerService.dumpStackTraces(
pids, processCpuTracker, new SparseArray<>(), getInterestingNativePids(),
tracesFileException);
SystemClock.sleep(5000);
processCpuTracker.update();
report.append(processCpuTracker.printCurrentState(anrTime));
report.append(tracesFileException.getBuffer());
doSysRq('w');
doSysRq('l');
Thread dropboxThread = new Thread("watchdogWriteToDropbox") {
public void run() {
if (mActivity != null) {
mActivity.addErrorToDropBox(
"watchdog", null, "system_server", null, null, null,
subject, report.toString(), stack, null);
}
FrameworkStatsLog.write(FrameworkStatsLog.SYSTEM_SERVER_WATCHDOG_OCCURRED,
subject);
}
};
dropboxThread.start();
try {
dropboxThread.join(2000);
} catch (InterruptedException ignored) {}
// ****************************************************
IActivityController controller;
synchronized (this) {
controller = mController;
}
if (controller != null) {
Slog.i(TAG, "Reporting stuck state to activity controller");
try {
Binder.setDumpDisabled("Service dumps disabled due to hung system process.");
int res = controller.systemNotResponding(subject);
if (res >= 0) {
Slog.i(TAG, "Activity controller requested to coninue to wait");
waitedHalf = false;
continue;
}
} catch (RemoteException e) {
}
}
// 退出系统
if (!allowRestart) {
Slog.w(TAG, "Restart not allowed: Watchdog is *not* killing the system process");
} else {
Slog.w(TAG, "*** WATCHDOG KILLING SYSTEM PROCESS: " + subject);
WatchdogDiagnostics.diagnoseCheckers(blockedCheckers);
Slog.w(TAG, "*** GOODBYE!");
Process.killProcess(Process.myPid());
System.exit(10);
}
waitedHalf = false;
}
}
watchdog 的策略 block 上限是 60s。
run 方法里就是一个无限死循环,在循环体内主要分三步走:
- 发起一次所有 Checker 的检查,
- 等待 30s,
- 检查所有 Checker 监听的对象的状态,根据状态判断是否需要 dump 以及重启,如果不需要就跳入下一次循环。
1、发起 Checker 的检查
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// HandlerChecker.java
public void scheduleCheckLocked() {
if (mCompleted) {
mMonitors.addAll(mMonitorQueue);
mMonitorQueue.clear();
}
if ((mMonitors.size() == 0 && mHandler.getLooper().getQueue().isPolling())
|| (mPauseCount > 0)) {
mCompleted = true;
return;
}
if (!mCompleted) {
return;
}
// 设置状态未完成
mCompleted = false;
mCurrentMonitor = null;
// 记录发起时间
mStartTime = SystemClock.uptimeMillis();
// 向被监听的对象的消息队列发送一个检查消息this,消息将会执行run方法
mHandler.postAtFrontOfQueue(this);
}
@Override
public void run() {
final int size = mMonitors.size();
// monitor的检测,遍历所有注册进来的monitor,检测方式就是调用它的monitor方法
for (int i = 0 ; i < size ; i++) {
synchronized (Watchdog.this) {
mCurrentMonitor = mMonitors.get(i);
}
mCurrentMonitor.monitor();
}
synchronized (Watchdog.this) {
// 执行到这里,说明消息队列没堵塞,并且monitor也都没堵塞,把状态改为true
mCompleted = true;
mCurrentMonitor = null;
}
}
发起检查实际就是用注册进来的 Handler 发送一个监测消息,如果消息队列没阻塞,消息就能正常执行(就是自己的 run 方法),在 run 方法里还有 monitor 的检测,如果检测都通过了,就把状态 mCompleted 改回 true。
2、等待 30 秒
1
2
3
4
5
6
7
8
9
10
11
private static final long DEFAULT_TIMEOUT = (DB ? 10 * 1000 : 60 * 1000) * Build.HW_TIMEOUT_MULTIPLIER;
private static final long CHECK_INTERVAL = DEFAULT_TIMEOUT / 2;
long timeout = CHECK_INTERVAL;
while (timeout > 0) {
try {
wait(timeout);
} catch (InterruptedException e) {
Log.wtf(TAG, e);
}
timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start);
}
3、收集 1 发起的检查结果
evaluateCheckerCompletionLocked:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
private int evaluateCheckerCompletionLocked() {
int state = COMPLETED;
for (int i=0; i<mHandlerCheckers.size(); i++) {
HandlerChecker hc = mHandlerCheckers.get(i);
state = Math.max(state, hc.getCompletionStateLocked());
}
return state;
}
// HandlerChecker
public int getCompletionStateLocked() {
if (mCompleted) {
// mCompleted = true,看步骤1讲解,1发起的消息run已经执行完了
// 返回 COMPLETED
return COMPLETED;
} else {
// latency:从1发起消息到现在的耗时时长
long latency = SystemClock.uptimeMillis() - mStartTime;
if (latency < mWaitMax/2) {
// 小于半分钟,给 WAITING
return WAITING;
} else if (latency < mWaitMax) {
// 半分钟 < 1分钟,给WAITED_HALF
return WAITED_HALF;
}
// 这两个都不符合,说明已经超过1分钟,给 OVERDUE
}
return OVERDUE;
}
这个 mWaitMax 时长是创建 Checker 时构造传入的,当前代码中看给的都是 DEFAULT_TIMEOUT 1 分钟
Checker 一共提供了 4 种状态:
- COMPLETED:如果步骤 1 发起的检查消息执行完成会把 mCompleted 设置为 true,表示 Checker 检查通过,当前没有谁 block
- WAITING:步骤 1 发起的检查消息未完成,当前收集状态时间 - 检查消息的发起时间 < 30s
- WAITED_HALF:步骤 1 发起的检查消息未完成,30 < 当前收集状态时间 - 检查消息的发起时间 < 60s
- OVERDUE:步骤 1 发起的检查消息未完成,当前收集状态时间 - 检查消息的发起时间 > 60s
其他
暂停监测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public void pauseWatchingCurrentThread(String reason) {
synchronized (this) {
for (HandlerChecker hc : mHandlerCheckers) {
if (Thread.currentThread().equals(hc.getThread())) {
hc.pauseLocked(reason);
}
}
}
}
public void resumeWatchingCurrentThread(String reason) {
synchronized (this) {
for (HandlerChecker hc : mHandlerCheckers) {
if (Thread.currentThread().equals(hc.getThread())) {
hc.resumeLocked(reason);
}
}
}
}
使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
t.traceBegin("StartPackageManagerService");
try {
Watchdog.getInstance().pauseWatchingCurrentThread("packagemanagermain");
mPackageManagerService = PackageManagerService.main(mSystemContext, installer,
mFactoryTestMode != FactoryTest.FACTORY_TEST_OFF, mOnlyCore);
} finally {
Watchdog.getInstance().resumeWatchingCurrentThread("packagemanagermain");
}
t.traceBegin("StartOtaDexOptService");
try {
Watchdog.getInstance().pauseWatchingCurrentThread("moveab");
OtaDexoptService.main(mSystemContext, mPackageManagerService);
} catch (Throwable e) {
reportWtf("starting OtaDexOptService", e);
} finally {
Watchdog.getInstance().resumeWatchingCurrentThread("moveab");
t.traceEnd();
}
出现的场景有比如开机 PackageManagerService 启动做包扫描、dex 优化等场景会调用暂停 watchdog 检查。推测是这些场景本身就是十分耗时的,并且是在开机的必须过程,从设计上看需要这样做,就暂时把 watchdog 检查关闭了。
Binder 监测
1
2
3
4
private Watchdog() {
// ...
// Initialize monitor for Binder threads.
addMonitor(new BinderThreadMonitor());
Watchdog 构造的时候注册了一个 BinderThreadMonitor
1
2
3
4
5
6
private static final class BinderThreadMonitor implements Watchdog.Monitor {
@Override
public void monitor() {
Binder.blockUntilThreadAvailable();
}
}
可以看到 monitor 监测调用的 Binder.blockUntilThreadAvailable,最终调用到 IPCThreadState::blockUntilThreadAvailable
//IPCThreadState
void IPCThreadState::blockUntilThreadAvailable()
{
pthread_mutex_lock(&mProcess->mThreadCountLock);
while (mProcess->mExecutingThreadsCount >= mProcess->mMaxThreads) {
ALOGW("Waiting for thread to be free. mExecutingThreadsCount=%lu mMaxThreads=%lu\n",
static_cast<unsigned long>(mProcess->mExecutingThreadsCount),
static_cast<unsigned long>(mProcess->mMaxThreads));
pthread_cond_wait(&mProcess->mThreadCountDecrement, &mProcess->mThreadCountLock);
}
pthread_mutex_unlock(&mProcess->mThreadCountLock);
}
blockUntilThreadAvailable 是判断进程当前正在运行的 binder 线程是否达到最大值,如果超出 mMaxThreads 就阻塞。可以看出这个 monitor 的意图就是检查进程的 binder 线程是否满了。
watchdog 是在 systemserver 进程启动的,这里监测的进程的 binder 线程是否满了,实际就是监测的 systemserver 进程。
1
2
3
4
5
6
7
8
9
10
private void startBootstrapServices(@NonNull TimingsTraceAndSlog t) {
t.traceBegin("startBootstrapServices");
// Start the watchdog as early as possible so we can crash the system server
// if we deadlock during early boot
t.traceBegin("StartWatchdog");
final Watchdog watchdog = Watchdog.getInstance();
watchdog.start();
t.traceEnd();
ANR 中的 watchdog
在 bugreport 当中发生 Watchdog 的日志,非常明显,要想初步定位问题,可以现在 event log 中搜索 watchoog 对应的关键字。
当发生 Watchdog 检测超时的系统事件时,在 Android 中会打印一个 EventLog:
1
2
watchdog: Blocked in handler XXX # 表示HandlerChecker超时了
watchdog: Blocked in monitor XXX # 表示MonitorChecker超时了
Watchdog 是运行在 system_server 中的一个线程,往往发生 Watchdog 的时候,意味着此时 system_server 已经被 kill 掉,导致 zygote 重启。因此着这一阶段也会打印很多 system 的 log。如果 bugreprot 中搜索到以下关键字,也能说明发生 Watchdog。
1
2
3
Watchdog: *** WATCHDOG KILLING SYSTEM PROCESS: XXX
Watchdog: XXX
Watchdog: "*** GOODBYE!
当在 bugreport 中检索到以上信息,就需要了解发生 watchdog 之前 ,system_server 正在干什么,处于一种什么样的状态。因此我们需要知道 trace 信息,cpu 信息,IO 信息等等,因此我们可以去/data/anr 目录下找对应时间点的 trace 文件进行分析。在大多数情况下,引起 watchdog 的直接原因是 system_server 中某一处线程阻塞导致。
bugreprot 中 system log
1
Watchdog: *** WATCHDOG KILLING SYSTEM PROCESS: Blocked in monitor com.android.server.wm.WindowManagerService on foreground thread (android.fg)
这里 Watchdog 告诉我们Monitor Checker超时了, 名为android.fg的线程在 WindowManagerService 的 monitor() 方法被阻塞了。打开对应时间点的 anr trace 寻找 android.fg 线程
ANR trace 含义
下方 trace 调用栈表示 android.fg 线程此时的状态是 blocked,且由 Watchdog 发起调用 monitor(),这是一个 Watchdog 检查,阻塞已经超时。该线程正在等 tid=91 的线程所持有的的一把 0x126dccb8 锁,具体阻塞原因我们需要查看 tid=91 线程的堆栈情况进行合理分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
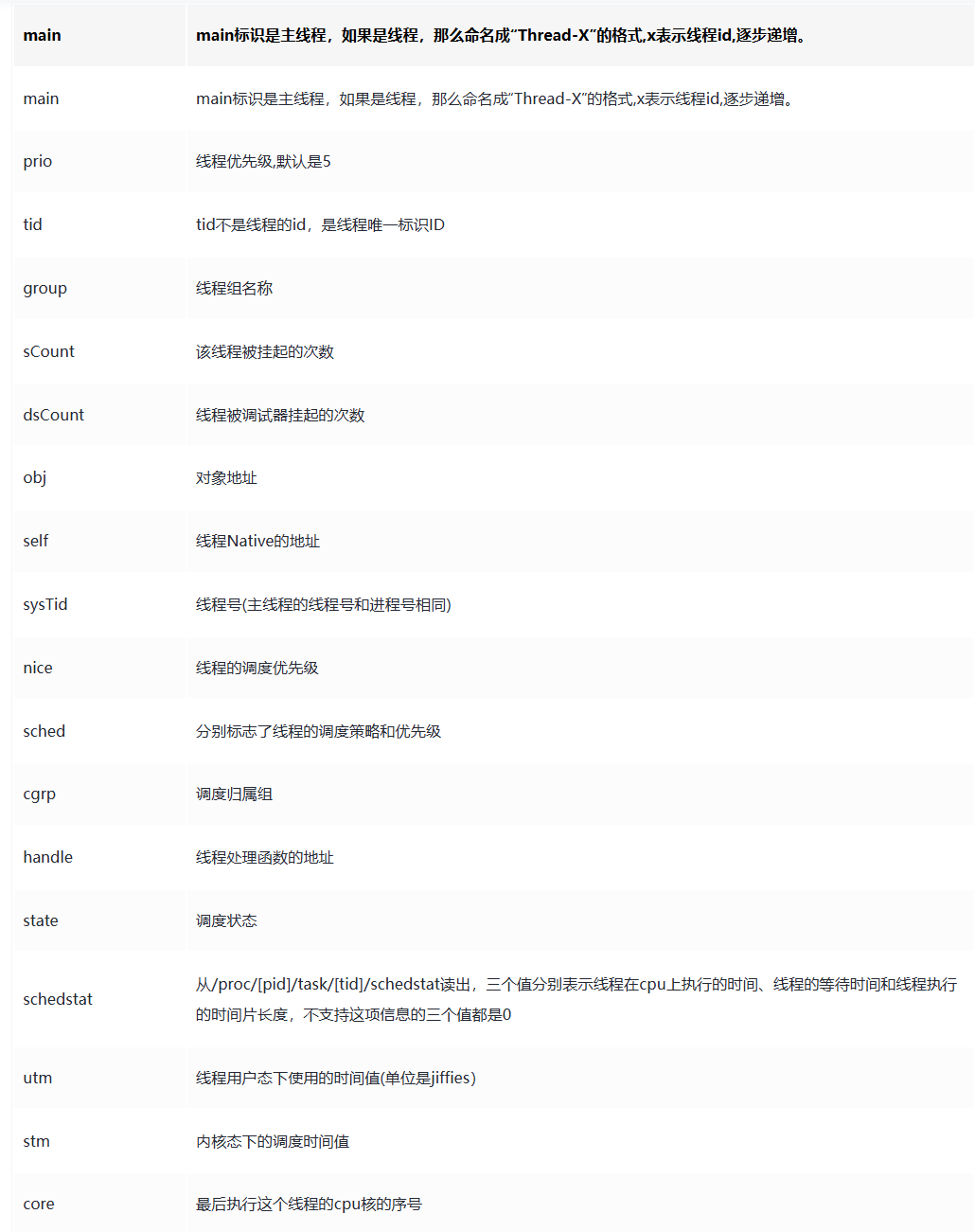
"android.fg" prio=5 tid=25 Blocked
| group="main" sCount=1 dsCount=0 obj=0x12eef900 self=0x7f7a8b1000
| sysTid=973 nice=0 cgrp=default sched=0/0 handle=0x7f644e9000
| state=S schedstat=( 3181688530 2206454929 8991 ) utm=251 stm=67 core=1 HZ=100
| stack=0x7f643e7000-0x7f643e9000 stackSize=1036KB
| held mutexes=
at com.android.server.wm.WindowManagerService.monitor(WindowManagerService.java:13125)
- waiting to lock <0x126dccb8> (a java.util.HashMap) held by thread 91
at com.android.server.Watchdog$HandlerChecker.run(Watchdog.java:204)
at android.os.Handler.handleCallback(Handler.java:815)
at android.os.Handler.dispatchMessage(Handler.java:104)
at android.os.Looper.loop(Looper.java:194)
at android.os.HandlerThread.run(HandlerThread.java:61)
at com.android.server.ServiceThread.run(ServiceThread.java:46)
[ANR trace] 参数含义:
分析流程
根据 watchdog 产生后,抓取的 bugreport 中确定 watchdog 发生的时间,再去找相应的时间段的 anrtrace 日志
- 思考为什么会发生 watchdog 事件?在日志中找到发生 watchdog 的对应时间、对应 block 的线程
- 分析线程的堆栈信息,确认线程阻塞的根本原因(是否出现死锁、binder 线程池是否满了,binder 通信阻塞等)根据具体堆栈具体分析。