03.C++数组
C++ 原始数组
C++ 数组概述
- C++ 数组就是表示一堆的变量组成的集合,一般是一行相同类型的变量。
- 是一段连续的内存
- 内存访问违规(
Memory access violation):在 debug 模式下,你会得到一个程序崩溃的错误消息,来帮助你调试那些问题;然而在 release 模式下,你可能不会得到报错信息。这意味着你已经写入了不属于你的内存。
1
2
3
4
// 定义一个含5个整数的数组
int a[5];
// 访问
a[5],a[-1]; // 内存访问违规(Memory access violation)
- 循环的时候涉及到性能问题,我们一般是小于比较而不是小于等于(少一次等于的判断)。
1
2
3
4
5
6
7
8
9
10
11
12
int main()
{
int example[5];
int* ptr = example;
for (int i = 0; i< 5;i++) //5个元素全部设置为2
example[i] = 2;
example[2] = 5; //第三个元素设置为5
*(ptr + 2) = 6; //第三个元素设置为6。因为它会根据数据类型来计算实际的字节数,所以在这里因为这个指针是整形指针所以会是加上2乘以4,因为每个整形是4字节
*(int*)((char*)ptr + 8) = 7; //第三个元素设置为5。因为每个char只占一个字节
std::cin.get();
}
一维数组
一维数组定义的三种方式:
数据类型 数组名[ 数组长度 ];数据类型 数组名[ 数组长度 ] = { 值1,值2 …};数据类型 数组名[ ] = { 值1,值2 …};
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
int main() {
//定义方式1
//数据类型 数组名[元素个数];
int score[10];
//利用下标赋值
score[0] = 100;
score[1] = 99;
score[2] = 85;
//利用下标输出
cout << score[0] << endl;
cout << score[1] << endl;
cout << score[2] << endl;
//第二种定义方式
//数据类型 数组名[元素个数] = {值1,值2 ,值3 ...};
//如果{}内不足10个数据,剩余数据用0补全
int score2[10] = { 100, 90,80,70,60,50,40,30,20,10 };
//逐个输出
//cout << score2[0] << endl;
//cout << score2[1] << endl;
//一个一个输出太麻烦,因此可以利用循环进行输出
for (int i = 0; i < 10; i++)
{
cout << score2[i] << endl;
}
//定义方式3
//数据类型 数组名[] = {值1,值2 ,值3 ...};
int score3[] = { 100,90,80,70,60,50,40,30,20,10 };
for (int i = 0; i < 10; i++)
{
cout << score3[i] << endl;
}
system("pause");
return 0;
}
栈数组和堆数组
- 不能把栈上分配的数组(字符串)作为返回值,除非你传入的参数是一个内存地址。
- 如果你想返回的是在函数内新创建的数组,那你就要用
new关键字来创建;或者static修饰? - 栈数组
int example[5];堆数组int* another = new int[5];
1
2
3
4
5
6
7
8
9
10
11
int main()
{
int example[5]; //这个是创建在栈上的,它会在跳出这个作用域时被销毁
for (int i = 0; i< 5;i++) //5个元素全部设置为2
example[i] = 2;
int* another = new int[5];//这行代码和之前的是同一个意思,但是它们的生存期是不同的.因为这个是创建在堆上的,实际上它会一直存活到直到我们把它销毁或者程序结束。所以你需要用delete关键字来删除它。
for (int i = 0; i< 5;i++) //5个元素全部设置为2
another[i] = 2;
delete[] another;
std::cin.get();
}
上述的两个数组在内存上看都是一样的,元素都是 5 个 2; 那为什么要使用 new 关键字来动态分配,而不是在栈上创建它们呢?最大的原因是因为生存期,因为 new 分配的内存,会一直存在,直到你手动删除它。 如果你有个函数要返回新创建的数组,那么你必须要使用 new 来分配,除非你传入的参数是一个内存地址。
memory indirection(内存间接寻址)
有个指针,指针指向另一个保存着我们实际数组的内存块(p-> p->array),这会产生一些内存碎片和缓存丢失。
待完善
C++ 多纬数组
二维数组
二维数组定义的四种方式:
数据类型 数组名[ 行数 ][ 列数 ];数据类型 数组名[ 行数 ][ 列数 ] = { {数据1,数据2 } ,{数据3,数据4 } };数据类型 数组名[ 行数 ][ 列数 ] = { 数据1,数据2,数据3,数据4};数据类型 数组名[ ][ 列数 ] = { 数据1,数据2,数据3,数据4};
建议:以上 4 种定义方式,利用==第二种更加直观,提高代码的可读性==
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
int main() {
//方式1
//数组类型 数组名 [行数][列数]
int arr[2][3];
arr[0][0] = 1;
arr[0][1] = 2;
arr[0][2] = 3;
arr[1][0] = 4;
arr[1][1] = 5;
arr[1][2] = 6;
for (int i = 0; i < 2; i++)
{
for (int j = 0; j < 3; j++)
{
cout << arr[i][j] << " ";
}
cout << endl;
}
//方式2
//数据类型 数组名[行数][列数] = { {数据1,数据2 } ,{数据3,数据4 } };
int arr2[2][3] =
{
{1,2,3},
{4,5,6}
};
//方式3
//数据类型 数组名[行数][列数] = { 数据1,数据2 ,数据3,数据4 };
int arr3[2][3] = { 1,2,3,4,5,6 };
//方式4
//数据类型 数组名[][列数] = { 数据1,数据2 ,数据3,数据4 };
int arr4[][3] = { 1,2,3,4,5,6 };
system("pause");
return 0;
}
二维数组转一维
数组优化的一个方法:把二维数组转化成一维数组来进行存储。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
//代码参考来源:https://github.com/UrsoCN/NotesofCherno/blob/main/Cherno64.cpp
#include <iostream>
#include <array>
int main()
{
// 要知道,这样处理数组的数组,会造成内存碎片的问题
// 我们创建了5个单独的缓冲区,每个缓冲区有5个整数,他们会被分配到内存的随机(空闲)位置
// 在大量调用时,很可能造成cache miss,损失性能
int *array = new int[5];
int **a2d = new int *[5]; // 5个int指针
for (int i = 0; i < 5; i++)
a2d[i] = new int[5]; // allocate the memory
for (int y = 0; y < 5; y++)
{
for (int x = 0; x < 5; x++)
{
a2d[y][x] = 2;
}
}
// int ***a3d = new int **[5]; // 5个int指针的指针 三维数组
// for (int i = 0; i < 5; i++)
// {
// a3d[i] = new int *[5];
// for (int j = 0; j < 5; j++)
// {
// // int **ptr = a3d[i];
// // ptr[j] = new int[5];
// a3d[i][j] = new int[5];
// }
// }
for (int i = 0; i < 5; i++) // 需要先释放真正的多维数组
delete[] a2d[i];
delete[] a2d;
// 这只会释放5个指针的内存,而后面分配的内存由于丢失掉了这些指针,
// 也无法释放了,这就造成了内存泄漏
int *array = new int[6 * 5]; //二维
// for (int i = 0; i < 6 * 5; i++)
// {
// array[i] = 2;
// }
for (int y = 0; y < 5; y++) //数组优化,将二维数组转化为一维数组
{
for (int x = 0; x < 6; x++)
{
array[y * 5 + x] = 2;
}
}
std::cin.get();
}
其他
数组无法作为函数的返回值
在 C++ 中,函数是不能直接返回一个数组的,但是你可以通过以下两种方式实现:
- 返回指针:数组其实就是指针,所以可以让函数返回指针来实现。例如:
1
2
3
4
int* returnArray() {
static int arr[3] = {1, 2, 3};
return arr;
}
这里需要注意的是,数组必须是静态的,否则在函数结束时数组会被销毁,返回的指针将指向一个无效的内存区域。
示例:
头文件 ArrayDemo.h:
1
2
3
4
5
6
7
#pragma once
#include <iostream>
class ArrayDemo
{
public:
int* test();
};
cpp文件:ArrayDemo.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include "ArrayDemo.h"
#include <iostream>
int* ArrayDemo::test() {
// int example[5]; //这个是创建在栈上的,它会在跳出这个作用域时被销毁
static int example[5];
for (int i = 0; i < 5; i++) //5个元素全部设置为2
example[i] = 2;
int* another = new int[5];//这行代码和之前的是同一个意思,但是它们的生存期是不同的.因为这个是创建在堆上的,实际上它会一直存活到直到我们把它销毁或者程序结束。所以你需要用delete关键字来删除它。
for (int i = 0; i < 5; i++) //5个元素全部设置为2
another[i] = 2;
delete[] another;
//std::cin.get();
return example;
}
// 上述的两个数组在内存上看都是一样的,元素都是5个2;
// 那为什么要使用new关键字来动态分配,而不是在栈上创建它们呢?最大的原因是因为生存期,因为new分配的内存,会一直存在,直到你手动删除它;或者使用static修饰
// 如果你有个函数要返回新创建的数组,那么你必须要使用new来分配,除非你传入的参数是一个内存地址。
main.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include "ArrayDemo.h"
#include <iostream>
using namespace std;
int main()
{
ArrayDemo* arrayDemo = new ArrayDemo();
int* array = arrayDemo->test();
for (size_t i = 0; i < 5; i++)
{
std::cout << array[i] << endl;
}
std::cin.get();
}
// 输出
// 2
// 32764
// 125499296
// 62
// 1678801228
// 分析:example在test()函数执行完毕就释放了
// 解决:example需要用static修饰,将example数组生命周期提升到整个程序
- 返回数组的类:定义一个包含数组的类,然后让函数返回这个类的对象。例如:
1
2
3
4
5
6
7
8
9
10
11
12
class Array {
public:
int arr[3];
};
Array returnArray() {
Array a;
a.arr[0] = 1;
a.arr[1] = 2;
a.arr[2] = 3;
return a;
}
获取数组指针大小
在 C++ 中,如果你有一个指针 p 指向一个数组的首地址,你无法直接通过这个指针获取数组的大小。因为在 C++ 中,指针并不知道它所指向的数组的大小,sizeof(p) 只能得到指针本身的大小,而不是它指向的数组的大小。例如:
1
2
int arr[] = {1, 2, 3, 4, 5};
int len = sizeof(arr) / sizeof(int); // 计算数组的长度
- 栈数组:
1
2
3
4
5
void test() {
int a[5]; //栈数组
// 如果你想知道有多少个元素,可以用sizeof(a)除以数据类型int的大小,得到5
int count = sizeof(a) / sizeof(int); //5
}
- 堆数组
1
2
int* example = new int[5]; //堆数组
int count = sizeof(example) / sizeof(int); //1
这里得到的实际上是一个整形指针的大小(int* example),就是 4 字节,4/4 就是 1。
所以只能在栈分配的数组上用这个技巧,但是你真的不能相信这个方法!当你把它放在函数或者它变成了指针,那你完蛋了(因为 “栈上的地址加上偏移量“**)。所以你要做的就是自己维护数组的大小。
如何维护呢?方法有两个:
方法一:
1
2
3
4
5
6
7
8
9
10
11
class Entity
{
public:
static constexpr const int size = 5;//在栈中为数组申请内存时,它必须是一个编译时就需要知道的常量。constexpr可省略,但类中的常量表达式必须时静态的
int example[size]; //此时为栈数组,
Entity()
{
for (int i = 0; i<size;i++)
example[i] = 2;
}
};
方法二:std:array
1
2
3
4
5
6
7
8
9
10
11
include <array> //添加头文件
class Entity
{
public:
std::array<int,5> another; //使用std::array
Entity()
{
for (int i = 0; i< another.size();i++) //调用another.size()
example[i] = 2;
}
};
这个方法会安全一些。
C++ 动态数组 std::vector
std::vector 基本使用
vector本质上是一个动态数组,是内存连续的数组- 它的使用需要包含头文件
#include <vector> - 使用格式:
1
2
// 类型尽量使用对象而非指针。
std::vector<T> a;//T是一种模板类型,尽量使用对象而非指针
- 添加元素
1
2
3
4
5
6
7
8
9
10
11
a.push_back(element); // 后面插入
//定义一个类
struct Vertex
{
float x, y, x;
}
std::vector<Vertex> vertices; //定义一个Vertex类型的动态数组
vertices.push_back({ 1, 2, 3 });//列表初始化(结构体或者类,可以按成员声明的顺序用列表构造)
vertices.push_back({ 4, 5, 6 });//同:vertices.push_back(Vertex(4, 5, 6)
vertices.push_back({ 7, 8, 9 });
- 遍历
1
2
3
4
5
6
7
8
9
10
// for遍历
for(int i =0; i < vertices.size();i++)
{
std::cout << vertices[i] << std::endl;
}
// 范围for循环遍历
for(Vertex& v : vertices) //引用,避免复制浪费。
{
std::cout << v << std::endl;
}
- 清除数组列表
1
vertices.clear();
- 清除指定元素
1
2
// 例如:清除第二个元素
vertices.erase(vertices.begin()+1) //参数是迭代器类型
- 参数传递时,如果不对数组进行修改,请使用引用类型传参。
1
void Function(const std::vector<T>& vec){};
std::vector 扩容机制
往 vector 中添加元素时,如果空间不够将会导致扩容。vector 有两个属性:size 和 capacity。size 表示已经使用的数据容量,capacity 表示数组的实际容量,包含已使用的和未使用的。
vector 扩容规则:
- 1)新增元素:vector 通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素;
- 2)对 vector 的任何操作,一旦引起空间重新配置,指向原 vector 的所有迭代器就都失效了;
- 3)初始时刻 vector 的 capacity 为 0,插入第一个元素后 capacity 增加为 1;
- 4)不同的编译器实现的扩容方式不一样,VS2015 中以 1.5 倍扩容,GCC 以 2 倍扩容。
总结
1)vector 在 push_back 以成倍增长可以在均摊后达到 O(1) 的事件复杂度,相对于增长指定大小的 _ O(n) _ 时间复杂度更好。
2)为了防止申请内存的浪费,现在使用较多的有 2 倍与 1.5 倍的增长方式,而 1.5 倍的增长方式可以更好的实现对内存的重复利用,因而更好。
std::vector 使用优化
vecctor 的优化策略
- 问题 1
当向 vector 数组中添加新元素时,为了扩充容量,当前的 vector 的内容会从内存中的旧位置复制到内存中的新位置(产生一次复制),然后删除旧位置的内存。简单说,push_back 时,容量不够,会自动调整大小,重新分配内存。这就是将代码拖慢的原因之一。
解决办法: vertices.reserve(n) ,直接指定容量大小,避免重复分配产生的复制浪费。
- 问题 2:
在非 vector 内存中创建对象进行初始化时,即 push_back() 向容器尾部添加元素时,首先会创建一个临时容器对象(不在已经分配好内存的 vector 中)并对其追加元素,然后再将这个对象拷贝或者移动到【我们真正想添加元素的容器】中 。这其中,就造成了一次复制浪费。
解决办法: emplace_back,直接在容器尾部创建元素,即直接在已经分配好内存的那个容器中直接添加元素,不创建临时对象。
简单的说:
reserve 提前申请内存,避免动态申请开销 emplace_back 直接在容器尾部创建元素,省略拷贝或移动过程
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include "VectorDemo.h"
#include <iostream>
#include <vector>
struct Vertex
{
float x, y, z;
Vertex(float x, float y, float z)
: x(x), y(y), z(z)
{
}
Vertex(const Vertex& vertex)
: x(vertex.x), y(vertex.y), z(vertex.z)
{
std::cout << "Copied!" << std::endl;
}
};
void VectorDemo::testVector()
{
std::vector<Vertex> vertices;
vertices.push_back(Vertex(1, 2, 3)); //同vertices.push_back({ 1, 2, 3 });
vertices.push_back(Vertex(4, 5, 6));
vertices.push_back(Vertex(7, 8, 9));
std::cin.get();
}
// 输出
// Copied!
// Copied!
// Copied!
// Copied!
// Copied!
// Copied!
发生六次复制的原因:
vector 扩容因子为 1.5,初始的 capacity 为 0. 第一次 push_back,capacity 扩容到 1,临时对象拷贝到真正的 vertices 所占内存中,第一次 Copied;第二次 push_back,发生扩容,capacity 扩容到 2,vertices 发生内存搬移发生的拷贝为第二次 Copied,然后再是临时对象的搬移,为第三次 Copied;接着第三次 push_back,capacity 扩容到 3(
2*1.5 = 3,3 之后是 4,4 之后是 6…),vertices 发生内存搬移发生的拷贝为第四和第五个 Copied,然后再是临时对象的搬移为第六个 Copied;
或者:
1
2
3
4
5
6
7
8
9
std::vector<Entity> e;
Entity data1 = { 1,2,3 };
e.push_back( data1); // data1->新vector内存
Entity data2 = { 1,2,3 };
e.push_back( data2 ); //data1->新vector内存 data2->vector新vector内存 删除旧vector内存
Entity data3 = { 1,2,3 };
e.push_back(data3); // data1->新vector内存 data2->vector新vector内存 data3->vector新vector内存 删除旧vector内存
所以他的输出的次数分别是1,3,6
他的复制次数你可以这样理解递增。 1+2+3+4+5+....
解决:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
int main()
{
std::vector<Vertex> vertices;
//ver 1 : copy 6 times
vertices.push_back({ 1,2,3 });
vertices.push_back({ 4,5,6 });
vertices.push_back({ 7,8,9 });
//ver 2 : copy 3 times
vertices.reserve(3);
vertices.push_back({ 1,2,3 });
vertices.push_back({ 4,5,6 });
vertices.push_back({ 7,8,9 });
//ver 3 : copy 0 times
vertices.reserve(3);
vertices.emplace_back(1, 2, 3);
vertices.emplace_back(4, 5, 6);
vertices.emplace_back(7, 8, 9);
std::cin.get();
}
C++ 静态数组 std::array
std::array 是 C++ 标准模板库(STL)的一部分,它是一个固定大小的容器,其中存储的元素数量在编译时就已确定。std:: array 以静态数组的形式存在,因此,它的大小必须在编译时已知,并且在其整个生命周期内都不会改变。
std::array 提供了类似于其他标准容器(如 std::vector 和 std::list)的接口,包括迭代器、元素访问、容量查询和其他常用操作。它封装了原生数组的操作,同时提供了类型安全和更现代化的接口, std::array 的一些特点:
- 固定大小:与
std::vector不同,std::array的大小在创建后不能更改。 - 栈分配:
std::array默认在栈上分配内存,而不是在堆上,性能好点。和原生数组一样 - 性能:由于其固定大小和栈分配的特性,
std::array在性能上往往优于std::vector,特别是对于小型数组。 - 支持的操作:
std::array支持元素访问、迭代器、容量查询、填充、交换两个数组的内容等操作。 - 原生数组越界的时候不会报错,而
std::array会有越界检查,会报错提醒。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include "StdArrayDemo.h"
#include <array>
#include <iostream>
#include <algorithm>
void StdArrayDemo::testStdArray()
{
std::array<int, 5> data;
data[0] = 1;
data[4] = 10;
//data[10] = 100; // 越界
// 创建一个 std::array 实例,其中包含3个整数
std::array<int, 3> arr = { 1, 2, 3 };
// 访问元素
std::cout << "First element: " << arr[0] << std::endl;
// 使用范围基于的循环迭代
for (auto& el : arr) {
std::cout << el << " ";
}
// 获取数组大小
std::cout << "nArray size: " << arr.size() << std::endl;
// 直接对 std::array 进行排序
std::sort(arr.begin(), arr.end());
}
如何传入一个标准数组作为参数,但不知道数组的大小?
答案:使用模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
#include <array>
#include <iostream>
#include <algorithm>
#include <typeinfo>
using namespace std;
template<typename T>
void printarray(/*const*/ T data) {
// 传递进来的参数会复制给data,造成性能差
for (size_t i = 0; i < data.size(); i++) {
cout << data[i] << ",";
}
// 如果data 用const T修饰就不能修改了
data[0] = 10000;
data[1] = 100;
// 因为data是复制过来的,所以是值传递,修改的是复制后的data,原数组不变
cout << endl;
}
template<typename T>
void printarray1(/*const*/ T& data) { // 传递引用
// 与 printarray 类似,但它改用常量引用来传递参数。这样就不会发生复制,而是直接使用原始容器的引用。
for (size_t i = 0; i < data.size(); i++) {
cout << data[i] << ",";
}
// 如果data 用const T&修饰就不能修改了
data[0] = 10001;
data[1] = 101;
// 用的是原数组的引用,可以修改原数组
cout << endl;
}
template<typename T, unsigned long N>
void printarray2(/*const*/ std::array<T, N>& data) {
// 引用传递,没有复制
for (size_t i = 0; i < N; i++)
{
cout << data[i] << " ";
}
// 如果data 用const std::array<T, N>& data修饰就不能修改了
data[0] = 10002;
data[1] = 102;
// 用的是原数组的引用,可以修改原数组
cout << endl;
}
template<typename T, unsigned long N>
void printarray3(/*const*/ std::array<T, N> data) {
// 传递进来的参数会复制给data,造成性能差
for (size_t i = 0; i < N; i++)
{
cout << data[i] << " ";
}
// 如果data 用const std::array<T, N>修饰就不能修改了
data[0] = 10003;
data[1] = 103;
// 因为data是复制过来的,所以是值传递,修改的是复制后的data,原数组不变
cout << endl;
}
// 指针方式
template<typename T>
void printarray4(/*const*/ T* d) {
T data = *d; // 解引用,会复制给data
for (size_t i = 0; i < data.size(); i++) {
cout << data[i] << ",";
}
// 如果data 用const T修饰就不能修改了
/*data[0] = 10004;
data[1] = 104;*/
// 非法的间接寻址
/**d[0] = 10004;
*d[1] = 104;*/
// 因为data是复制过来的,所以是值传递,修改的是复制后的data,原数组不变
/*d[0] = 10004;
d[1] = 104;*/
cout << endl;
}
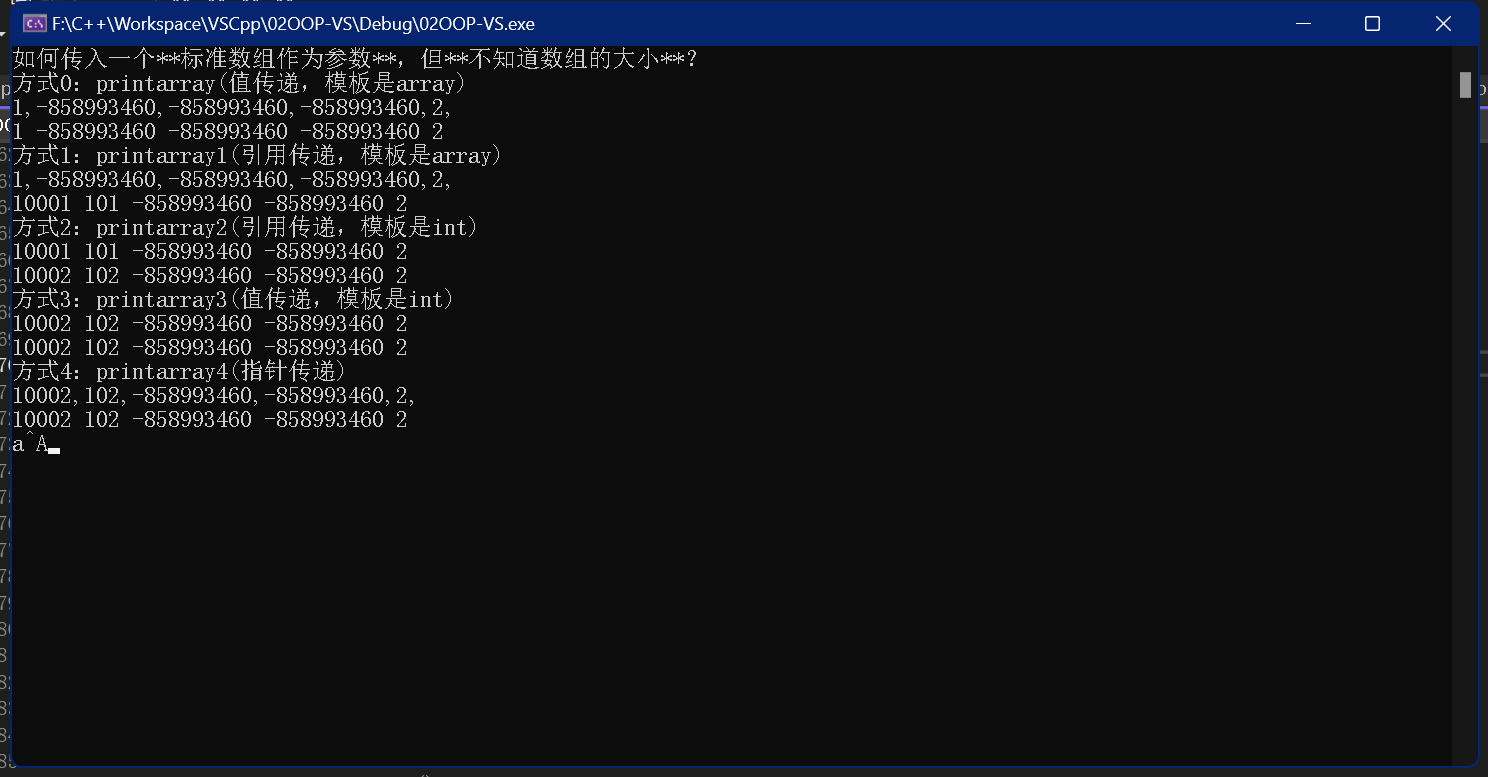
void StdArrayDemo::testStdArray()
{
cout << "如何传入一个**标准数组作为参数**,但**不知道数组的大小**?" << endl;
std::array<int, 5> data1;
data1[0] = 1;
data1[4] = 2;
cout << "方式0:printarray(值传递,模板是array)" << endl;
printarray<std::array<int,5>>(data1);
for (auto& el : data1) {
cout << el << " ";
}
cout << endl;
cout << "方式1:printarray1(引用传递,模板是array)" << endl;
printarray1<std::array<int, 5>>(data1);
for (auto& el : data1) {
cout << el << " ";
}
cout << endl;
cout << "方式2:printarray2(引用传递,模板是int)" << endl;
printarray2<int,5>(data1);
for (auto& el : data1) {
cout << el << " ";
}
cout << endl;
cout << "方式3:printarray3(值传递,模板是int)" << endl;
printarray3<int,5>(data1);
for (auto& el : data1) {
cout << el << " ";
}
cout << endl;
cout << "方式4:printarray4(指针传递)" << endl;
printarray4<std::array<int, 5>>(&data1);
for (auto& el : data1) {
cout << el << " ";
}
cout << endl;
}
|  |