ResultMap 结果集映射
查询为 null 的问题
问题分析
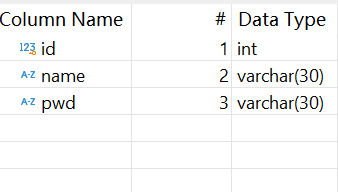
数据库库表 user 的字段
|  |
实体类 bean:
1
2
3
4
5
6
7
8
9
10
| public class User {
private int id; //id
private String name; //姓名
private String password; //密码和数据库不一样!
//构造
//set/get
//toString()
}
|
问题:数据库中表中字段名和实体 bean 的字段名不一致
查询接口:
1
2
| //根据id查询用户
User selectUserById(int id);
|
Mapper.xml 查询语句:
1
2
3
| <select id="selectUserById" resultType="user">
select * from user where id = #{id}
</select>
|
测试代码:
1
2
3
4
5
6
7
8
| @Test
public void testSelectUserById() {
SqlSession session = MybatisUtils.getSession(); //获取SqlSession连接
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
session.close();
}
|
结果: 查询出来发现 password 为空
分析:
select * from user where id = #{id} 可以看做 select id,name,pwd from user where id = #- mybatis 会根据这些查询的列名 (会将列名转化为小写,数据库不区分大小写) , 去对应的实体类中查找相应列名的 set 方法设值 , 由于找不到
setPwd() , 所以 password 返回 null ; 【自动映射】
解决方案
提供和数据库字段一致的构造函数
构造函数的字段和数据库字段顺序一致,否则对应不上
1
2
3
4
5
6
7
8
9
10
11
12
| public class User {
private int id; //id
private String name; //姓名
private String password; //密码
public User(int id, String name, String password) {
this.id = id;
this.name = name;
this.password = password;
}
}
|
为列名指定别名 , 别名和 java 实体类的属性名一致
1
2
3
4
5
6
7
8
| <!-- <select id="selectUserById" resultType="me.hacket.model.User">-->
<!-- select *-->
<!-- from user-->
<!-- where id = #{id}-->
<!-- </select>-->
<select id="selectUserById" resultType="me.hacket.model.User">
select id , name , pwd as password from user where id = #{id}
</select>
|
使用结果集映射 ->ResultMap (推荐)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="me.hacket.mapper.UserMapper">
<!-- <select id="selectUserById" resultType="me.hacket.model.User">-->
<!-- select *-->
<!-- from user-->
<!-- where id = #{id}-->
<!-- </select>-->
<!-- 解决方式1: bean和数据库字段不一致问题-->
<!-- <select id="selectUserById" resultType="me.hacket.model.User">-->
<!-- select id , name , pwd as password from user where id = #{id}-->
<!-- </select>-->
<!-- 解决方式2: resultMap-->
<resultMap id="UserMap" type="me.hacket.model.User">
<!-- id为主键 -->
<id column="id" property="id"/>
<!-- column是数据库表的列名 , property是对应实体类的属性名 -->
<result column="name" property="name"/>
<result column="pwd" property="password"/>
</resultMap>
<select id="selectUserById" resultMap="UserMap">
select id, name, pwd
from user
where id = #{id}
</select>
</mapper>
|
ResultMap
自动映射
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来。- 实际上,在为一些比如连接的复杂语句编写映射代码的时候,一份
resultMap 能够代替实现同等功能的长达数千行的代码。 - ResultMap 的设计思想是,对于简单的语句根本不需要配置显式的结果映射,而对于复杂一点的语句只需要描述它们的关系就行了。
简单映射语句的示例:但并没有显式指定 resultMap。比如:
1
2
3
4
5
| <select id="selectUserById" resultType="map">
select id , name , pwd
from user
where id = #{id}
</select>
|
上述语句只是简单地将所有的列映射到 HashMap 的键上,这由 resultType 属性指定。虽然在大部分情况下都够用,但是 HashMap 不是一个很好的模型。你的程序更可能会使用 JavaBean 或 POJO(Plain Old Java Objects,普通老式 Java 对象)作为模型。
ResultMap 最优秀的地方在于,虽然你已经对它相当了解了,但是根本就不需要显式地用到他们。
手动映射
1
2
3
4
5
6
7
8
9
10
11
12
| <resultMap id="UserMap" type="me.hacket.model.User">
<!-- id为主键 -->
<id column="id" property="id"/>
<!-- column是数据库表的列名 , property是对应实体类的属性名 -->
<result column="name" property="name"/>
<result column="pwd" property="password"/>
</resultMap>
<select id="selectUserById" resultMap="UserMap">
select id, name, pwd
from user
where id = #{id}
</select>
|
数据库中,存在一对多,多对一的情况,我们之后会使用到一些高级的结果集映射,association,collection 这些。
Ref
| [mybatis – MyBatis 3 | XML 映射器](https://mybatis.org/mybatis-3/zh_CN/sqlmap-xml.html#%E7%BB%93%E6%9E%9C%E6%98%A0%E5%B0%84) |
分页
limit 实现分页
limit 语法
1
2
3
4
5
6
7
8
9
10
11
| --语法
SELECT * FROM table LIMIT stratIndex,pageSize
SELECT * FROM table LIMIT 5,10; -- 检索记录行 6-15
--为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
SELECT * FROM table LIMIT 95,-1; -- 检索记录行 96-last.
--如果只给定一个参数,它表示返回最大的记录行数目:
SELECT * FROM table LIMIT 5; --检索前 5 个记录行
--#换句话说,LIMIT n 等价于 LIMIT 0,n。
|
limit 分页步骤
1
2
3
| <select id="selectUser" parameterType="map" resultType="user">
select * from user limit #{params.startIndex},#{params.pageSize}
</select>
|
1
2
| // 选择全部用户实现分页
List<User> selectUser(@Params("params") Map<String,Integer> map);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 推断:起始位置 = (当前页面 - 1 ) * 页面大小
// 分页查询 , 两个参数startIndex , pageSize
@Test
public void testSelectUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int currentPage = 1; //第几页
int pageSize = 2; //每页显示几个
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("startIndex",(currentPage-1)*pageSize);
map.put("pageSize",pageSize);
List<User> users = mapper.selectUser(map);
for (User user: users){
System.out.println(user);
}
session.close();
}
|
RowBounds 分页
除了使用 Limit 在 SQL 层面实现分页,也可以使用 RowBounds 在 Java 代码层面实现分页,当然此种方式作为了解即可
PageHelper
了解即可,可以自己尝试使用
官方文档:https://pagehelper.github.io/
数据源 dataSource
Druid
N 对 N
多对一
多对一的理解:
- 多个学生对应一个老师
- 如果对于学生这边,就是一个多对一的现象,即从学生这边关联一个老师
数据库设计:
CREATE TABLE `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO teacher(`id`, `name`) VALUES (1, '秦老师');
CREATE TABLE `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teacher` (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('1', '小明', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('2', '小红', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('3', '小张', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('4', '小李', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('5', '小王', '1');
按查询嵌套处理
1
2
3
4
5
6
7
8
9
10
11
12
| @Data //GET,SET,ToString,有参,无参构造
public class Teacher {
private int id;
private String name;
}
@Data
public class Student {
private int id;
private String name;
//多个学生可以是同一个老师,即多对一
private Teacher teacher;
}
|
1
2
3
4
5
6
| public interface StudentMapper {
// 获取所有学生及对应老师的信息
public List<Student> getStudents();
}
public interface TeacherMapper {
}
|
- 编写 Mapper 接口对应的 mapper.xml 配置文件 【两个】
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| <!--studentMapper.xml-->
<mapper namespace="me.hacket.mapper.StudentMapper">
<!--
需求:获取所有学生及对应老师的信息
思路:
1. 获取所有学生的信息
2. 根据获取的学生信息的老师ID->获取该老师的信息
3. 思考问题,这样学生的结果集中应该包含老师,该如何处理呢,数据库中我们一般使用关联查询?
1. 做一个结果集映射:StudentTeacher
2. StudentTeacher结果集的类型为 Student
3. 学生中老师的属性为teacher,对应数据库中为tid。
多个 [1,...)学生关联一个老师=> 一对一,一对多
4. 查看官网找到:association – 一个复杂类型的关联;使用它来处理关联查询
-->
<select id="getStudents" resultMap="StudentResultMap">
select *
from student
</select>
<resultMap id="StudentResultMap" type="Student">
<!--association关联属性 property属性名 javaType属性类型 column在多的一方的表中的列名-->
<!-- <association property="teacher" column="{id=tid}" javaType="Teacher" select="getTeacher"/>-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"/>
</resultMap>
<!--
这里传递过来的id,只有一个属性的时候,下面可以写任何值
association中column多参数配置:
column="{key=value,key=value}"
其实就是键值对的形式,key是传给下个sql的取值名称,value是片段一中sql查询的字段名。
-->
<select id="getTeacher" resultType="Teacher">
select *
from teacher
where id = #{id}
</select>
</mapper>
|
1
2
3
4
5
6
7
8
9
10
11
| @Test
public void getTeacherFromStudents() {
SqlSession session = MybatisUtils.getSession();
StudentMapper mapper = session.getMapper(StudentMapper.class);
List<Student> students = mapper.getStudents();
for (Student student : students) {
System.out.println(
"学生名:" + student.getName()
+ "\t老师:" + student.getTeacher().getName());
}
}
|
按结果嵌套处理
1
2
| //获取所有学生及对应老师的信息
public List<Student> getStudents2();
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| <!--
按查询结果嵌套处理
思路:
1. 直接查询出结果,进行结果集的映射
-->
<select id="getStudents2" resultMap="StudentTeacher2" >
select s.id sid, s.name sname , t.name tname
from student s,teacher t
where s.tid = t.id
</select>
<resultMap id="StudentTeacher2" type="Student">
<id property="id" column="sid"/>
<result property="name" column="sname"/>
<!--关联对象property 关联对象在Student实体类中的属性-->
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
|
1
2
3
4
| <mappers>
<mapper resource="mapper/studentMapper.xml"/>
<mapper resource="mapper/teacherMapper.xml"/>
</mappers>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Test
public void testGetStudents2(){
SqlSession session = MybatisUtils.getSession();
StudentMapper mapper = session.getMapper(StudentMapper.class);
List<Student> students = mapper.getStudents2();
for (Student student : students){
System.out.println(
"学生名:"+ student.getName()
+"\t老师:"+student.getTeacher().getName());
}
}
|
小结
- 按照查询进行嵌套处理就像 SQL 中的子查询
- 按照结果进行嵌套处理就像 SQL 中的联表查询
一对多
动态 SQL
什么是动态 SQL?
动态 SQL 指的是根据不同的查询条件 , 生成不同的 Sql 语句。
1
2
3
4
5
6
7
8
9
10
11
| 官网描述:
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
虽然在以前使用动态 SQL 并非一件易事,但正是 MyBatis 提供了可以被用在任意 SQL 映射语句中的强大的动态 SQL 语言得以改进这种情形。
动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多元素需要花时间了解。MyBatis 3 大大精简了元素种类,现在只需学习原来一半的元素便可。MyBatis 采用功能强大的基于 OGNL 的表达式来淘汰其它大部分元素。
-------------------------------
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
-------------------------------
|
我们之前写的 SQL 语句都比较简单,如果有比较复杂的业务,我们需要写复杂的 SQL 语句,往往需要拼接,而拼接 SQL ,稍微不注意,由于引号,空格等缺失可能都会导致错误。
那么怎么去解决这个问题呢?这就要使用 MyBatis 动态 SQL,通过 if, choose, when, otherwise, trim, where, set, foreach 等标签,可组合成非常灵活的 SQL 语句,从而在提高 SQL 语句的准确性的同时,也大大提高了开发人员的效率。
准备数据
1
2
3
4
5
6
7
| CREATE TABLE `blog` (
`id` varchar(50) NOT NULL COMMENT '博客id',
`title` varchar(100) NOT NULL COMMENT '博客标题',
`author` varchar(30) NOT NULL COMMENT '博客作者',
`create_time` datetime NOT NULL COMMENT '创建时间',
`views` int(30) NOT NULL COMMENT '浏览量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
1
2
3
4
5
| public class IDUtil {
public static String genId() {
return UUID.randomUUID().toString().replaceAll("-", "");
}
}
|
- JavaBean (需要实现 setter/getter)
1
2
3
4
5
6
7
8
| public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
//set,get....
}
|
1
2
3
4
| public interface BlogMapper {
// 新增一个博客
int addBlog(Blog blog);
}
|
1
2
3
4
5
6
7
8
9
10
11
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="me.hacket.mapper.BlogMapper">
<insert id="addBlog" parameterType="me.hacket.model.Blog">
insert into blog (id, title, author, create_time, views)
values (#{id}, #{title}, #{author}, #{createTime}, #{views});
</insert>
</mapper>
|
1
2
3
4
5
6
7
8
9
10
11
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
// ...
<mappers>
<mapper resource="mapper/blogMapper.xml"/>
</mappers>
</configuration>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Test
public void addInitBlog() {
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = new Blog();
blog.setId(IDUtil.genId());
blog.setTitle("Mybatis如此简单");
blog.setAuthor("hacket");
blog.setCreateTime(new Date());
blog.setViews(12345);
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Java如此简单");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Spring如此简单");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("微服务如此简单");
mapper.addBlog(blog);
session.commit();
session.close();
}
|
if
需求: 根据作者名字和博客名字来查询博客;如果作者名字为空,那么只根据博客名字查询,反之,则根据作者名来查询
1
| List<Blog> queryBlogIf(Map map);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="me.hacket.mapper.BlogMapper">
<select id="queryBlogIf" parameterType="Map" resultType="me.hacket.model.Blog">
select * from blog where
<if test="title!=null">
title = #{title}
</if>
<if test="author!=null">
and author = #{author}
</if>
</select>
</mapper>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @Test
public void testQueryBlogIf() {
try (SqlSession session = MybatisUtils.getSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Map<String, Object> map = new HashMap<>();
map.put("title", "Java如此简单");
map.put("author", "hacket");
List<Blog> blogs = mapper.queryBlogIf(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
session.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
|
这样写我们可以看到,如果 author 等于 null,那么查询语句为 select * from user where title=#{title},但是如果 title 为空呢?那么查询语句为 select * from user where and author=#{author},这是错误的 SQL 语句
where
1
2
3
4
5
6
7
8
9
10
11
| <select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</where>
</select>
|
这个 “where” 标签会知道如果它包含的标签中有返回值的话,它就插入一个 ‘where’。此外,如果标签返回的内容是以 AND 或 OR 开头的,则它会剔除掉。
set
1
| int updateBlog(Map<String, String> map);
|
<!--注意set是用的逗号隔开-->
<update id="updateBlog" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author}
</if>
</set>
where id = #{id};
</update>~
SQL 语句:update blog SET title = ?, author = ? Where id = ?;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Test
public void testUpdateBlog(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, String> map = new HashMap<String, String>();
map.put("title","动态SQL");
map.put("author","秦疆");
map.put("id","f342070ea2964a8188e8cdb8379be5c0");
mapper.updateBlog(map);
session.commit();
session.close();
}
|
choose
有时候,我们不想用到所有的查询条件,只想选择其中的一个,查询条件有一个满足即可,使用 choose 标签可以解决此类问题,类似于 Java 的 switch 语句。
1
| List<Blog> queryBlogChoose(Map<String, Object> map);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <select id="queryBlogChoose" parameterType="map" resultType="me.hacket.model.Blog">
select * from blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>
</select>
|
title 为空:select * from blog WHERE author = ? title 不为空:select * from blog WHERE title = ?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void testQueryBlogChoose(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<>();
// map.put("title","Java如此简单");
map.put("author","hacket");
map.put("views",9999);
List<Blog> blogs = mapper.queryBlogChoose(map);
System.out.println(blogs);
session.close();
}
|
SQL 片段
有时候可能某个 sql 语句我们用的特别多,为了增加代码的重用性,简化代码,我们需要将这些代码抽取出来,然后使用时直接调用。
提取 SQL 片段:
1
2
3
4
5
6
7
8
| <sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
|
引用 SQL 片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <select id="queryBlogIf" parameterType="Map" resultType="me.hacket.model.Blog">
select * from blog where
<if test="title!=null">
title = #{title}
</if>
<if test="author!=null">
and author = #{author}
</if>
</select>
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<!-- 引用 sql 片段,如果refid 指定的不在本文件中,那么需要在前面加上 namespace -->
<include refid="if-title-author"></include>
<!-- 在这里还可以引用其他的 sql 片段 -->
</where>
</select>
|
注意:
- 最好基于单表来定义 sql 片段,提高片段的可重用性
- 在 sql 片段中不要包括 where
foreach
需求:我们需要查询 blog 表中 id 分别为 x, x, x 的博客信息
1
| List<Blog> queryBlogForeach(Map<String, Object> map);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <!--foreach-->
<select id="queryBlogForeach" parameterType="map" resultType="blog">
/* select * from blog WHERE ( id=? or id=? or id=? ) */
select * from blog
<where>
<!--
collection:指定输入对象中的集合属性
item:每次遍历生成的对象
open:开始遍历时的拼接字符串
close:结束时拼接的字符串
separator:遍历对象之间需要拼接的字符串
select * from blog where 1=1 and (id=1 or id=2 or id=3)
-->
<foreach collection="ids" item="id" open="and (" close=")" separator="or">
id=#{id}
</foreach>
</where>
</select>
|
生成 select * from blog WHERE ( id=? Or id=? Or id=? );
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Test
public void testQueryBlogForeach() {
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<>();
List<String> ids = new ArrayList<>();
ids.add("ca675b677c214c95989ef4ee079e0df0");
ids.add("26a2aa404ee84dff99a2dd6b65a8f2bf");
ids.add("f342070ea2964a8188e8cdb8379be5c0");
map.put("ids", ids);
List<Blog> blogs = mapper.queryBlogForeach(map);
System.out.println(blogs);
session.close();
}
|
MyBatis 缓存
什么是 MyBatis 缓存
- MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。
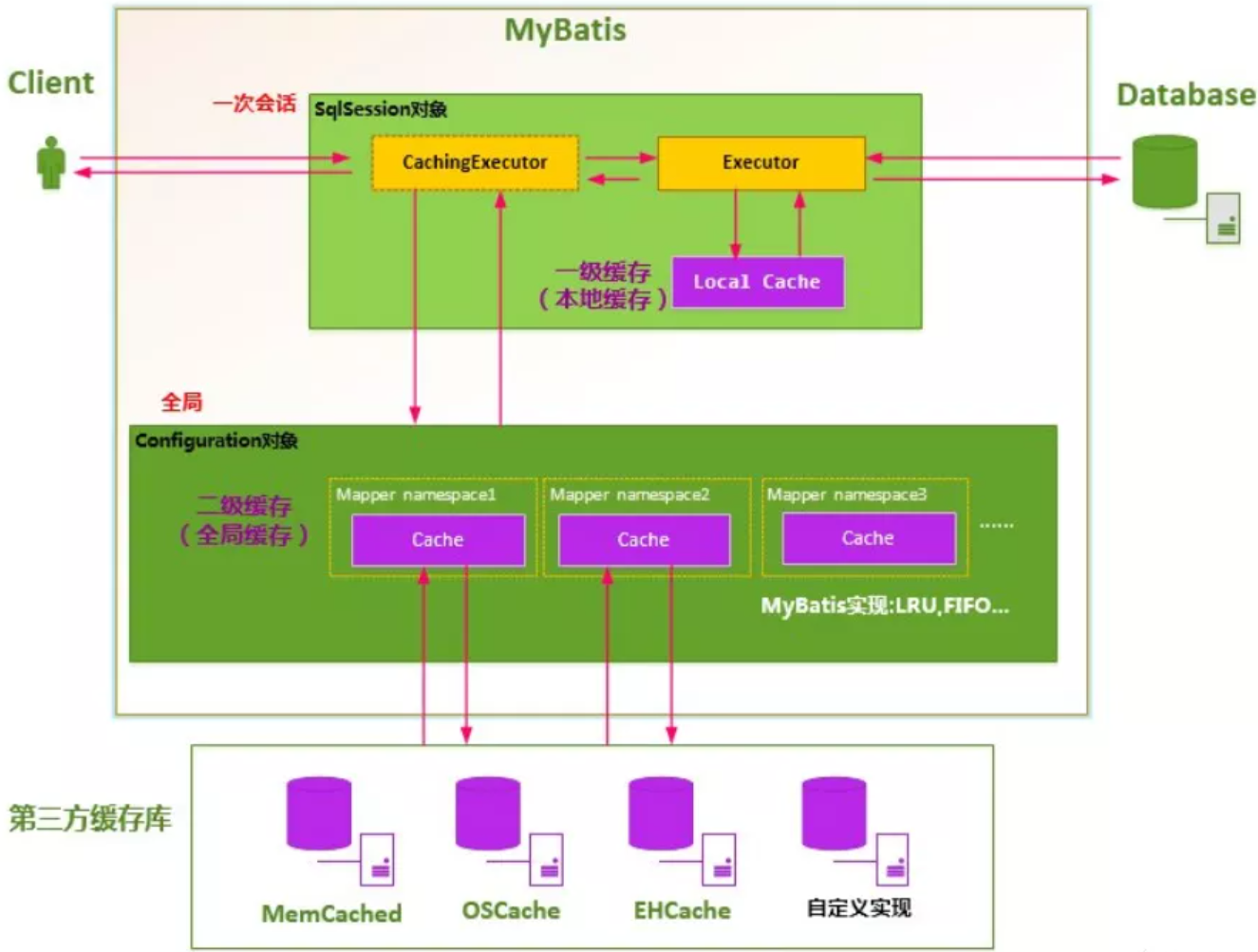
- MyBatis 系统中默认定义了两级缓存:一级缓存和二级缓存
- 默认情况下,只有一级缓存开启。(
SqlSession 级别的缓存,也称为本地缓存) - 二级缓存需要手动开启和配置,他是基于
namespace 级别的缓存 - 为了提高扩展性,MyBatis 定义了缓存接口 Cache。我们可以通过实现 Cache 接口来自定义二级缓存
一级缓存
一级缓存定义
一级缓存也叫本地缓存:
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,没必须再去查询数据库;
一级缓存测试
1
2
| //根据id查询用户
User queryUserById(@Param("id") int id);
|
1
2
3
| <select id="queryUserById" resultType="user">
select * from user where id = #{id}
</select>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Test
public void testQueryUserById() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
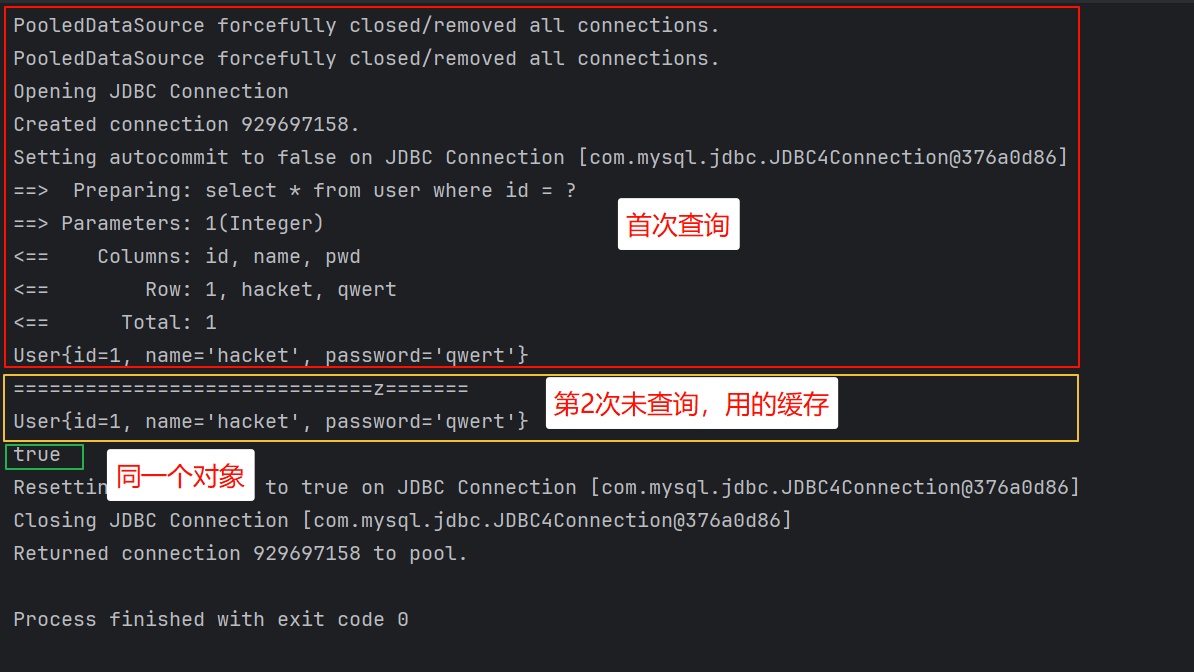
System.out.println("==============================z=======");
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user == user2);
session.close();
}
|
一级缓存失效的 4 种情况
一级缓存是 SqlSession 级别的缓存,是一直开启的,我们关闭不了它;
一级缓存失效情况:没有使用到当前的一级缓存,效果就是,还需要再向数据库中发起一次查询请求
1、sqlSession 不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
SqlSession session2 = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
User user2 = mapper2.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
session2.close();
}
|
结果:发现发送了两条 SQL 语句
结论:每个 sqlSession 中的缓存相互独立
2、sqlSession 相同,查询条件不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
User user2 = mapper2.queryUserById(2);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
|
观察结果:发现发送了两条 SQL 语句
结论:当前缓存中,不存在这个数据
3、sqlSession 相同,两次查询之间执行了增删改操作
1
2
3
4
5
6
| //修改用户
int updateUser(Map map);
<update id="updateUser" parameterType="map">
update user set name = #{name} where id = #{id}
</update>
|
测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
HashMap map = new HashMap();
map.put("name","kuangshen");
map.put("id",4);
mapper.updateUser(map);
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
|
观察结果:查询在中间执行了增删改操作后,重新执行了
观察结果:查询在中间执行了增删改操作后,重新执行了
4、sqlSession 相同,手动清除一级缓存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
session.clearCache();//手动清除缓存
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
|
一级缓存就是一个 map
二级缓存
二级缓存定义
- 二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
- 基于 namespace 级别的缓存,一个名称空间,对应一个二级缓存;
二级缓存工作机制:
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
- 如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中;
- 新的会话查询信息,就可以从二级缓存中获取内容;
- 不同的 mapper 查出的数据会放在自己对应的缓存(map)中;
二级缓存使用
- 开启全局缓存 【
mybatis-config.xml】
1
2
3
4
5
6
7
8
9
10
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--开启全局缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
</configuration>
|
- 去每个 mapper.xml 中配置使用二级缓存,这个配置非常简单;【xxxMapper.xml】
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="me.hacket.mapper.UserMapper">
<cache/>
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
</mapper>
|
- 第 1 种是默认的缓存
- 第 2 种这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Test
public void testQueryUserByIdCache2(){
SqlSession session = MybatisUtils.getSession();
SqlSession session2 = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
session.close();
User user2 = mapper2.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session2.close();
}
|
缓存小结
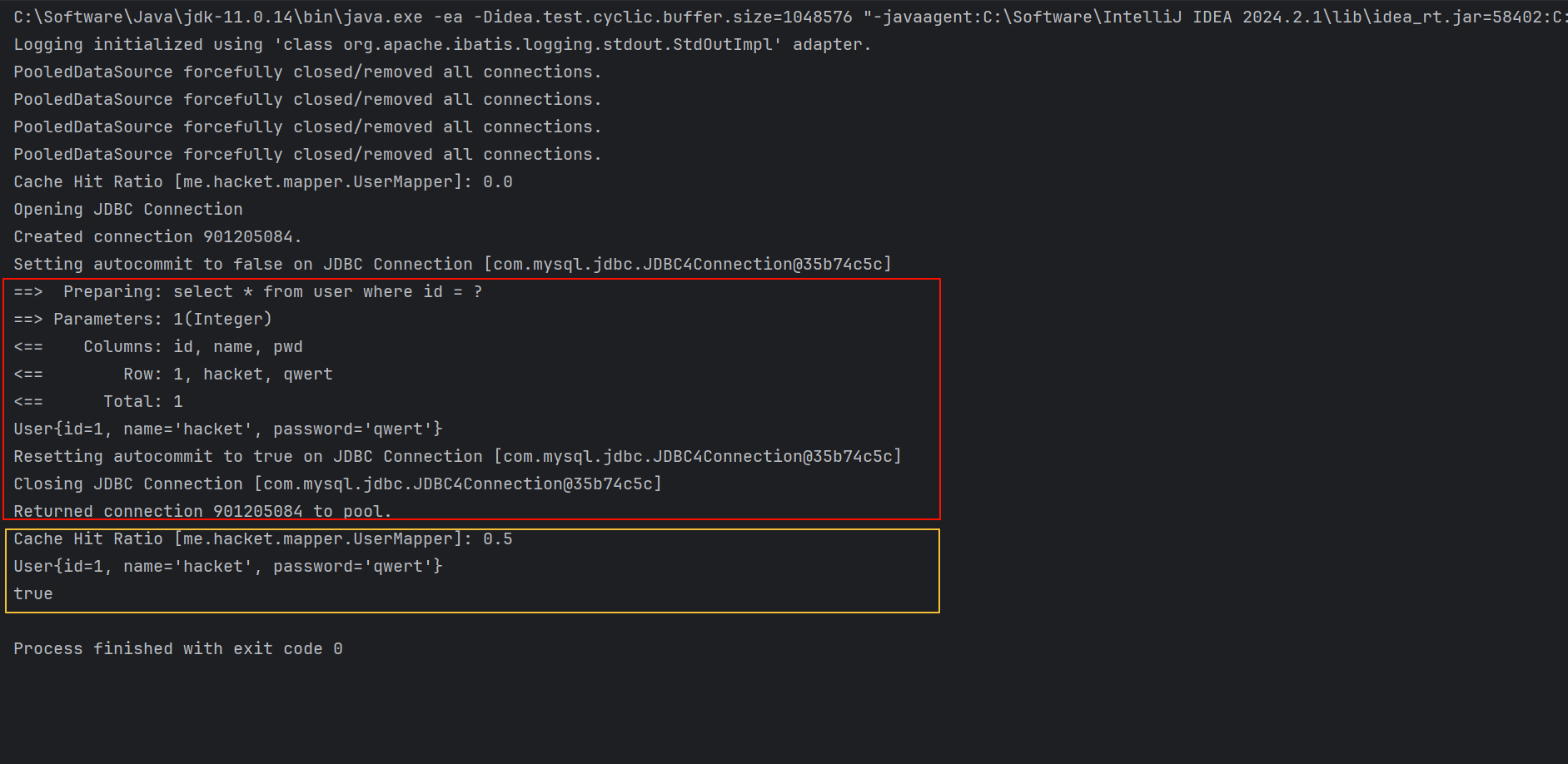
- 只要开启了二级缓存,我们在同一个 Mapper 中的查询,可以在二级缓存中拿到数据
- 查出的数据都会被默认先放在一级缓存中
- 只有会话提交或者关闭以后,一级缓存中的数据才会转到二级缓存中
- 合理的使用缓存,可以让我们程序的性能大大提升
缓存原理图
三方缓存
EHCache
Ehcache 是一种广泛使用的 Java 分布式缓存,用于通用缓存;