03 Python字符串
03 Python 字符串
Python 3 版本中,字符串是以 Unicode 编码的,也就是说,Python 的字符串支持多语言。
字符串表示
字符串是以 '' 或 "" 括起来的任意文本,比如 ‘abc’,”xyz” 等等。请注意,’’ 或 “” 本身只是一种表示方式,不是字符串的一部分,因此,字符串 ‘abc’ 只有 a,b,c 这 3 个字符。
普通字符串 '' 或 ""
''或者""表示- 字符串包含
'或"用\转义
转义符 \
在字符串中使用\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义。
\n不是代表反斜杠和字符 n,而是表示换行;\t也不是代表反斜杠和字符 t,而是表示制表符- 在字符串中表示
'要写成\',同理想表示\要写成\\ - 在\后面还可以跟一个八进制或者十六进制数来表示字符:
\141和\x61都代表小写字母 a - 也可以在\后面跟 Unicode 字符编码来表示字符
1
2
3
s1 = '\141\142\143\x61\x62\x63'
s2 = '\u9a81\u660b'
print(s1, s2) # abcabc 骁昋
- 如果不希望字符串中的\表示转义,我们可以通过在字符串的最前面加上字母
r来加以说明
1
2
3
s1 = r'\'hello, world!\''
s2 = r'\n\\hello, world!\\\n'
print(s1, s2, end='') # 原本输出\
raw 字符串 r''
如果一个字符串包含很多需要转义的字符,对每一个字符都进行转义会很麻烦。为了避免这种情况,我们可以在字符串前面加个前缀 r ,表示这是一个 raw 字符串,里面的字符就不需要转义了
1
print r'\(~_~)/ \(~_~)/'
r'xxx',表示法不能表示多行字符串。
多行字符串 ''' ''' 或 """ """
用 '''xxx''',里面可以包含 ' 和 "
1
2
3
'''Line 1
Line 2
Line 3'''
还可以在多行字符串前面添加 r,把这个多行字符串也变成一个 raw 字符串:
1
2
3
print r'''Python is created by "Guido".
It is free and easy to learn.
Let's start learn Python in imooc!'''
Python 中 Unicode 字符串
背景计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用 8 个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是 255(二进制 11111111=十进制 255),0 - 255 被用来表示大小写英文字母、数字和一些符号,这个编码表被称为 ASCII 编码,比如大写字母 A 的编码是 65,小写字母 z 的编码是 122。 如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和 ASCII 编码冲突,所以,中国制定了 GB2312 编码,用来把中文编进去。 类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode 应运而生。Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode 通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为 0 就可以。
因为 Python 的诞生比 Unicode 标准发布的时间还要早,所以最早的 Python 只支持 ASCII 编码,普通的字符串 ABC 在 Python 内部都是 ASCII 编码的。
Python 在后来添加了对 Unicode 的支持,以 Unicode 表示的字符串用 u'…' 表示
1
2
print(u'中文\'')
# 中文'
多行:
1
2
print u'''第一行
... 第二行'''
raw+ 多行:
1
2
3
print ur'''Python的Unicode字符串支持"中文",
... "日文",
... "韩文"等多种语言'''
py 源码中有中文
如果中文字符串在 Python 环境下遇到 UnicodeDecodeError,这是因为.py 文件保存的编码格式有问题。
由于 Python 源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为 UTF-8 编码。当 Python 解释器读取源代码时,为了让它按 UTF-8 编码读取,我们通常在文件开头写上这两行:
1
2
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
- 第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序,Windows 系统会忽略这个注释;
- 第二行注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了 UTF-8 编码并不意味着你的.py 文件就是 UTF-8 编码的,必须并且要确保文本编辑器正在使用 UTF-8 without BOM 编码: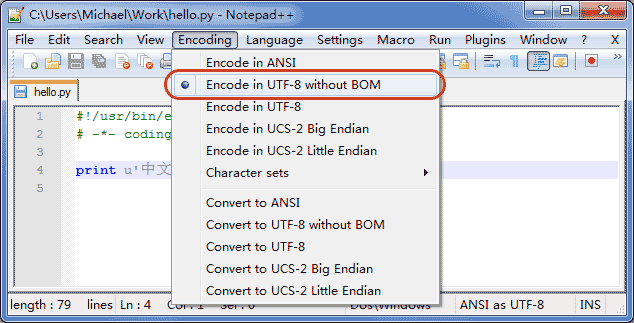
如果.py 文件本身使用 UTF-8 编码保存,并且也申明了 # -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
格式化
%
% 运算符就是用来格式化字符串的。在字符串内部,%s 表示用字符串替换,%d 表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
%d | 整数 |
%f | 浮点数 |
%s | 字符串 |
%x | 十六进制整数 |
格式化整数和浮点数还可以指定是否补 0 和整数与小数的位数:
1
2
3
4
5
print('[%2d, %03d]' % (3, 1))
# 第1个数字保留2位,第2个数字保留3位,不足3位用0补上:[ 3, 001]
print('[%.2f]' % 3.1415926)
# 小数点后保留2位:[3.14]
%s 永远起作用,它会把任何数据类型转换为字符串:
1
2
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
format()
字符串的 format() 方法,它会用传入的参数依次替换字符串内的占位符 {0}、{1}……,不过这种方式写起来比% 要麻烦得多
1
2
print('Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125))
# Hello, 小明, 成绩提升了 17.1%
f-string
Python 3.6 以后,格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母 f;格式化字符串的方法是使用以 f 开头的字符串,称之为 f-string,它和普通字符串不同之处在于,字符串如果包含 {xxx},就会以对应的变量替换
1
2
3
4
r = 2.5
s = 3.14 * r ** 2
print(f'The area of a circle with radius {r} is {s:.2f}')
# The area of a circle with radius 2.5 is 19.62
{r}被变量 r 的值替换,{s:.2f}被变量 s 的值替换,并且: 后面的.2f 指定了格式化参数(即保留两位小数),因此,{s:.2f}的替换结果是 19.62。
字符串操作
运算符
+运算符来实现字符串的拼接*运算符来重复一个字符串的内容- 使用
in和not in来判断一个字符串是否包含另外一个字符串(成员运算) - 可以用
[]和[:]运算符从字符串取出某个字符或某些字符(切片运算)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
s1 = 'hello ' * 3
print(s1) # hello hello hello
s2 = 'world'
s1 += s2
print(s1) # hello hello hello world
print('ll' in s1) # True
print('good' in s1) # False
str2 = 'abc123456'
# 从字符串中取出指定位置的字符(下标运算)
print(str2[2]) # c
# 字符串切片(从指定的开始索引到指定的结束索引)
print(str2[2:5]) # c12
print(str2[2:]) # c123456
print(str2[2::2]) # c246
print(str2[::2]) # ac246
print(str2[::-1]) # 654321cba
print(str2[-3:-1]) # 45
字符串方法
- len(str) 字符串长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
str1 = 'hello, world!'
# 通过内置函数len计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串每个单词首字母大写的拷贝
print(str1.title()) # Hello, World!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' hacket@gmail.com '
print(str3)
# 获得字符串修剪左右两侧空格之后的拷贝
print(str3.strip())