10.C++杂项
C++ 头文件
什么是头文件?
在 C++ 中,头文件是一种源代码文件,通常包含两类内容:函数声明(也称为原型)和宏定义(包括模板、常量、内联函数)。头文件的主要目的是提供一个声明的集合,这些声明可以在许多不同的源文件之间共享。
头文件使用 .h 或 .hpp 作为文件扩展名。.h 是传统扩展名,而 .hpp 效仿 .cpp (C++ 的源文件扩展名),用于显式标明这是一个 C++ 头文件。
头文件的作用:
- 代码复用: 通过在多个源文件中包含同一头文件,你可以在不同的源代码文件中重用定义的类、函数和模板。
- 接口与实现分离: 在头文件中写入函数的声明(而不是其实现),可以使你分享接口而不是实现。实现通常放在
.cpp文件中,只有对应的声明在头文件中公开。 - 避免重复定义: 如果不小心在一个源文件中包括同一头文件多次,或在不同的源文件中多次声明相同的标识符,将会引发编译错误。为了防止这种情况,通常使用预处理器指令(如宏
#ifndef、#define和#endif)来确保头文件只被包含一次,这称为 “ 包含卫士 “。 - 提高编译效率: 将声明放在头文件中,而让定义分散在多个
.cpp文件中,可以提高代码编译的效率,因为头文件的改变不会导致所有使用它的源文件都需要重新编译。
头文件是 C++ 编程中组织和封装代码逻辑的重要工具,正确使用头文件可以使代码更加模块化、易于维护,并促进团队协作。
避免重复引入头文件
include Guards
使用 #ifndef/#define/#endif,这种方法使用预处理指令来确保头文件内容只被编译一次。它的工作原理是在头文件的顶部和底部使用 #ifndef 和 #endif 指令包围所有代码,并在中间使用 #define 来定义一个唯一的宏:
1
2
3
4
5
6
#ifndef SOME_UNIQUE_NAME_HERE
#define SOME_UNIQUE_NAME_HERE
... ... // 声明、定义语句
#endif // SOME_UNIQUE_NAME_HERE
当头文件首次被包含时,SOME_UNIQUE_NAME_HERE 还未定义,所以预处理器会定义它,并包含头文件的内容。如果头文件后续再次被包含,由于 SOME_UNIQUE_NAME_HERE 已定义,文件内的代码会被跳过。
这种方法是标准的 C++ 实践,所有主流编译器都支持它,因此具有良好的跨平台性和可移植性。
特点:
- 跨平台
- 可针对文件也可针对代码片段。
- 编译慢,有宏命名冲突的风险。
#pragma
#pragma once 是一种非标准的预处理指令,用于告诉编译器当前头文件仅应被包含(include)一次,无论它被实际的文件包含了多少次。
1
2
3
4
5
6
// 假设编译器支持 #pragma once 指令,避免一个头文件被多次包含
#pragma once
class MyClass {
// 类成员
};
尽管 #pragma once 非常方便,但它不是 C++ 标准的一部分。尽管大多数现代编译器(包括 GCC、Clang、MSVC)都支持这个指令,但在一些不常见的编译器或者较老的编译环境里可能不支持,所以它的可移植性略低。
特点:
- 不跨平台
- 只能针对文件
- 编译快,无宏命名冲突的风险。
预编译头文件
在 C++ 中,预编译头文件(Precompiled Headers,简称 PCH)是一种机制,用于减少编译时间,提高编译效率。预编译头文件通常包含编译一次后就很少变动的头文件,如标准库头文件或者项目中公共头文件。
原理: C++ 编译器在编译过程中需要处理源文件中的 #include 指令,这通常涉及读取头文件内容、处理预处理器指令及展开宏等操作。当一个头文件被多个源文件包含时,相同的处理工作会多次执行,导致编译效率降低。预编译头文件通过将头文件预处理的结果存储到一个预编译头文件(通常拥有 .pch 或 .gch 等扩展名)中,再次编译时可以直接使用这个预处理结果,从而省去了重复处理头文件的工作。
优点:
- 减少编译时间: 由于共用的头文件内容已经预编译,编译器无需重复处理这些头文件,从而缩短编译时间。
- 优化常规开发流程: 开发人员更改自己的源代码文件比修改公共头文件更为频繁,因此预编译头文件能更好地适应这种开发模式。
局限性:
- 可移植性差: 不同的编译器处理预编译头文件的方式不同,可能不兼容。
- 更新问题: 如果预编译头文件中包含的任何头文件被修改,预编译头文件需要重新编译,否则可能导致编译错误或者运行时错误。
预编译头文件方法
创建预编译头文件。 在项目中选择几乎每个源文件都会用到的头文件,如
<iostream>、<vector>等标准库文件,以及项目中的公共头文件。创建一个包含这些头文件的.h文件,例如pch.h。编译预编译头文件。 使用编译器特定的指令或者编译器选项来编译这个头文件,生成对应的
.pch或.gch文件。例如,在 Visual Studio 中,这通常是自动完成的。在源文件中使用预编译头文件。 在需要用到那些公共头文件的源文件的起始处,通过
#include "pch.h"来包含预编译头文件。编译器会自动查找到对应的预编译头文件并使用。注意:#include "pch.h"应该是源文件中第一个包含的条目,除非需要包含其他特定的宏或者属性定义。
Visual Studio 中预编译头文件
在 Visual Studio 中,你可以创建和使用预编译头文件(通常命名为 stdafx.h,但这不是强制性的)来提高编译速度,特别是对于大型项目。这里是如何预编译头文件的步骤:
- 创建预编译头文件:
首先,创建一个头文件,通常命名为 stdafx.h(这是传统名称,但你可以使用任何名称),并添加你项目中不经常改变且常常使用的头文件,例如:
1
2
3
4
5
6
7
8
9
10
11
// stdafx.h
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <array>
#include <algorithm>
#include <functional>
#include <memory>
// ...其他你想预编译的头文件
- 创建源文件:
创建一个源文件与预编译头文件关联,通常命名为 stdafx.cpp,这个文件应该非常简单:
1
2
// stdafx.cpp
#include "stdafx.h"
- 使用 VS 配置预编译头文件:
在解决方案资源管理器中,右键点击你刚刚创建的 stdafx.cpp 文件,选择 “ 属性 “。在 C/C++ -> 预编译头文件 部分,将预编译头文件设置为 “创建 (/Yc)“,并指定你的预编译头文件名称 stdafx.h。
| 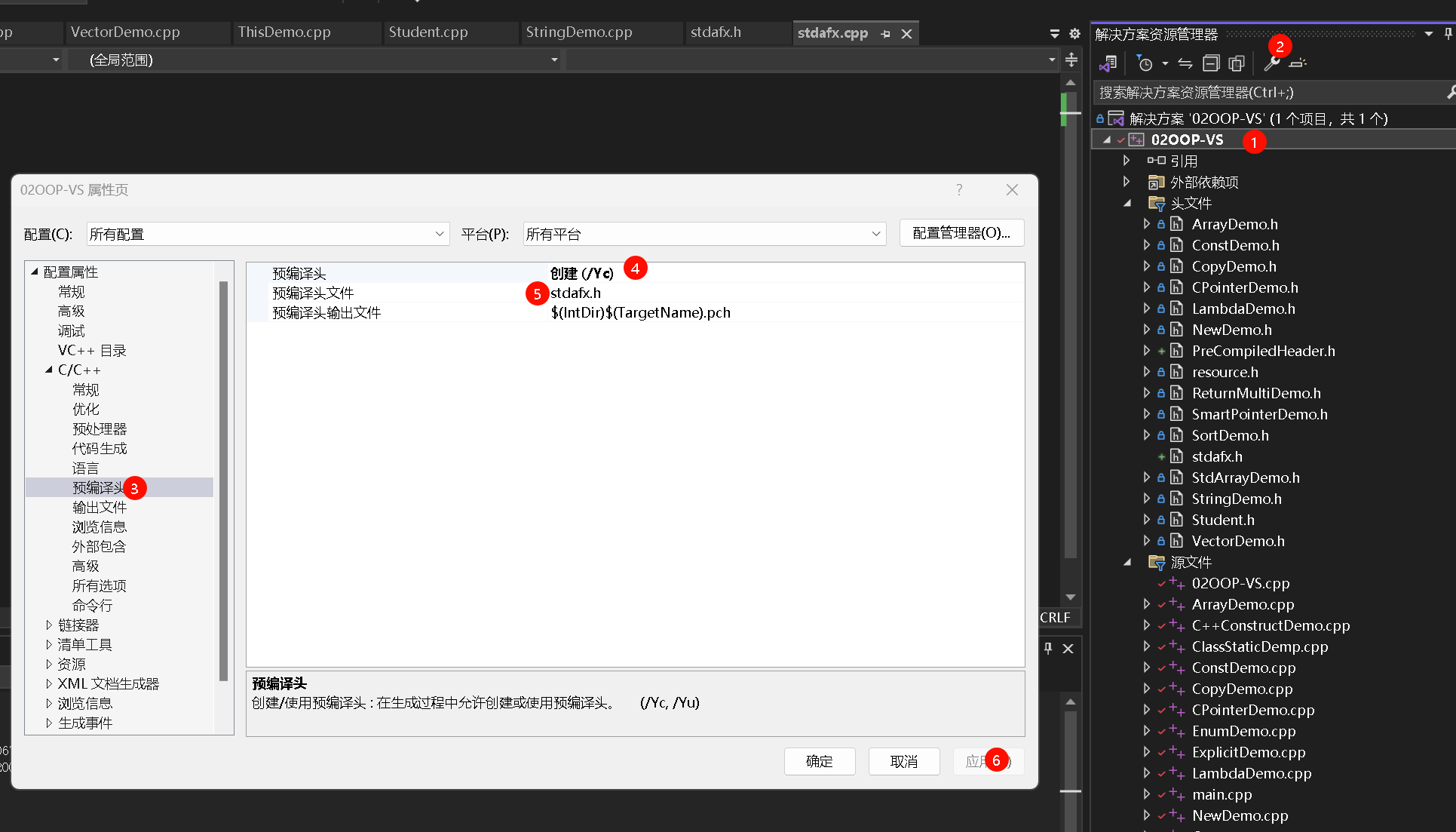 |
- 使用预编译头文件:
在你项目的其它源文件中,stdafx.h 应该是第一个包含项。这样设置后,编译器在编译源文件之前会先加载预编译头文件的内容。
1
2
3
// other.cpp
#include "stdafx.h"
// ...你的源代码
VS 中当前解决方案都得导入
stdafx.h,否则编译报错
- 编译:
当你构建项目时,Visual Studio 会自动先编译 stdafx.cpp,创建预编译头文件(.pch),随后这个 .pch 文件会在其他编译单元的编译中被使用。
请注意,添加了预编译头文件后,任何在预编译头文件之前包含的头文件都不会受益于预编译头文件的优势。因此,请确保 #include "stdafx.h” 在源文件中的其他包含之前。同时,当你改变预编译头文件中的内容时,整个项目会被重新编译,因为 .pch 文件需要更新。因此,确保只将不会经常更改的头文件放到预编译头文件中。
g++ 预编译头文件
在 g++ 中:
首先确保 main.cpp(主程序文件)、pch.cpp(包含预编译头文件的 cpp 文件)、pch.h(预编译头文件)在同一源文件目录下
注:pch.h 文件的名字是自己命名的,改成其他名称也没问题。
1
2
3
g++ -std=c++11 pch.h #开启并行编译,Gradle默认一次只执行一个Task,即串行,那我们就可以通过配置让Gradle并行来执行Task,从而提升构建效率,缩短构建时间。 先编译pch头文件
#time的作用是在控制台显示编译所需要的时间。
time g++ -std=c++11 main.cpp #然后编译主程序文件即可,编译速度大大提升。
C++ namespace 命名空间
namespace 介绍
namespace 命名空间相当于 Java 中的 package
- 命名空间是 C++ 独有,主要用于避免命名冲突;C 是没有的,故写 C 时会有命名冲突的风险。
- namespace 定义名称空间;namespace 能够嵌套
::域操作符引用名称空间;也可以操作全局变量- 类本身就是名称空间:类外使用一个类内的成员需要加
::
1
2
3
4
5
6
7
namespace A{
void a(){}
}
// 错误: a();
// :: 域操作符
// 正确: A::a();
名称空间定义嵌套:
1
2
3
4
5
6
7
//当然也能够嵌套
namespace A {
namespace B {
void a() {};
}
}
A::B::a();
使用名称空间:
1
2
3
// 还能够使用using 关键字
using namespace A;
using namespace A::B; // 嵌套使用
当全局变量在局部函数中与其中某个变量重名,那么就可以用:: 来区分
1
2
3
4
5
6
7
8
int i;
int main(){
int i = 10;
printf("i : %d\n",i);
//操作全局变量
::i = 11;
printf("i : %d\n",::i);
}
namespace 定义
1. 每个命名空间都是一个作用域
同其他作用域类似,命名空间中的每个名字都必须表示该空间内的唯一实体。因为不同命名空间的作用域不同,所以在不同命名空间内可以有相同名字的成员。
2. 命名空间可以不连续
命名空间的定义可以不连续的特性使得我们可以将几个独立的接口和实现文件组成一个命名空间,定义多个类型不相关的命名空间也应该使用单独的文件分别表示每个类型。
3. 模板特例化
模板特例化必须定义在原始模板所属的命名空间中,和其他命名空间名字类似,只要我们在命名空间中声明了特例化,就能在命名空间外部定义它了:
1
2
3
4
5
6
7
8
9
10
11
12
// 我们必须将模板特例化声明成std的成员
namespace std {
template <> struct hash<Foo>;
}
// 在std中添加了模板特例化的声明后,我们就可以在命名空间std的外部定义它了
template<> struct std::hash<Foo> {
size_t operator()(const Foo& f) const {
return hash<string>()(f.str) ^
hash<double>()(f.d);
}
};
4. 全局命名空间 全局作用域中定义的名字(即在所有类、函数以及命名空间之外定义的名字)也就是定义在全局命名空间 global namespace 中。全局作用域是隐式的,所以它并没有名字,下面的形式表示全局命名空间中一个成员:
1
::member_name
5. 嵌套的命名空间
1
2
3
4
5
6
7
8
namespace foo {
namespace bar {
class Cat { /*...*/ };
}
}
// 调用方式
foo::bar::Cat
6. 内联命名空间 C++11 新标准引入了一种新的嵌套命名空间,称为内联命名空间 inline namespace。内联命名空间可以被外层命名空间直接使用。定义内联命名空间的方式是在关键字 namespace 前添加关键字 inline:
1
2
3
4
5
6
7
8
// inline必须出现在命名空间第一次出现的地方
inline namespace FifthEd {
// ...
}
// 后续再打开命名空间的时候可以写inline也可以不写
namespace FifthEd { // 隐式内敛
// ...
}
当应用程序的代码在一次发布和另一次发布之间发生改变时,常使用内联命名空间。
例如我们把第五版 FifthEd 的所有代码放在一个内联命名空间中,而之前版本的代码都放在一个非内联命名空间中:
1
2
3
4
5
6
7
8
9
10
namespace FourthEd {
// 第4版用到的其他代码
class Cat { /*...*/ };
}
// 命名空间cplusplus_primer将同时使用这两个命名空间
namespace foo {
#include "FifthEd.h"
#include "FoutthEd.h"
}
因为 FifthEd 是内联的,所以形如 foo:: 的代码可以直接获得 FifthEd 的成员,如果我们想用到早期版本的代码,则必须像其他嵌套的命名空间一样加上完整的外层命名空间名字:
1
foo::FourthEd::Cat
7. 未命名的命名空间 关键字 namespace 后紧跟花括号括起来的一系列声明语句是未命名的命名空间 unnamed namespace。未命名的命名空间中定义的变量具有静态生命周期:它们在第一次使用前被创建,直到程序结束时才销毁。
每个文件定义自己的未命名的命名空间,如果两个文件都含有未命名的命名空间,则这两个空间互相无关。在这两个未命名的命名空间里面可以定义相同的名字,并且这些定义表示的是不同实体。如果一个头文件定义了未命名的命名空间,则该命名空间中定义的名字将在每个包含了该头文件的文件中对应不同实体。
和其他命名空间不同,未命名的命名空间仅在特定的文件内部有效,其作用范围不会横跨多个不同的文件。未命名的命名空间中定义的名字的作用域与该命名空间所在的作用域相同,如果未命名的命名空间定义在文件的最外层作用域中,则该命名空间一定要与全局作用域中的名字有所区别:
1
2
3
4
5
6
7
8
// i的全局声明
int i;
// i在未命名的命名空间中的声明
namespace {
int i;
}
// 二义性错误: i的定义既出现在全局作用域中, 又出现在未嵌套的未命名的命名空间中
i = 10;
未命名的命名空间取代文件中的静态声明:
在标准 C++ 引入命名空间的概念之前,程序需要将名字声明成 static 的以使其对于整个文件有效。在文件中进行静态声明的做法是从 C 语言继承而来的。在 C 语言中,声明为 static 的全局实体在其所在的文件外不可见。 在文件中进行静态声明的做法已经被 C++ 标准取消了,现在的做法是使用未命名的命名空间。
为什么不推荐使用 using namespace std
- 不容易分辨各类函数的来源
比如我在一个自己的库中定义了一个 vector,而标准库里又有一个 vector,那么如果用了 using namespace std 后,所用的 vector 到底是哪里的 vector 呢?
1
2
3
4
5
6
std::vector<int>vec1; //good
DiyClass::vector<int>vec2 //good
using namespace std;
using namespace DiyClass // 万一有其他人用了DiyClass的命名空间
vector<int>vec3 // 便会有歧义,完全不知道到底是哪里的vector
- 一定不要在头文件内使用
using namespace std
如果别人用了你的头文件,就会把这些命名空间用在了你原本没有打算用的地方,会导致莫名其妙的产生 bug,如果有大型项目,追踪起来会很困难。 如果公司有自己的模板库,然后里面有很多重名的类型或者函数,就容易弄混;
- 可以就在一些小作用域里用,但能不用就不用,养成良好的代码书写习惯。
C++ 类型转换
除了能使用 C 语言的强制类型转换外。还有:转换操作符 static_cast dynamic_cast reinterpret_cast const_cast
static_cast
static_cast用于进行比较 “ 自然 “ 和低风险的转换,如整型和浮点型、字符型之间的互相转换,不能用于指针类型的强制转换只适用基础类型之间互转。如:float 转成 int、int 转成 unsigned int 等- 指针与
void之间互转。如float*转成void*、Bean*转成void*、函数指针转成void*等 - 子类指针/引用与父类指针/引用转换。
示例 1:
1
2
3
4
5
double dPi = 3.1415926;
int num = static_cast<int>(dPi); //num的值为3
double d = 1.1;
void *p = &d;
double *dp = static_cast<double *>(p);
示例 2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Parent {
public:
/*virtual*/ void test() {
cout << "p" << endl;
}
};
class Child :public Parent{
public:
void test() {
cout << "c" << endl;
}
};
Parent *p = new Parent;
Child *c = static_cast<Child*>(p);
// 输出c
c->test();
// Parent test加上 virtual 输出 p
dynamic_cast 多态
dynamic_cast编译期不检查转换安全性,仅运行时检查。支持运行时类型识别 (run-time type identification,RTTI)。- 如果不能转换,返回 NULL;使用时需要保证是多态,即基类里面含有虚函数。
主要将基类指针、引用安全地转为派生类,在运行期对可疑的转型操作进行安全检查,仅对多态有效。 适用于以下情况:我们想使用基类对象的指针或引用执行某个派生类操作并且该操作不是虚函数。一般来说,只要有可能我们应该尽量使用虚函数,使用 RTTI 运算符有潜在风险,程序员必须清楚知道转换的目标类型并且必须检查类型转换是否被成功执行。
示例 1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//基类至少有一个虚函数
//对指针转换失败的得到NULL,对引用失败 抛出bad_cast异常
Parent *p = new Parent;
Child *c = dynamic_cast<Child*>(p);
if (!c) {
cout << "转换失败" << endl;
}
Parent *p = new Child;
Child *c = dynamic_cast<Child*>(p);
if (c) {
cout << "转换成功" << endl;
}
- 使用形式
1
2
3
dynamic cast<type*> (e) //e必须是一个有效的指针
dynamic cast<type&> (e) //e必须是一个左值
dynamic cast<type&&> (e) //e不能是左值
type 必须是一个类类型,并且通常情况下该类型应该含有虚函数。在上面的所有形式中,e 的类型必须符合以下三个条件中的任意一个:
- e 的类型是目标 type 的公有派生类
- e 的类型是目标 type 的公有基类
- e 的类型就是目标 type 的类型。
如果符合,则类型转换可以成功。否则,转换失败。
- 如果一条
dynamic_cast语句的转换目标是指针类型并且失败了,则结果为 0
1
2
3
4
5
6
7
8
9
10
//假定Base类至少含有一个虚函数,Derived是Base的公有派生类。
//如果有一个指向Base的指针bp,则我们可以在运行时将它转换成指向Derived的指针。
if (Derived *dp = dynamic_cast<Derived *>bp) //在条件部分执行dynamic_cast操作可以确保类型转换和结果检查在同一条表达式中完成。
{
//成功。使用dp指向的Derived对象
}
else
{
//失败。使用bp指向的Base对象
}
- 如果转换目标是引用类型并且失败了,则
dynamic_cast运算符将抛出一个 bad cast 异常。
1
2
3
4
5
6
7
8
9
// 引用类型的dynamic_cast与指针类型的dynamic_cast在表示错误发生的方式上略有不同。因为不存在所谓的空引用,所以对于引用类型来说无法使用与指针类型完全相同的错误报告策略。当对引用的类型转换失败时,程序抛出一个名为std::bad cast的异常,该异常定义在typeinfo标准库头文件中。
void f(const Base&b) {
try {
const Derived &d = dynamic cast<const Derived&>(b);
// 使用b引用的Derived对象
} catch(bad cast) {
// 处理类型转换失败的情况
}
}
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include<iostream>
class Base
{
public:
virtual void print(){}
};
class Player : public Base
{
};
class Enemy : public Base
{
};
int main()
{
Player* player = new Player();
Base* base = new Base();
Base* actualEnemy = new Enemy();
Base* actualPlayer = new Player();
// 旧式转换
Base* pb1 = player; // 从下往上,是隐式转换,安全
Player* bp1 = (Player*)base; // 从上往下,可以用显式转换,危险
Enemy* pe1 = (Enemy*)player; // 平级转换,可以用显式转换,危险
// dynamic_cast
Base* pb2 = dynamic_cast<Base*>(player); // 从下往上,成功转换
Player* bp2 = dynamic_cast<Player*>(base); // 从上往下,返回NULL
if(bp2) { } // 可以判断是否转换成功
Enemy* pe2 = dynamic_cast<Enemy*>(player); // 平级转换,返回NULL
Player* aep = dynamic_cast<Player*>(actualEnemy); // 平级转换,返回NULL
Player* app = dynamic_cast<Player*>(actualPlayer); // 虽然是从上往下,但是实际对象是player,所以成功转换
}
const_cast
const_cast添加或者移除const性质:改类型的 const 或 volatile 属性
示例 1:
1
2
3
4
5
6
7
8
9
10
11
const string &shorterString(const string &s1, const string &s2)
{
return s1.size() <= s2.size() ? s1 : s2;
}
//上面函数返回的是常量string引用,当需要返回一个非常量string引用时,可以增加下面这个函数
string &shorterString(string &s1, string &s2) //函数重载
{
auto &r = shorterString(const_cast<const string &>(s1), const_cast<const string &>(s2));
return const_cast<string &>(r);
}
示例 2:
1
2
3
4
5
const char *a;
char *b = const_cast<char*>(a);
char *aa;
const char *bb = const_cast<const char *>(aa);
reinterpret_cast 强制转换
reinterpret_cast 用于进行各种不同类型的指针之间强制转换。
对指针、引用进行原始转换;通常为运算对象的位模式提供较低层次上的重新解释。危险,不推荐。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
float i = 10;
//&i float指针,指向一个地址,转换为int类型,j就是这个地址
int j = reinterpret_cast<int>(&i);
cout << hex << &i << endl;
cout << hex << j << endl;
cout<<hex<<i<<endl; //输出十六进制数
cout<<oct<<i<<endl; //输出八进制数
cout<<dec<<i<<endl; //输出十进制数
// int*转换为char*
int *ip;
char *pc = reinterpret_cast<char *>(ip);
char* 与 int 转换
- atoi(
char*)char*转 int - atof(
char*)char*转 float itoa()int 转char*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//char* 转int float
int i = atoi("1");
float f = atof("1.1f");
cout << i << endl;
cout << f << endl;
//int 转 char*
char c[10];
//10进制
itoa(100, c,10);
cout << c << endl;
//int 转 char*
char c1[10];
sprintf(c1, "%d", 100);
cout << c1 << endl;
C++ 宏
什么是宏?
在 C++ 中,宏是预处理指令,用于在编译之前对源代码进行简单的文本替换。宏由预处理器处理。
- 预处理阶段 :当编译 C++ 代码时,首先预处理器会过一遍 C++ 所有的以
#符号开头(这是预编译指令符号)的语句,当预编译器将这些代码评估完后给到编译器去进行实际的编译。 - 宏和模板的区别:发生时间不同,宏是在预处理阶段就被评估了,而模板会被评估的更晚一点。
- 用宏的目的: 写一些宏将代码中的文本替换为其他东西(纯文本替换)(不一定是简单的替换,是可以自定义调用宏的方式的)
宏在处理时间上非常有效,因为它们只是简单的文本替换,而且不占用任何内存。但是宏函数有一些缺点,例如它们不进行类型检查,不支持作用域规则,而且多次评估其参数,可能导致一些意想不到的副作用。因此,在现代的 C++ 编程中,推荐使用常量、内联函数和模板,这些可以提供更好的类型安全性和错误检查。使用宏时总需要小心,以免引入难以发现的错误。
宏使用场景
包含其他文件 include
1
#include <iostream>
编译提示 pragma
使用 #pragma 指令用于提供额外的编译器指示,该指示依编译器的不同而有不同的效果。
1
2
3
4
5
6
// 假设编译器支持 #pragma once 指令,避免一个头文件被多次包含
#pragma once
class MyClass {
// 类成员
};
定义常量 #define
使用 #define 指令定义字面量常量,而非 const 或 enum 类型,尽管后者通常更受推荐。
1
2
3
4
5
6
7
8
9
10
11
12
// 示例1:
#define MAX_SIZE 100
int buffer[MAX_SIZE];
// 示例2:
# defind WAIT std::cin.get()
// 这里可以不用放分号,如果放分号就会加入宏里面了
int main() {
WAIT;
//等效于std::cin.get(),属于纯文本替换
//但单纯做这种操作是很愚蠢的,除了自己以外别人读代码会特别痛苦
}
条件编译 #ifdef
使用条件编译宏 ` #ifdef,#ifndef,#endif,#if,#else 和 #elif ` 之类的指令可以进行条件编译,以便在源文件中包含或排除代码部分。
格式:
1
2
3
4
5
6
#ifndef HEADER_FILE
#define HEADER_FILE
// 你的代码...
#endif
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 如果该宏未定义,则定义宏
#ifndef MESSAGE_DEFINED
#define MESSAGE_DEFINED
#include <iostream>
void PrintMessage() {
std::cout << "Message Defined!" << std::endl;
}
#endif // MESSAGE_DEFINED
int main() {
PrintMessage(); // 只有当 MESSAGE_DEFINED 未定义时才会编译和执行
return 0;
}
宏函数
宏也可以定义宏函数,这种宏会在调用处展开并替换为指定的代码。
1
2
3
4
5
6
#define MIN(a, b) (((a) < (b)) ? (a) : (b))
// 宏是可以传递参数的,虽然参数也是复制粘贴替换上去的,并没有像函数那样讲究
int x = 10;
int y = 20;
int minimum = MIN(x, y); // 展开为 ((x) < (y)) ? (x) : (y)
请注意在使用宏时的注意事项,如宏函数可能会多次评估其参数,从而导致意想不到的效果。例如,在上述 MIN 宏函数的用法中,如果传递的参数有副作用,比如 MIN (
a++,b++),那么 a 和 b 会被加倍,因为它们在宏展开时各被评估了两次。因此,尽管宏在 C++ 中非常强大,但建议在可能的情况下使用类型安全的替代品,如模板和内联函数。
示例
用宏可以辅助调试
在 Debug 模式下会有很多日志的输出,但是在 Release 模式下就不需要日志的输出了。正常的方法可能会删掉好多的输出日志的语句或者函数,但是用宏可以直接取消掉这些语句
示例 1:利用宏中的 #if,#else,endif 来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
#defind PR_DEBUG 1 //可以在这里切换成0,作为一个开关
#if PR_DEBUG == 1 //如果PR_DEBUG为1
#defind LOG(x) std::cout << x << std::endl //则执行这个宏
#else //反之
#defind LOG(x) //这个宏什么也不定义,即是无意义
#endif //结束
int main() {
LOG("hello");
return 0;
}
// 如果在Debug(PR_DEBUG == 1)模式下,则会打印日志,如果在Release(PR_DEBUG == 0)模式,则在**预处理阶段就会把日志语句给删除掉**。
示例 2:利用 #if 0 和 #endif 删除一段宏 .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
#if 0 //从这里到最后的endif的宏都被无视掉了,某种意义上的删除
#defind PR_DEBUG 1
#if PR_DEBUG == 1
#defind LOG(x) std::cout << x << std::endl
#else
#defind LOG(x)
#endif
#endif //结束
int main() {
LOG("hello");
return 0;
}
检查平台定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 检查不同操作系统下进行不同实现
#if defined(WIN32) || defined(_WIN32)
#define PLATFORM "Windows"
#elif defined(__linux__)
#define PLATFORM "Linux"
#elif defined(__APPLE__)
#define PLATFORM "Apple"
#else
#define PLATFORM "Unknown"
#endif
#include <iostream>
int main() {
std::cout << "Platform: " << PLATFORM << std::endl;
// ... 程序其他代码
return 0;
}
C/C++ 编译
[[09.C和C++编译]]