05.MyBatis Plus
MyBatis Plus
MybatisPlus 简介
MyBatisPlus(简称 MP)是基于 MyBatis 框架基础上开发的增强型工具,旨在==简化开发、提高效率==。MyBatisPlus 的官网为:https://mp.baomidou.com/ / https://mybatis.plus/。
Mybatis Plus 和 Mybatis 关系: MP 旨在成为 MyBatis 的最好搭档,而不是替换 MyBatis,所以可以理解为 MP 是 MyBatis 的一套增强工具,它是在 MyBatis 的基础上进行开发的
Mybatis Plus 的特性:
- 无侵入:只做增强不做改变,不会对现有工程产生影响
- 强大的 CRUD 操作:内置通用 Mapper,少量配置即可实现单表 CRUD 操作
- 支持 Lambda:编写查询条件无需担心字段写错
- 支持主键自动生成
- 内置分页插件
- ……
Mybatis Plus 使用
入门案例
创建数据库及表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
--- 创建数据库
create database if not exists mybatisplus_db character set utf8;
use mybatisplus_db;
--- 创建表
CREATE TABLE user (
id bigint(20) primary key auto_increment,
name varchar(32) not null,
password varchar(32) not null,
age int(3) not null ,
tel varchar(32) not null
);
insert into user values(1,'Tom','tom',3,'18866668888');
insert into user values(2,'Jerry','jerry',4,'16688886666');
insert into user values(3,'Jock','123456',41,'18812345678');
insert into user values(4,'haha','it',15,'4006184000');
配置 Spring Boot 工程
- 依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<artifactId>mybatisplus_01_quickstart</artifactId>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>
</project>
- druid 数据源可以加也可以不加,SpringBoot 有内置的数据源,可以配置成使用 Druid 数据源
- 从 MP 的依赖关系可以看出,通过依赖传递已经将 MyBatis 与 MyBatis 整合 Spring 的 jar 包导入,我们不需要额外在添加 MyBatis 的相关 jar 包
添加 MP 的相关配置信息
resources 默认生成的是 properties 配置文件,可以将其替换成 yml 文件,并在文件中配置数据库连接的相关信息:application.yml
1
2
3
4
5
6
7
8
9
10
11
12
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC
username: root
password: zfs1314520
# 开启mp的日志,输出到控制台
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
说明: ==serverTimezone 是用来设置时区,UTC 是标准时区,和咱们的时间差 8 小时,所以可以将其修改为 Asia/Shanghai ==
代码
实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
package me.hacket.domain;
import lombok.Data;
//lombok
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}
Dao 类
1
2
3
4
5
6
7
8
9
package me.hacket.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import me.hacket.domain.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserDao extends BaseMapper<User> {
}
引导类
1
2
3
4
5
6
7
8
9
10
11
12
13
package me.hacket;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
// @MapperScan("me.hacket.dao")
public class MybatisPlus01QuickstartApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlus01QuickstartApplication.class, args);
}
}
说明:Dao 接口要想被容器扫描到,有两种解决方案:
- 方案一: 在 Dao 接口上添加
@Mapper注解,并且确保 Dao 处在引导类所在包或其子包中- 该方案的缺点是需要在每一 Dao 接口中添加注解
- 方案二: 在引导类上添加
@MapperScan注解,其属性为所要扫描的 Dao 所在包- 该方案的好处是只需要写一次,则指定包下的所有 Dao 接口都能被扫描到,
@Mapper就可以不写。
- 该方案的好处是只需要写一次,则指定包下的所有 Dao 接口都能被扫描到,
写测试类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
package me.hacket.test;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import me.hacket.dao.UserDao;
import me.hacket.domain.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class MyBatisPlus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setName("hacket");
user.setPassword("123456");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
@Test
void testSaveList() {
for (int i = 0; i < 20; i++) {
User user = new User();
user.setName("user-" + i);
user.setPassword("pwd-" + i);
user.setAge(10 + i);
user.setTel("4001231" + i);
userDao.insert(user);
}
}
@Test
void testDelete() {
userDao.deleteById(4);
}
@Test
void testUpdate() {
User user = new User();
user.setId(4L);
user.setName("dasheng");
user.setPassword("123456");
userDao.updateById(user);
}
@Test
void testGetById() {
User user = userDao.selectById(4L);
System.out.println(user);
}
@Test
void testGetAll() {
List<User> userList = userDao.selectList(null);
System.out.println(userList);
}
@Test
void testGetByPage() {
IPage<User> page = new Page<>(2, 3);
userDao.selectPage(page, null);
System.out.println("当前页码值:" + page.getCurrent());
System.out.println("每页显示数:" + page.getSize());
System.out.println("一共多少页:" + page.getPages());
System.out.println("一共多少条数据:" + page.getTotal());
System.out.println("数据:" + page.getRecords());
}
}
小结
- 跟之前整合 MyBatis 相比,我们不需要在 DAO 接口中编写方法和 SQL 语句了,只需要继承
BaseMapper接口即可。整体来说简化很多。
标准数据层开发
新增 insert
1
int insert (T t)
- t T: 泛型,新增用来保存新增数据
- int: 返回值,新增成功后返回 1,没有新增成功返回的是 0
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@SpringBootTest
public class MyBatisPlus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setName("hacket");
user.setPassword("123456");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}
删除
1
int deleteById (Serializable id)
- id Serializable:参数类型;参数类型为什么是一个序列化类?
- String 和 Number 是 Serializable 的子类,
- Number 又是 Float,Double,Integer 等类的父类,
- 能作为主键的数据类型都已经是 Serializable 的子类,
- MP 使用 Serializable 作为参数类型,就好比我们可以用 Object 接收任何数据类型一样。
- int: 返回值类型,数据删除成功返回 1,未删除数据返回 0。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testDelete() {
userDao.deleteById(1401856123725713409L);
}
}
修改
1
int updateById(T t);
- T: 泛型,需要修改的数据内容,注意因为是根据 ID 进行修改,所以传入的对象中需要有 ID 属性值
- int: 返回值,修改成功后返回 1,未修改数据返回 0
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testUpdate() {
User user = new User();
user.setId(1L);
user.setName("Tom888");
user.setPassword("tom888");
userDao.updateById(user);
}
}
说明: 修改的时候,只修改实体对象中有值的字段。
查询
根据 id
在进行根据 ID 查询之前,我们可以分析下根据 ID 查询的方法:
1
T selectById (Serializable id)
- Serializable:参数类型,主键 ID 的值
- T: 根据 ID 查询只会返回一条数据
示例:
1
2
3
4
5
6
7
8
9
10
11
12
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetById() {
User user = userDao.selectById(2L);
System.out.println(user);
}
}
查询所有
在进行查询所有之前,我们可以分析下查询所有的方法:
1
List<T> selectList(Wrapper<T> queryWrapper)
- Wrapper:用来构建条件查询的条件,目前我们没有可直接传为 Null
- List: 因为查询的是所有,所以返回的数据是一个集合
示例:
1
2
3
4
5
6
7
8
9
10
11
12
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
List<User> userList = userDao.selectList(null);
System.out.println(userList);
}
}
我们所调用的方法都是来自于 DAO 接口继承的 BaseMapper 类中。
分页
分页查询使用的方法是:
1
IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper)
- IPage: 用来构建分页查询条件
- Wrapper:用来构建条件查询的条件,目前我们没有可直接传为 Null
- IPage: 返回值,你会发现构建分页条件和方法的返回值都是 IPage
IPage 是一个接口,我们需要找到它的实现类来构建它,具体的实现类,可以进入到 IPage 类中按 Ctrl+H,会找到其有一个实现类为 Page。
步骤 1: 调用方法传入参数获取返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
//分页查询
@Test
void testSelectPage(){
//1 创建IPage分页对象,设置分页参数,1为当前页码,3为每页显示的记录数
IPage<User> page=new Page<>(1,3);
//2 执行分页查询
userDao.selectPage(page,null);
//3 获取分页结果
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("一共多少页:"+page.getPages());
System.out.println("一共多少条数据:"+page.getTotal());
System.out.println("数据:"+page.getRecords());
}
}
步骤 2: 设置分页拦截器
这个拦截器 MP 已经为我们提供好了,我们只需要将其配置成 Spring 管理的 bean 对象即可。
1
2
3
4
5
6
7
8
9
10
11
12
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//1 创建MybatisPlusInterceptor拦截器对象
MybatisPlusInterceptor mpInterceptor=new MybatisPlusInterceptor();
//2 添加分页拦截器
mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mpInterceptor;
}
}
如果想查看 MP 执行的 SQL 语句,可以修改 application.yml 配置文件,
1
2
3
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #打印SQL日志到控制台
DQL
增删改查四个操作中,查询是非常重要的也是非常复杂的操作,这块需要我们重点学习下,这节我们主要学习的内容有:
- 条件查询方式
- 查询投影
- 查询条件设定
- 字段映射与表名映射
条件查询方式
MyBatisPlus 将书写复杂的 SQL 查询条件进行了封装,使用编程的形式完成查询条件的组合。
在进行查询的时候,我们的入口是在 Wrapper 这个接口上,因为它是一个接口,所以我们需要去找它对应的实现类,关于实现类也有很多,说明我们有多种构建查询条件对象的方式,
QueryWrapper
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@SpringBootTest
public class MyBatisQueryTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
QueryWrapper<User> qw = new QueryWrapper<User>();
qw.lt("age", "18");
List<User> users = userDao.selectList(qw);
System.out.println("users=" + users);
}
}
- lt: 小于 (<) ,最终的 sql 语句为
1
SELECT id,name,password,age,tel FROM user WHERE (age < ?)
有个小问题就是在写条件的时候,容易出错,比如 age 写错,就会导致查询不成功
QueryWrapper 的基础上使用 lambda
1
2
3
4
5
6
7
@Test
void testGetAll1() {
QueryWrapper<User> qw = new QueryWrapper<User>();
qw.lambda().lt(User::getAge, 18); //添加条件
List<User> userList = userDao.selectList(qw);
System.out.println(userList);
}
User::getAget,为 lambda 表达式中的,类名:: 方法名,最终的 sql 语句为:
1
SELECT id,name,password,age,tel FROM user WHERE (age < ?)
注意: 构建 LambdaQueryWrapper 的时候泛型不能省。
此时我们再次编写条件的时候,就不会存在写错名称的情况,但是 qw 后面多了一层 lambda() 调用
LambdaQueryWrapper
1
2
3
4
5
6
7
@Test
void testGetAll2() {
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 18);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
解决了多了一层 lambda() 调用。
多条件构建
需求: 查询数据库表中,年龄在 10 岁到 30 岁之间的用户信息
1
2
3
4
5
6
7
8
9
@Test
void testGetAll3() {
// 需求:查询数据库表中,年龄在10岁到30岁之间的用户信息
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 30);
lqw.gt(User::getAge, 10);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
gt 表示大于,最终的 SQL 语句:
1
SELECT id,name,password,age,tel FROM user WHERE (age < ? AND age > ?)
构建多条件的时候,可以支持链式编程:
1
2
3
4
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 30).gt(User::getAge, 10);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
需求: 查询数据库表中,年龄小于 10 或年龄大于 30 的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 10).or().gt(User::getAge, 30);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}
or() 就相当于我们 sql 语句中的 or 关键字,不加默认是 and,最终的 sql 语句为:
1
SELECT id,name,password,age,tel FROM user WHERE (age < ? OR age > ?)
null 判定
需求: 查询数据库表中,根据输入年龄范围来查询符合条件的记录:
用户在输入值的时候,
如果只输入第一个框,说明要查询大于该年龄的用户
如果只输入第二个框,说明要查询小于该年龄的用户
如果两个框都输入了,说明要查询年龄在两个范围之间的用户
|  |
在 User 类添加一个 age2 属性;: 新建一个模型类,让其继承 User 类,并在其中添加 age2 属性,UserQuery 在拥有 User 属性后同时添加了 age2 属性。
1
2
3
4
@Data
public class UserQuery extends User {
private Integer age2;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Test
void testGetAll4() {
//模拟页面传递过来的查询数据
UserQuery uq = new UserQuery();
uq.setAge(10);
uq.setAge2(30);
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
if (null != uq.getAge2()) {
lqw.lt(User::getAge, uq.getAge2());
}
if (null != uq.getAge()) {
lqw.gt(User::getAge, uq.getAge());
}
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
上面的写法可以完成条件为非空的判断,但是问题很明显,如果条件多的话,每个条件都需要判断,代码量就比较大,来看 MP 给我们提供的简化方式:
1
2
3
4
5
6
7
8
9
10
11
12
@Test
void testGetAll4_1() {
//模拟页面传递过来的查询数据
UserQuery uq = new UserQuery();
uq.setAge(10);
uq.setAge2(30);
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<>();
lqw.lt(null != uq.getAge2(), User::getAge, uq.getAge2());
lqw.gt(null != uq.getAge(), User::getAge, uq.getAge());
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
lt 方法:
1
2
3
public Children lt(boolean condition, R column, Object val) {
return this.addCondition(condition, column, SqlKeyword.LT, val);
}
- condition 为 boolean 类型,返回 true,则添加条件,返回 false 则不添加条件
查询投影
查询指定字段
目前我们在查询数据的时候,什么都没有做默认就是查询表中所有字段的内容,我们所说的查询投影即不查询所有字段,只查询出指定内容的数据。
示例:
1
2
3
4
5
6
7
@Test
void testGetAll() {
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.select(User::getId, User::getName, User::getAge);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
1
LambdaQueryWrapper<T> select(SFunction<T, ?>... columns)
select(…) 方法用来设置查询的字段列,可以设置多个,最终的 sql 语句为:
1
SELECT id,name,age FROM user
如果使用的不是 lambda,就需要手动指定字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("id","name","age","tel");
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}
聚合查询
需求: 聚合函数查询,完成 count、max、min、avg、sum 的使用
count: 总记录数
max: 最大值
min: 最小值
avg: 平均值
sum: 求和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Test
void testGetAll2() {
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("count(*) as count");
//SELECT count(*) as count FROM user
//lqw.select("max(age) as maxAge");
//SELECT max(age) as maxAge FROM user
//lqw.select("min(age) as minAge");
//SELECT min(age) as minAge FROM user
//lqw.select("sum(age) as sumAge");
//SELECT sum(age) as sumAge FROM user
// lqw.select("avg(age) as avgAge");
//SELECT avg(age) as avgAge FROM user
List<Map<String, Object>> userList = userDao.selectMaps(lqw);
System.out.println(userList);
}
为了在做结果封装的时候能够更简单,我们将上面的聚合函数都起了个名称,方面后期来获取这些数据
分组查询
需求: 分组查询,完成 group by 的查询使用
1
2
3
4
5
6
7
8
@Test
void testGetAll3() {
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("count(*) as count, tel");
lqw.groupBy("tel");
List<Map<String, Object>> list = userDao.selectMaps(lqw);
System.out.println(list);
}
groupBy 为分组,最终的 sql 语句为:
1
SELECT count(*) as count, tel FROM user GROUP BY tel
注意:
聚合与分组查询,无法使用lambda表达式来完成- MP 只是对 MyBatis 的增强,如果 MP 实现不了,我们可以直接在 DAO 接口中使用 MyBatis 的方式实现
查询条件设定
前面我们只使用了 lt() 和 gt(),除了这两个方法外,MP 还封装了很多条件对应的方法,这一节我们重点把 MP 提供的查询条件方法进行学习下。
MP 的查询条件有很多:
- 范围匹配(> 、 = 、between)
- 模糊匹配(like)
- 空判定(null)
- 包含性匹配(in)
- 分组(group)
- 排序(order)
- ……
等值查询
需求: 根据用户名和密码查询用户信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.eq(User::getName, "Jerry").eq(User::getPassword, "jerry");
User loginUser = userDao.selectOne(lqw);
System.out.println(loginUser);
}
}
- eq 是 =,最终 sql 语句:
1
SELECT id,name,password,age,tel FROM user WHERE (name = ? AND password = ?)
- selectList:查询结果为多个或者单个
- selectOne: 查询结果为单个
范围查询
需求: 对年龄进行范围查询,使用 lt()、le()、gt()、ge()、between() 进行范围查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.between(User::getAge, 10, 30);
//SELECT id,name,password,age,tel FROM user WHERE (age BETWEEN ? AND ?)
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}
- gt(): 大于 (>)
- ge(): 大于等于 (>=)
- lt(): 小于 (<)
- lte(): 小于等于 (<=)
- between(): between ? and ?
模糊查询
需求: 查询表中 name 属性的值以 J 开头的用户信息,使用 like 进行模糊查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.likeLeft(User::getName, "J");
//SELECT id,name,password,age,tel FROM user WHERE (name LIKE ?)
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}
like(): 前后加百分号,如 %J%likeLeft(): 前面加百分号,如 %JlikeRight(): 后面加百分号,如 J%
排序查询
需求: 查询所有数据,然后按照 id 降序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lwq = new LambdaQueryWrapper<>();
/**
* condition :条件,返回boolean,当condition为true,进行排序,如果为false,则不排序
* isAsc:是否为升序,true为升序,false为降序
* columns:需要操作的列
*/
lwq.orderBy(true,false, User::getId);
userDao.selectList(lw
}
}
除了上面演示的这种实现方式,还有很多其他的排序方法可以被调用,如图:

- orderBy 排序
- condition: 条件,true 则添加排序,false 则不添加排序
- isAsc: 是否为升序,true 升序,false 降序
- columns: 排序字段,可以有多个
- orderByAsc/Desc(单个 column): 按照指定字段进行升序/降序
- orderByAsc/Desc(多个 column): 按照多个字段进行升序/降序
- orderByAsc/Desc
- condition: 条件,true 添加排序,false 不添加排序
- 多个 columns:按照多个字段进行排序
除了上面介绍的这几种查询条件构建方法以外还会有很多其他的方法,比如 isNull,isNotNull,in,notIn 等等方法可供选择,具体参考官方文档的条件构造器来学习使用,具体的网址为:
https://mp.baomidou.com/guide/wrapper.html#abstractwrapper
字段映射与表名映射
能从表中查询出数据,并将数据封装到模型类中,这整个过程涉及到一张表和一个模型类:

之所以数据能够成功的从表中获取并封装到模型对象中,原因是表的字段列名和模型类的属性名一样。
问题 1: 表字段与代码字段设计不同步
当表的列名和模型类的属性名发生不一致,就会导致数据封装不到模型对象,这个时候就需要其中一方做出修改,那如果前提是两边都不能改又该如何解决?
MP 给我们提供了一个注解 @TableField,使用该注解可以实现模型类属性名和表的列名之间的映射关系

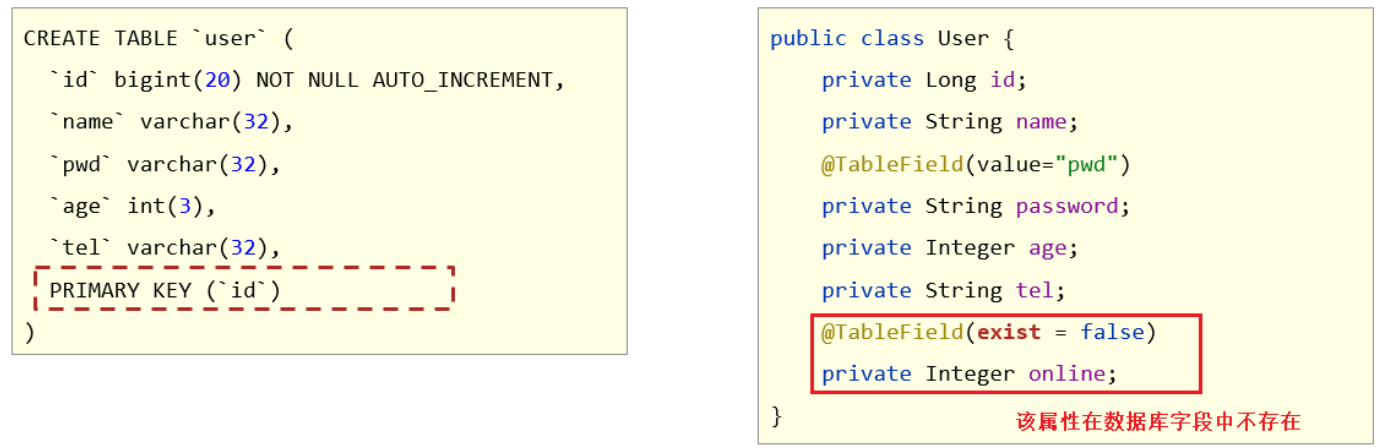
问题 2:代码中添加了数据库中未定义的属性
当模型类中多了一个数据库表不存在的字段,就会导致生成的 sql 语句中在 select 的时候查询了数据库不存在的字段,程序运行就会报错,错误信息为:
==Unknown column ‘ 多出来的字段名称 ‘ in ‘field list’==
具体的解决方案用到的还是 @TableField 注解,它有一个属性叫 exist,设置该字段是否在数据库表中存在,如果设置为 false 则不存在,生成 sql 语句查询的时候,就不会再查询该字段了。
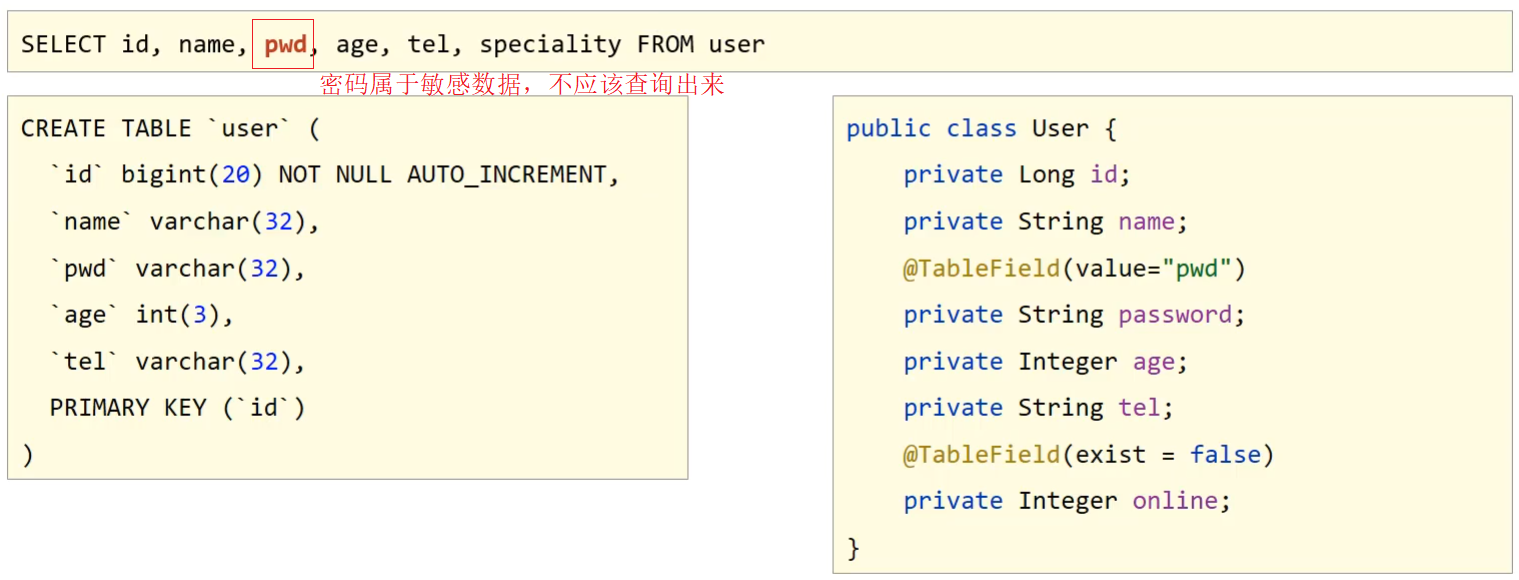
问题 3:采用默认查询开放了更多的字段查看权限
查询表中所有的列的数据,就可能把一些敏感数据查询到返回给前端,这个时候我们就需要限制哪些字段默认不要进行查询。解决方案是 @TableField 注解的一个属性叫 select,该属性设置默认是否需要查询该字段的值,true(默认值) 表示默认查询该字段,false 表示默认不查询该字段。
涉及到的注解
@TableField
| 名称 | @TableField |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类属性定义上方 |
| 作用 | 设置当前属性对应的数据库表中的字段关系 |
| 相关属性 | value(默认):设置数据库表字段名称 exist: 设置属性在数据库表字段中是否存在,默认为 true,此属性不能与 value 合并使用 select: 设置属性是否参与查询,此属性与 select() 映射配置不冲突 |
@TableName
| 名称 | @TableName |
|---|---|
| 类型 | ==类注解== |
| 位置 | 模型类定义上方 |
| 作用 | 设置当前类对应于数据库表关系 |
| 相关属性 | value(默认):设置数据库表名称 |
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Data
@TableName("tbl_user") // 修改数据库表user为tbl_user,直接查询会报错,原因是MP默认情况下会使用模型类的类名首字母小写当表名使用。
public class User {
private Long id;
private String name;
// 字段password修改成pwd,直接查询会报错,原因是MP默认情况下会使用模型类的属性名当做表的列名使用
@TableField(value="pwd", select=false) // 查询时将pwd隐藏
private String password;
private Integer age;
private String tel;
// 添加一个数据库表不存在的字段,直接查询会报错,原因是MP默认情况下会查询模型类的所有属性对应的数据库表的列,而online不存在
@TableField(exist=false)
private Integer online;
}
DML
增删改
id 生成策略控制
前面我们在新增的时候留了一个问题,就是新增成功后,主键 ID 是一个很长串的内容,我们更想要的是按照数据库表字段进行自增长,在解决这个问题之前,我们先来分析下 ID 该如何选择:
- 不同的表应用不同的 id 生成策略
- 日志:自增(1,2,3,4,……)
- 购物订单:特殊规则(FQ23948AK3843)
- 外卖单:关联地区日期等信息(10 04 20200314 34 91)
- 关系表:可省略 id
- ……
不同的业务采用的 ID 生成方式应该是不一样的,那么在 MP 中都提供了哪些主键生成策略,以及我们该如何进行选择?
在这里我们又需要用到 MP 的一个注解叫 @TableId
| 名称 | @TableId |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类中用于表示主键的属性定义上方 |
| 作用 | 设置当前类中主键属性的生成策略 |
| 相关属性 | value(默认):设置数据库表主键名称 type: 设置主键属性的生成策略,值查照 IdType 的枚举值 |
AUTO 策略
1
2
3
4
5
6
7
8
9
10
11
12
13
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
@TableField(value="pwd",select=false)
private String password;
private Integer age;
private String tel;
@TableField(exist=false)
private Integer online;
}
AUTO 的作用是==使用数据库 ID 自增==,在使用该策略的时候一定要确保对应的数据库表设置了 ID 主键自增,否则无效。
除了 AUTO 这个策略以外,还有如下几种生成策略:
- NONE: 不设置 id 生成策略
- INPUT: 用户手工输入 id
- ASSIGN_ID: 雪花算法生成 id(可兼容数值型与字符串型)
- ASSIGN_UUID: 以 UUID 生成算法作为 id 生成策略
- 其他的几个策略均已过时,都将被 ASSIGN_ID 和 ASSIGN_UUID 代替掉。
分布式 ID 是什么?
- 当数据量足够大的时候,一台数据库服务器存储不下,这个时候就需要多台数据库服务器进行存储
- 比如订单表就有可能被存储在不同的服务器上
- 如果用数据库表的自增主键,因为在两台服务器上所以会出现冲突
- 这个时候就需要一个全局唯一 ID,这个 ID 就是分布式 ID。
INPUT 策略
1
2
3
4
5
6
7
8
9
10
11
12
13
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
@TableField(value="pwd",select=false)
private String password;
private Integer age;
private String tel;
@TableField(exist=false)
private Integer online;
}
注意: 这种 ID 生成策略,需要将表的自增策略删除掉 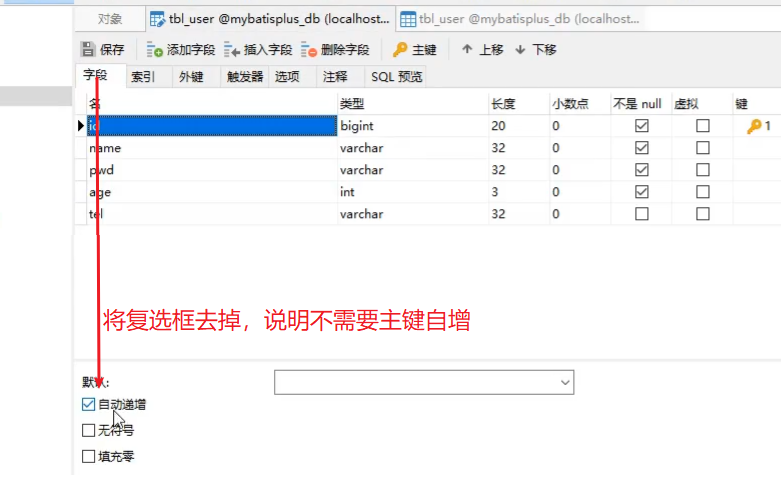
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave(){
User user = new User();
//设置主键ID的值
user.setId(666L);
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}
ASSIGN_ID 策略
1
2
3
4
5
6
7
8
9
10
11
12
13
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String name;
@TableField(value="pwd",select=false)
private String password;
private Integer age;
private String tel;
@TableField(exist=false)
private Integer online;
}
测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave(){
User user = new User();
user.setName("xxx");
user.setPassword("yyy");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}
注意: 这种生成策略,不需要手动设置 ID,如果手动设置 ID,则会使用自己设置的值。 生成的 ID 就是一个 Long 类型的数据。
ASSIGN_UUID 策略
使用 uuid 需要注意的是,主键的类型不能是 Long,而应该改成 String 类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.ASSIGN_UUID)
private String id;
private String name;
@TableField(value="pwd",select=false)
private String password;
private Integer age;
private String tel;
@TableField(exist=false)
private Integer online;
}
修改表的主键类型
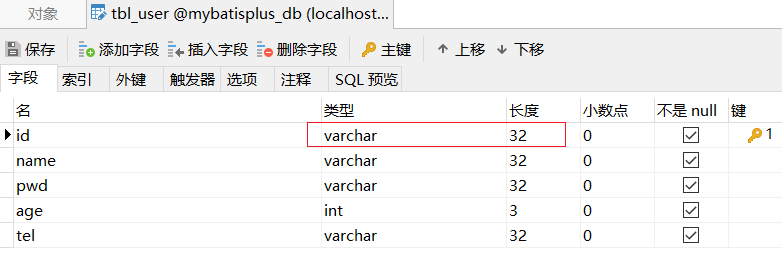
主键类型设置为 varchar,长度要大于 32,因为 UUID 生成的主键为 32 位,如果长度小的话就会导致插入失败。
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave(){
User user = new User();
user.setName("xxx");
user.setPassword("yyy");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}
雪花算法
雪花算法 (SnowFlake), 是 Twitter 官方给出的算法实现是用 Scala 写的。其生成的结果是一个 64bit 大小整数,它的结构如下图:
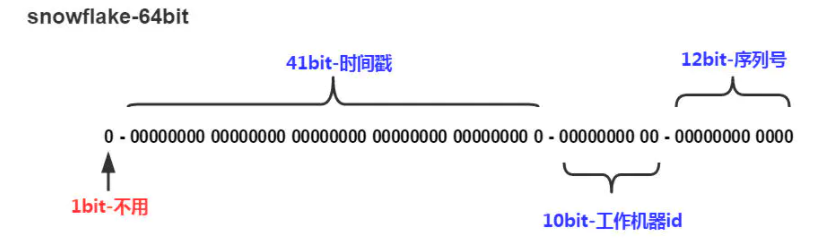
- 1bit,不用,因为二进制中最高位是符号位,1 表示负数,0 表示正数。生成的 id 一般都是用整数,所以最高位固定为 0。
- 41bit- 时间戳,用来记录时间戳,毫秒级
- 10bit- 工作机器 id,用来记录工作机器 id,其中高位 5bit 是数据中心 ID 其取值范围 0-31,低位 5bit 是工作节点 ID 其取值范围 0-31,两个组合起来最多可以容纳 1024 个节点
- 序列号占用 12bit,每个节点每毫秒 0 开始不断累加,最多可以累加到 4095,一共可以产生 4096 个 ID
ID 生成策略对比
介绍了这些主键 ID 的生成策略,我们以后该用哪个呢?
- NONE: 不设置 id 生成策略,MP 不自动生成,约等于 INPUT,所以这两种方式都需要用户手动设置,但是手动设置第一个问题是容易出现相同的 ID 造成主键冲突,为了保证主键不冲突就需要做很多判定,实现起来比较复杂
- AUTO: 数据库 ID 自增,这种策略适合在数据库服务器只有 1 台的情况下使用,不可作为分布式 ID 使用
- ASSIGN_UUID: 可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是 32 位的字符串,长度过长占用空间而且还不能排序,查询性能也慢
- ASSIGN_ID: 可以在分布式的情况下使用,生成的是 Long 类型的数字,可以排序性能也高,但是生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键
- 综上所述,每一种主键策略都有自己的优缺点,根据自己项目业务的实际情况来选择使用才是最明智的选择。
简化配置
模型类主键策略设置
对于主键 ID 的策略已经介绍完,但是如果要在项目中的每一个模型类上都需要使用相同的生成策略,如:

稍微有点繁琐,我们能不能在某一处进行配置,就能让所有的模型类都可以使用该主键 ID 策略呢?
1
2
3
4
mybatis-plus:
global-config:
db-config:
id-type: assign_id
配置完成后,每个模型类的主键 ID 策略都将成为 assign_id.
数据库表与模型类的映射关系
MP 会默认将模型类的类名名首字母小写作为表名使用,假如数据库表的名称都以 tbl_ 开头,那么我们就需要将所有的模型类上添加 @TableName,如:

配置起来还是比较繁琐,简化方式为在配置文件中配置如下内容:
1
2
3
4
mybatis-plus:
global-config:
db-config:
table-prefix: tbl_
设置表的前缀内容,这样 MP 就会拿 tbl_ 加上模型类的首字母小写,就刚好组装成数据库的表名。
多记录操作
批量删除
API:
1
2
// 删除(根据ID 批量删除),参数是一个集合,可以存放多个id值。
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testDelete(){
//删除指定多条数据
List<Long> list = new ArrayList<>();
list.add(1402551342481838081L);
list.add(1402553134049501186L);
list.add(1402553619611430913L);
userDao.deleteBatchIds(list);
}
}
批量查询
API:
1
2
// 查询(根据ID 批量查询),参数是一个集合,可以存放多个id值。
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetByIds(){
//查询指定多条数据
List<Long> list = new ArrayList<>();
list.add(1L);
list.add(3L);
list.add(4L);
userDao.selectBatchIds(list);
}
}
逻辑删除
对于删除操作业务问题来说有:
- 物理删除: 业务数据从数据库中丢弃,执行的是 delete 操作
- 逻辑删除: 为数据设置是否可用状态字段,删除时设置状态字段为不可用状态,数据保留在数据库中,执行的是 update 操作
示例:
标识新增的字段为逻辑删除字段,使用 @TableLogic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Data
//@TableName("tbl_user") 可以不写是因为配置了全局配置
public class User {
@TableId(type = IdType.ASSIGN_UUID)
private String id;
private String name;
@TableField(value="pwd",select=false)
private String password;
private Integer age;
private String tel;
@TableField(exist=false)
private Integer online;
@TableLogic(value="0",delval="1")
//value为正常数据的值,delval为删除数据的值
private Integer deleted;
}
删除方法
1
2
3
4
5
6
7
8
9
10
11
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testDelete(){
userDao.deleteById(1L);
}
}
从测试结果来看,逻辑删除最后走的是 update 操作,会将指定的字段修改成删除状态对应的值。
逻辑删除,对查询有没有影响呢? MP 的逻辑删除会将所有的查询都添加一个未被删除的条件,也就是已经被删除的数据是不应该被查询出来的。
如果还是想把已经删除的数据都查询出来该如何实现呢?
1
2
3
4
5
6
@Mapper
public interface UserDao extends BaseMapper<User> {
//查询所有数据包含已经被删除的数据
@Select("select * from tbl_user")
public List<User> selectAll();
}
如果每个表都要有逻辑删除,那么就需要在每个模型类的属性上添加 @TableLogic 注解,如何优化?
在配置文件中添加全局配置,如下:
1
2
3
4
5
6
7
8
9
mybatis-plus:
global-config:
db-config:
# 逻辑删除字段名
logic-delete-field: deleted
# 逻辑删除字面值:未删除为0
logic-not-delete-value: 0
# 逻辑删除字面值:删除为1
logic-delete-value: 1
逻辑删除的本质为: 逻辑删除的本质其实是修改操作。如果加了逻辑删除字段,查询数据时也会自动带上逻辑删除字段。 执行的 SQL 语句为:
1
UPDATE tbl_user SET deleted=1 where id = ? AND deleted=0
@TableLogic
| 名称 | @TableLogic |
|---|---|
| 类型 | ==属性注解== |
| 位置 | 模型类中用于表示删除字段的属性定义上方 |
| 作用 | 标识该字段为进行逻辑删除的字段 |
| 相关属性 | value:逻辑未删除值 delval: 逻辑删除值 |
乐观锁
乐观锁主要解决的问题是当要更新一条记录的时候,希望这条记录没有被别人更新。
参考官方文档来实现:
https://mp.baomidou.com/guide/interceptor-optimistic-locker.html#optimisticlockerinnerinterceptor
Lombok
Lombok,一个 Java 类库,提供了一组注解,简化 POJO 实体类开发。
1
2
3
4
5
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<!--<version>1.18.12</version>-->
</dependency>
注意: 版本可以不用写,因为 SpringBoot 中已经管理了 lombok 的版本。
Lombok 常见的注解有:
@Setter: 为模型类的属性提供 setter 方法@Getter: 为模型类的属性提供 getter 方法@ToString: 为模型类的属性提供 toString 方法@EqualsAndHashCode: 为模型类的属性提供 equals 和 hashcode 方法- ==
@Data: 是个组合注解,包含上面的注解的功能== - ==@NoArgsConstructor: 提供一个无参构造函数==
- ==@AllArgsConstructor: 提供一个包含所有参数的构造函数==
Lombok 的注解还有很多,上面标红的三个是比较常用的:
1
2
3
4
5
6
7
8
9
10
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}