数据库基础
RDBMS 术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列 (数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
如 MySQL 为关系型数据库 (Relational Database Management System), 这种所谓的 “ 关系型 “ 可以理解为 “ 表格 “ 的概念, 一个关系型数据库由一个或数个表格组成, 如图所示的一个表格: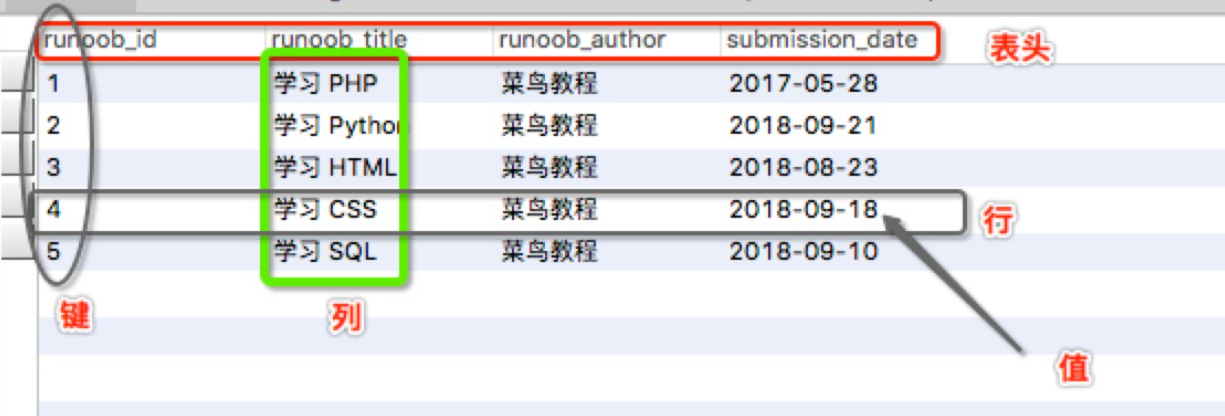
- 表头 (header): 每一列的名称;
- 列 (col): 具有相同数据类型的数据的集合;
- 行 (row): 每一行用来描述某条记录的具体信息;
- 值 (value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键 (key): 键的值在当前列中具有唯一性。
索引
什么是索引?
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。索引的实现通常使用 B 树或变种的 B+ 树。
索引的优缺点?
优点
- 通过创建索引,可以在查询的过程中,提高系统的性能
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 在使用分组和排序进行数据检索时,可以减少查询中分组和排序的时间
缺点
- 创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增大
- 索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大
- 在对表中的数据进行增加删除和修改时需要耗费较多的时间,因为索引也要动态地维护
事务
事务概述
事务是指满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚
什么是 ACID?
- A Atomiccity 原子性
事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚;回滚可以用回滚日志来实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可
- C Consistency 一致性
数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对同一个数据的读取结果都是相同的。
- I Isolation 隔离性
一个事务所做的修改在最终提交之前,对其他事务是不可见的
- D Durability 持久性
- 一旦事务提交,则其所做的修改将会永远保存到数据库中,即使系统发生崩溃,事务执行的结果也不能丢失
- 系统发生崩溃可以用重做日志进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改。
数据库事务正确执行的四个基本要素
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必须要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
- 原子性
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性
一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
其主要特征是保护性和不变性 (Preserving an Invariant),以转账案例为例,假设有五个账户,每个账户余额是 100 元,那么五个账户总额是 500 元,如果在这个 5 个账户之间同时发生多个转账,无论并发多少个,比如在 A 与 B 账户之间转账 5 元,在 C 与 D 账户之间转账 10 元,在 B 与 E 之间转账 15 元,五个账户总额也应该还是 500 元,这就是保护性和不变性。
- 隔离性
如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
- 持久性
在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
数据库范式?
第一范式
第⼀范式就是属性不可分割,每个字段都应该是不可再拆分的。⽐如⼀个字段是姓名(NAME),在国内的话通常理解都是姓名是⼀个不可再拆分的单位,这时候就符合第⼀范式;但是在国外的话还要分为 FIRST NAME 和 LASTNAME,这时候姓名这个字段就是还可以拆分为更⼩的单位的字段,就不符合第⼀范式了
第二范式(主键约束)
第⼆范式就是要求表中要有主键,表中其他其他字段都依赖于主键,因此第二范式只要记住主键约束就好了。
比如说有⼀个表是学⽣表,学⽣表中有⼀个值是唯⼀的字段学号,那么学⽣表中的其他所有字段都可以根据这个学号字段去获取,依赖主键的意思也就是相关的意思,因为学号的值是唯⼀的,因此就不会造成存储的信息对不上的问题,即学⽣ 001 的姓名不会存到学⽣ 002 那⾥去 。
第三范式(外键约束)
第三范式就是要求表中不能有其他表中存在的、存储相同信息的字段,通常实现是通过外键去建⽴关联,因此第三范式只要记住外键约束就好了。
比如说有⼀个表是学⽣表,学⽣表中有学号,姓名等字段,那如果要把他的系编
号,系主任也存到这个学⽣表中,那就会造成数据⼤量冗余,⼀是这些信息在系信息表中已存在,⼆是系中有 1000 个学⽣的话这些信息就要存 1000 遍。因此第三范式的做法是在学⽣表中增加⼀个系编号的字段做外键,与系信息表做关联。
数据库面试题
Sqlite 相关题
我有一个播放列表,可能有上万首歌,支持插入下一首,要求用数据库存储
如何设计这个模块?(2022 年 大宇无限)
- 索引,索引多了插入效率会降低
- 事务: 由于 Sqlite 的数据操作实质上是对于其数据文件的 IO 操作,频繁的插入数据会导致文件 IO 经常开闭,非常损耗性能能。事务作用便是使数据先缓存在系统中,提交事务时便提交所有的更改到数据文件,此时数据文件的 IO 只需要开闭一次,且避免了长期占用文件 IO 所导致性能低下的问题
- 预处理:预处理的原理就是将一条语句先预编译到数据库,下次再次执行相同的语句时,就不用再次编译,节省了大量的时间
- 内存模式